
Eric Hanson, Principal Product Manager at SingleStore, is an accomplished data professional with decades of relevant experience. This is an edited transcript of a webinar on time series data that he recently delivered for developer website DZone. Eric provided an architect’s view on how the legacy database limits of the past can be solved with scalable SQL. He shows how challenging workloads like time series and big data analytics are addressed by SingleStore, without sacrificing the familiarity of ANSI SQL. You can view the webinar on DZone.
Time series data is getting more and more interest as companies seek to get more value out of the data they have – and the data they can get in the future. SingleStore is the world’s fastest database – typically 10 times faster, and three times more cost effective, than competing databases. SingleStore is a fully scalable relational database that supports structured and semi-structured data, with schema and ANSI SQL compatibility.
SingleStore has features that support time series use cases. For time series data, key strengths of SingleStore include a very high rate of data ingest, with processing on ingest as needed; very fast queries; and high concurrency on queries.
Key industries with intensive time series requirements that are using SingleStore today include energy and utilities; financial services; media and telecommunications; and high technology. These are not all the industries that are using SingleStore, but these four in particular, we have a lot of customers in these industries and these industries use time series data.
Editor’s Note: Also see our blog posts on time series data, choosing a time series database, and implementing time series functions with SingleStore. We also have an additional recorded webinar (from us here at SingleStore) and an O’Reilly ebook download covering these topics.
Introduction to SingleStore
SingleStore has a very wide range of attributes that make it a strong candidate for time series workloads. You can see from the chart that SingleStore connects to a very wide range of other data technologies; supports applications, business intelligence (BI) tools, and ad hoc queries; and runs everywhere – on bare metal or in the cloud, in virtual machines or containers, or as a service. No matter where you run it, SingleStore is highly scalable. It has a scale-out, shared-nothing architecture.
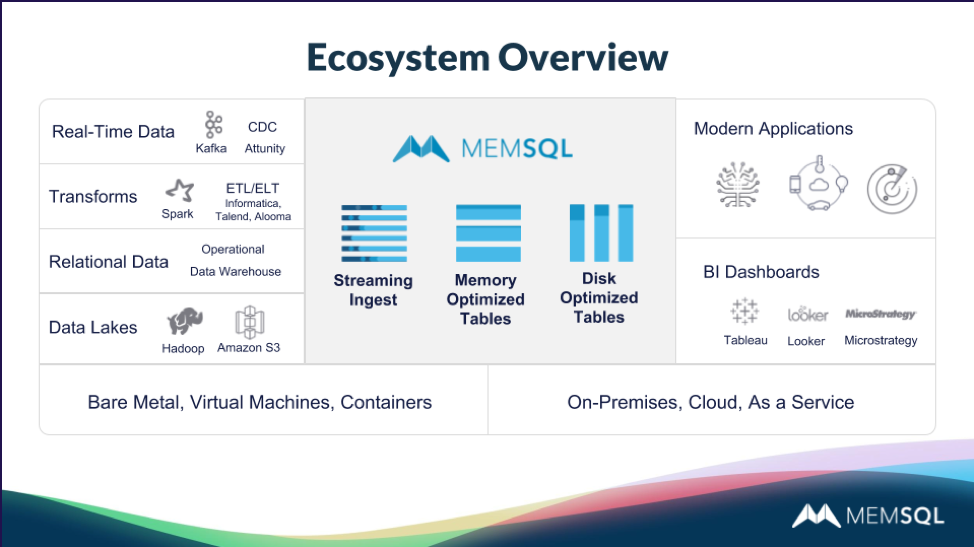
Ingest
The SingleStore database has a very broad ecosystem of tools that work well with it. On the left of the diagram are major data sources that work with SingleStore.
SingleStore has a very high-speed ability to ingest data. That includes fast bulk loading and streaming data with our Pipelines feature.
SingleStore is partnering with a company to build connectors to relational data stores. We support loading and conductivity with data lakes including Hadoop, HDFS, and Amazon S3.
For example, you can stream data in real time into SingleStore using Kafka streaming into pipelines in SingleStore. It’s a very convenient way to load data into SingleStore. Just dump data into a Kafka queue and SingleStore will subscribe to that queue, and be able to load data in real time into tables without writing any code to do that. Also, we support transformations with tools such as Spark and Informatica.
Rowstore and Columnstore
SingleStore stores data in two types of tables: memory-optimized rowstore tables and columnstore tables that combine the speed of memory and the capacity of disk storage.
