
Time series data is as old as databases themselves – and also the hot new thing. Interest in the topic has more than doubled during this decade. In a previous blog post, we described how time series data is used and stored. In this blog post, we look at the desirable characteristics of a time series database and evaluate our own database, SingleStore, against those requirements.
Time series data is more and more widely used. It’s seen in everything from managing oil drilling rigs to machine learning and AI. Part of the growth comes from the fact that time series data is at the core of the Internet of Things, with frequent sensor readings coming in from all sorts of devices.
Uses of time series data include storage for data from Internet of Things (IoT) devices, such as cars, airplanes, and card readers; for financial services applications, such as stock trading, portfolio management, and risk analysis; for e-commerce and marketing platforms, to manage ads, maintain inventory, and fulfill orders; and, increasingly, in day-to-day business management. Companies need to rapidly ingest original transactional data, use it to instantly trigger responses, and make it available for both real-time and longer-term analytics.
Time series data is so voluminous that one of the first questions you face is whether to store it at all, or some fraction, sample, or summary of it. The right database can make it much easier and cheaper to store more of the data that you need. The right database can also make it easier to query and analyze, which increases the value of the data.
Editor’s Note: Also see our blog post on implementing time series functions with SingleStore. We also have two recorded webinars (from DZone and SingleStore) and an O’Reilly ebook download covering these topics.
Time Series Database Requirements
Here’s an example of time series data from our introductory blog post. This record contains all the readings from a sensor for one specific minute of time. The Values field contains semi-structured JSON data; it can contain from 0 to 60 values, with each item containing the second the data was stored and the value when the recording was made.
| Sensor ID | Date | Time (min) | Values |
|---|---|---|---|
| 4257 | 01012019 | 0113 | [04,233518],[14,233649] |
What are the requirements for a database that stores data recorded as a time series?
- In-memory for value alerting. As data arrives, it has to be compared immediately to any alarm trigger values that have been set. In a pipeline, for instance, a high value for pressure may require urgent action due to the danger of a rupture, and a low value may indicate a problem upstream from the sensor location.
- In-memory for trend alerting. Also, as data arrives, it has to be compared to previous values to see if any trend alarms have been set. For instance, a pipeline may trigger an alert if pressure rises more than 20psi in one minute. This comparison runs much faster if all of the needed records for evaluating the trend are held in memory, or if logic holds relevant high and low values from previous records for comparison purposes.
- In-memory for applications and dashboards. Applications (which act based on data values) and dashboards (which need to display up-to-date values) need live data in memory to support rapid action (for applications) and continual display updates (for dashboards).
- Fast access for real-time analytics, machine learning, and AI. Business intelligence programs, ad hoc queries, reports, machine learning algorithms, and AI programs all need fast responsiveness from the data store. This may require data to be in-memory, heavily cached, or efficiently accessed from a combination of memory and disk.
- High concurrency for real-time analytics. Demand for access to data of all types is growing – and time series data, representing the latest readings, can be among the most valuable data of all. A wide range of people need to be able to access this data at the same time, with no artificial limits as to how many logins are given out or how many queries arrive at once.
- High capacity. A time-series database needs to be both fast and scalable in order to accommodate huge amounts of data – scanning and comparing it on input for alarms, storing it accessibly, and responding robustly to queries against large data sets.
- Standard SQL functions. The SQL standard was promulgated nearly 50 years ago, and has benefited from decades of hard work on defining, widening, and optimizing performance for SQL-standard functionality. This includes academic research and lots of blood, sweat, and tears in implementation, most of which has been shared back and forth across companies. So high performance for SQL functions is a key asset for a time series database.
- Custom time-series functions. Time series data can benefit from functionality that isn’t part of the SQL standard, and that has been optimized for performance. Examples include functions to toss incoming data where a sensor reading hasn’t changed significantly, to return only the records with the lowest and highest readings from a large set of records, etc.
