
SingleStore has reached a benchmarking breakthrough: the ability to run three very different database benchmarks, fast, on a single, scalable database. The leading transactions benchmark, TPC-C, and analytics benchmarks, TPC-H and TPC-DS, don’t usually run on the same scale-out database at all. But SingleStore runs transactional and analytical workloads simultaneously, on the same data, and with excellent performance.
As we describe in this webinar write-up, our benchmarking breakthrough demonstrates this unusual, and valuable, set of capabilities. You can also read a detailed description of the benchmarks and view the recorded webinar.
SingleStore stands out because it is a relational database, with native SQL support – like legacy relational databases – but also fully distributed, horizontally scalable simply by adding additional servers, like NoSQL databases. This kind of capability – called NewSQL, translytical, HTAP, or HOAP – is becoming more and more highly valued for its power and flexibility. It’s especially useful for a new category of workloads called operational analytics, where live, up-to-date data is streamed into a data store to drive real-time decision-making.
The webinar was presented by two experienced SingleStore pros: Eric Hanson, principal product manager, and Nick Kline, director of engineering. Both were directly involved in the benchmarking effort.
SingleStore and Transaction Performance – TPC-C
The first section of the webinar was delivered by Eric Hanson.
The first benchmark we tested was TPC-C, which tests transaction throughput against various data sets. This benchmark uses two newer SingleStore capabilities:
- SELECT FOR UPDATE, added in our SingleStoreDB Self-Managed 6.7 release.
- Fast synchronous replication and durability for fast synchronous operations, part of our upcoming SingleStoreDB Self-Managed 7.0 release. (The relevant SingleStoreDB Self-Managed 7.0 beta is available.)
To demonstrate what SingleStore can do in production, we disabled rate limiting and used asynchronous durability. This gives a realistic aspect to the results, but it means that they can’t be compared directly to certified TPC-C results.
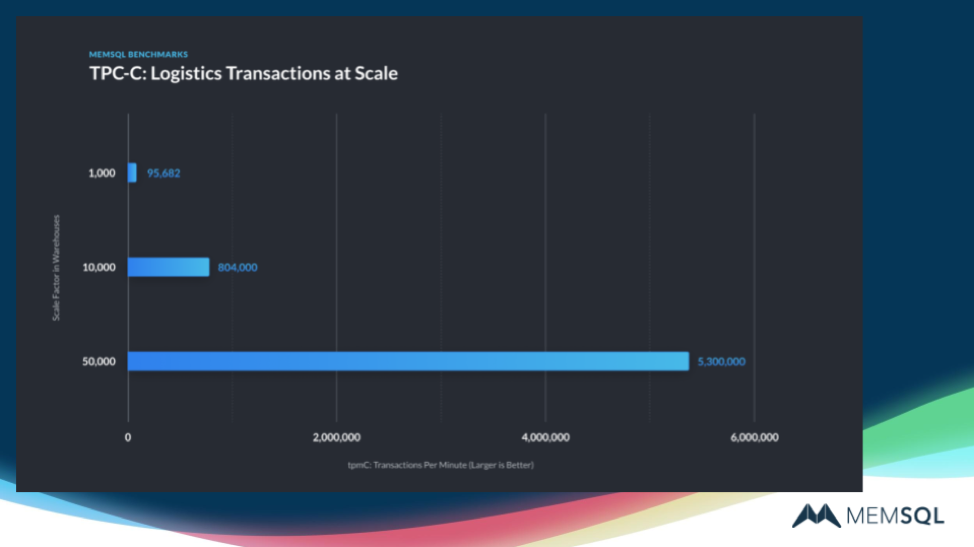
These results showed high sync replication performance, with excellent transaction rates, and near-linear scaling of performance as additional servers are added. For transaction processing, SingleStore delivers speed, scalability, simplicity, and both serializability and high availability (HA) to whatever extent needed.
SingleStore and Analytics Performance – TPC-H and TPC-DS
The second section of the webinar was delivered by Nick Kline.
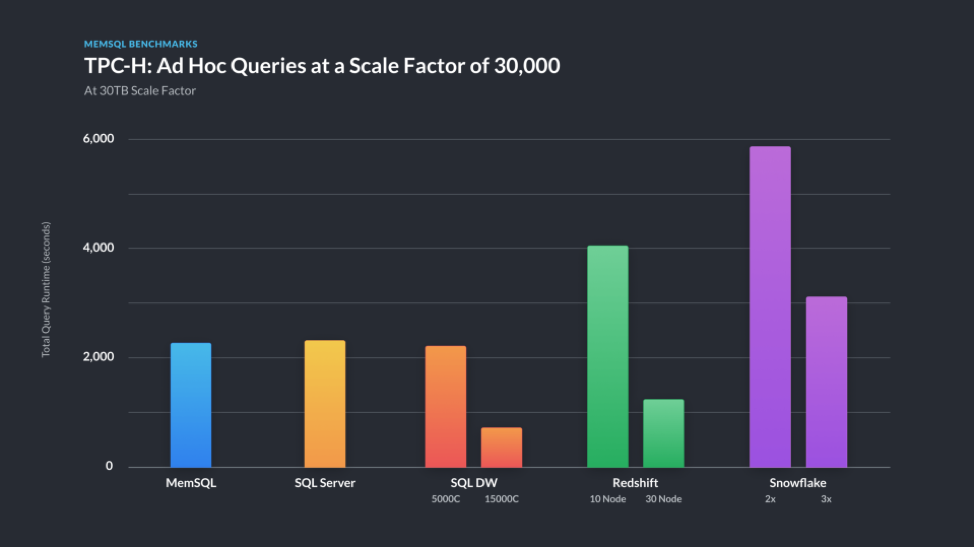
Data warehousing benchmarks use a scale factor of 10TB of data at a time. SingleStore is very unusual in being able to handle both fast transactions, as shown by the TPC-C results, and fast analytics, as shown by these TCP-H and TPC-DS results – on the same data, at the same time.