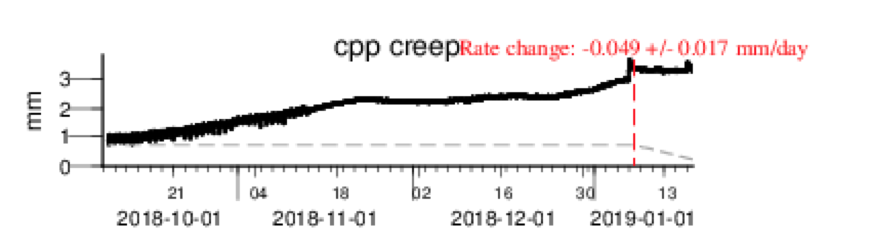
Earthquake fault data, as shown in the figure, is a good example of the demands placed on a time series database. By monitoring specific sensor readings as they come in, geologists may be able to warn of an upcoming quake in time to save lives. Conversely, by finely examining huge amounts of historical fault data, geologists may learn the underlying patterns that enable them to produce future earthquakes and, again, save lives.
Purpose-Built Time Series Databases
The open source movement led to an explosion of creativity in many areas, and databases have seen their share of innovation. Most of this has centered in the NoSQL movement, and most time series databases are based on NoSQL.
These databases show the strengths and weaknesses of the NoSQL movement as a whole. Firstly, it’s easy to create a new NoSQL database. Since most of them are based on open source, a time series database can be easily, and inexpensively, created by adding time series-specific features to an existing NoSQL code base. Time series databases based on NoSQL also benefit from scalability, a key aspect of NoSQL that is lacking in traditional transactional and analytics databases that have SQL support.
However, as the NoSQL name implies, NoSQL databases lack both inherent structure – a key, and valuable, attribute of time series data – and SQL support, making them much harder to query or to use with standard business intelligence (BI) and analytics programs.
The lack of structure causes problems beyond the important, but narrow, issue of SQL support. To query a NoSQL database means carefully examining the schema and writing a custom query against it. Complex operations such as different kinds of joins, which have benefited from decades of innovation on the SQL side, are likely to be slow and even buggy in the NoSQL camp.
To highlight the strengths and weaknesses of these purpose-built time series databases, we can briefly examine four entries that are, each in their own way, a leader in the field:
- Graphite. The oldest time series database that’s still viable, Graphite has a wide range of functions. However, it stagnated for several years, as some open source projects do, before receiving a burst of energy with the recent strong interest in time series data. According to the project’s website, graphite does two things: store numeric time-series data and render graphs of the stored data on demand.
- InfluxDB. The current leader in the time series field, it’s a well-organized project, having fixed early problems with its storage layer. It still has problems with query performance and has recently come up with a new language, IFQL, to address the problem.
- OpenTSDB. OpenTSDB is based on an internal Google monitoring tool called Borgmon. OpenTSDB is highly scalable and has an up-to-date data model; however, you need to create and maintain a Hadoop cluster to run it, meaning that its scalability requires a fair amount of effort on the part of users.
- kdb+. kdb+ is a column-based, largely in-memory database specially designed for time series data that has gained popularity in finance. kdb+ has specific functions for time series data, such as specialized joins that select data around a specific point in time or a specific record.
Time Series Database: Why Choose SingleStore?
SingleStore is a very strong general-purpose database. It’s in the group of databases called NewSQL, which means SQL databases that are scalable to multiple machines – unlike transactional and analytical databases that gave up scalability, while offering structure and SQL support.
SingleStore is among the most mature of the NewSQL offerings; in particular, it’s platform-agnostic, running on all the major public clouds, in virtual machines and containers, and on premises. In addition, it has several features that particularly recommend it for use with time series data. These features include:
Scalable speed
. SingleStore is very fast on a single machine, and you can scale out for performance by adding machines seamlessly to a cluster.
Memory-optimized with on-disk compression
. SingleStore started as an in-memory database, then added columnstore support with on-disk compression, both needed for voluminous time series data.
Pipelines
SingleStore Pipelines apply transformations to data on ingest. They streamline the traditional ETL process into a very fast set of operations, so you can pre-process time series data as needed for analytics.