SingleStore is now being optimized, release to release, in both areas at once. Query optimization is an ongoing effort, with increasingly positive results. Nick described, in some detail, how two queries from the TPC-H benchmark get processed through the query optimizer and executed. The breakdown for one query, TPC-H Query 3, is shown here.

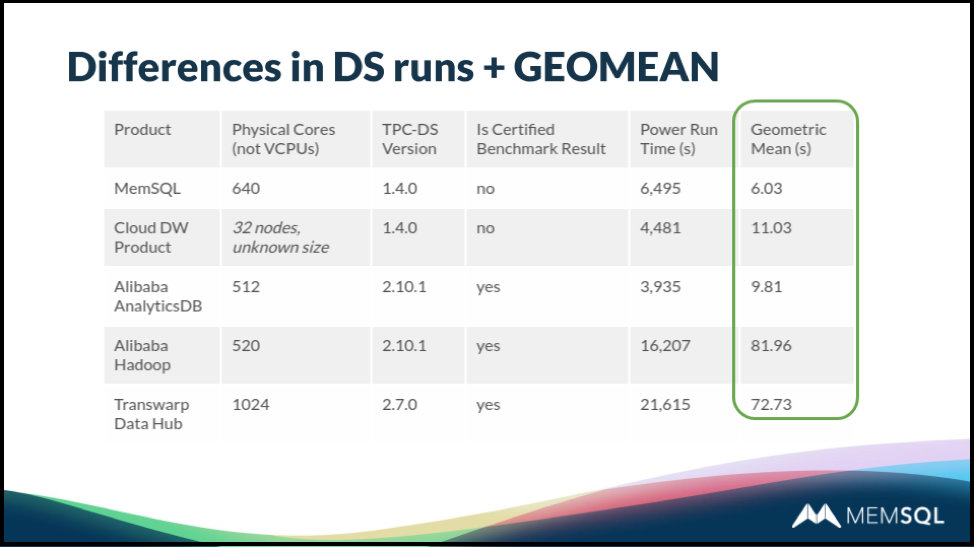
The TPC-DS benchmark is somewhat of an updated and more complex version of the TPC-H benchmark alluded to above. In fact, it’s so challenging that many databases – even those optimized for analytics, can’t run it effectively, or can’t run some of the queries. SingleStore can run all the queries for both TPC-H and TPC-DS, as well as for TPC-C, and all with good results.
For TPC-H, smaller numbers are better. SingleStore was able to achieve excellent results on TPC-H with a relatively moderate hardware budget.
Results for TPC-DS were also very good. Because queries on TPC-DS vary greatly in their complexity, query results vary between very short and very long result times. As a result, the geometric mean is commonly used to express the results. We compared SingleStore to several existing published results. Smaller is better.
Q&As for the SingleStore Benchmarks Webinar
The Q&A was shared between Eric and Nick. Also, these Q&As are paraphrased; for the more detailed, verbatim version, view the recorded webinar. Both speakers also referred to our detailed benchmarking blog post.
Q. Does SingleStore get used for these purposes in production?
A. (Hanson) Yes. One example is a wealth management application at a top 10 US bank, running in real-time. Other examples include gaming consoles and IoT implementations in the energy industry.
Q. Should we use SingleStore for data warehousing applications, operational database needs, or both?
A. (Hanson) Our benchmarking results show that SingleStore is excellent across a range of applications. However, SingleStore is truly exceptional for operational analytics, which combines aspects of both. So we find that many of our customers begin their usage of SingleStore in this area, then extend it to aspects of data warehousing on the one hand, transactions on the other, and merged operations.
Q. How do we decide whether to use rowstore or columnstore?
A. (Kline) Rowstore tables fit entirely in memory and are best suited to transactions, though they get used for analytics as well. For rowstore, you have to spec the implementation so it has enough memory for the entire application. Columnstore also does transactions, somewhat more slowly, and is disk-based, though SingleStore still does much of its work in memory. And columnstore is the default choice for analytics at scale. (Also, see our rowstore vs. columnstore blog post. – Ed.)
Q. How do you get the performance you do?
A. (Hanson) There’s a lot to say here, but I can mention a few highlights. Our in-memory data tables are very fast. We compile queries to machine code, and we also work against compressed data, without the need to decompress it first – this can cut out 90% of the time that would otherwise be needed to, for instance, scan a record.
We have super high performance for both transactions and analytics against rowstore. For columnstore, we use vectorized query execution. Since the early 2000s, there’s a new approach, in which you process not single rows, but thousands of rows at a time. So for filtering a column, as an example, we do it 4000 rows at a time, in tight loops. Finally, we use single instruction, multiple data (SIMD) instructions as part of parallelizing operations.
Conclusion
To learn more about SingleStore and the improvements in SingleStoreDB Self-Managed 6.8, view the recorded webinar. You can also read the benchmarking blog post and view the benchmarking webinar. Also, you can get started with SingleStore for free today.