Pipelines to stored procedures
SingleStore can run streaming data against stored procedures on ingest, expanding the range of operations you can quickly run on incoming data.
SQL support
As mentioned, SingleStore has full ANSI SQL support, with all the advantages this implies for queries, analytics, and machine learning and AI programs which use SQL.
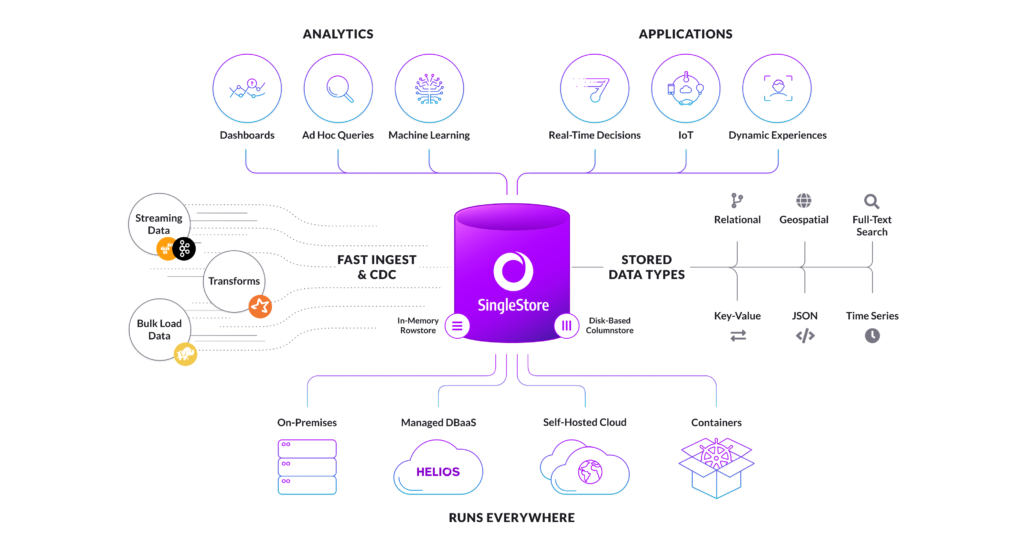
Because SingleStore has specialized functionality for smoothly interacting with data across memory and disk, including large memory caches for columnstore tables and compression that’s high-performance for both reads and writes, the usual strong disparity between in-memory and on-disk performance is greatly reduced with SingleStore. This allows you to use timestore data more flexibly across a range of use cases, from alerting to reporting and predictive analytics.
SingleStore currently lacks some specialized time series functionality. SingleStore does have extra-fast SQL operations and scalability, which can result in better overall query performance and responsiveness than dedicated time series databases. It’s also highly extensible, and has already been extended by SingleStore and specific customers to add time series functionality.
Here are three ways to add needed functionality:
- Create the join you need in ANSI SQL.
- If needed (ie if it will be run repeatedly), optimize it using the query profiler in SingleStore Studio.
- If using SingleStore Pipelines, run the join as a stored procedure tied to a Pipeline.
The table below summarizes pluses and minuses of dedicated time series databases, largely based on NoSQL, vs. SingleStore for time series data.
| Dedicated time series database | SingleStore | |
|---|---|---|
| In-memory support | Strong | Strong |
| Columnstore/compression | Fair | Strong |
| Ingest performance | Varies | Strong |
| SQL support | Poor | Strong |
| Query performance | Poor | Strong |
| Time series-specific optimizations | Strong | Fair; use ANSI SQL, user-defined functions and stored procedures for specific query needs |
Time Series Databases: Final Thoughts
To sum up, SingleStore is a strong general-purpose database that has the majority of the functionality you need for time series, but lacks some time series-specific optimizations.
The specialty time series alternatives are optimized for purpose. They have the weaknesses, however, of both the limitations of NoSQL – lack of structure, lack of easy queries with SQL, and overall slow query performance.
Adopting a new database is a big decision. We recommend that you review our case studies and then try SingleStore for yourself. Or, contact us to schedule a consultation to learn how SingleStore can support your use case.