In-memory rowstore-oriented tables are used for extremely low latency transactions, as well as very fast analytics on smaller quantities of data.
Disk-optimized columnstore tables support tremendous scale – petabyte scale. They include built-in compression on write, analytics and queries against compressed data, and high performance.
Querying and Reporting
Lots of application software already can connect to SingleStore because we support ANSI SQL and use standard relational database connectivity capabilities like ODBC. Pretty much anything that connect to a MySQL system can connect to SingleStore.
You can write custom apps to connect to SingleStore easily with APIs that you’re already accustomed to. In addition, a broad range of BI tools and Dashboarding systems can connect to SingleStore, such as Tableau, Looker, and Microstrategy.
SingleStore for Time Series
With these broad capabilities, and some specific features we’ll describe here, SingleStore is a fantastic time series database.

Where SingleStore really shines, and does a fantastic job for time series data, is in those time series use cases where there are one, two, or three of the following requirements:
- High ingest rate. You’ve got a lot of events per second coming in, or you need to load data extremely fast, perhaps periodically. So high ingest rate.
- Low-latency queries. You need a very fast, interactive response time for queries. These can come from apps, from BI tools, from ad hoc queries, or a combination.
- Concurrency needs. SingleStore shines when you have a strong need for concurrency. You simply scale the number of machine instances supporting SingleStore to support as many simultaneous users as you need.
When you have one, two, or three of these requirements, SingleStore is a really good choice for time series data.
ANSI SQL
SingleStore’s built-in support for schema and ANSI SQL is first and foremost in the features that make us a good fit for time series data. SQL supports a lot of powerful capability for filtering, joining, aggregating, and you need that kind of capability when processing time series data. SQL support is a general purpose capability, and it’s needed and applicable for time series as well.
Unlike many databases that more or less specialize in time series data, SingleStore supports transactions. So if you’re doing time series, as with any application, you want your data to be permanent and secure and consistent. Transaction support in SingleStore makes that possible.
Ingest
One of the thing that really people love about processing time series data with SingleStore is fast and easy ingest. You can ingest data in multiple ways, including inserting the data with regular insert statements, a bulk loader to load data, as well as SingleStore Pipelines. You can use whichever technique is most convenient for you and performance will be very fast.
I’d like to give some more detail on SingleStore Pipelines. You can create a pipeline that references a Kafka queue, or a file folder in your Linux file system, or AWS S3, or an Azure Blob store. Then you start the pipeline and we directly load the messages from a Kafka queue, or files that land in the file folder that you pointed us at. You don’t need a fetch-execute loop in your application; we handle that for you with our pipelines approach.
You can also transform the data with pipelines using external scripts written in Python, or any language you want, using a standard interface. It’s convenient to load with pipelines, and you can transform the data if you need to.
We support transactional consistency in our loader. If you load a file, it’s either all going to load, or none of it’s going to load. Queries will see all of the file or none of it. We support exactly-once semantics with Kafka pipelines.
You can ingest data into SingleStore phenomenally fast. I can’t emphasize this enough.
I got the opportunity to work with our partner Intel using a Xeon Platinum server – a single server with two Xeon Platinum chips, with 28 cores each, and high performance solid state disks (SSDs) attached.
I configured it as a cluster – some people call it a cluster in a box. It had two leaf nodes and one aggregator, but all installed on this same machine.
Then I just loaded data with a driver that was highly concurrent – using lots and lots of concurrent connections that were running inserts and updates, or upserts, simultaneously, and was able to drive 2.85 million rows per second insert and update on a single server.
That is a phenomenal rate, I mean very few applications need much more than that. And, if you need to scale to ingest data faster than that, we can do it. You just have to add more nodes and scale out.
Queries
SingleStore also supports fast query processing with vectorization and compilation. We compile queries to machine code. I described earlier about how SingleStore is typically an order of magnitude or more faster than legacy, rowstore-oriented databases. One key reason for that is that we compile our queries to machine code. When a query accesses a rowstore table, it’s executing code directly, rather than being interpreted as legacy databases do. We also support window functions, which are very helpful for time series data, and I’ll get into that in detail later on.
We support extensibility extensively: stored procedures, user-defined functions, and user-defined aggregate functions. All three of these are useful for managing time series.
SingleStore also has excellent data compression. Time series event data can be very voluminous, and so it’s important to be able to compress data to save storage. SingleStore’s columnar data compression does an excellent job of compressing time series events.
So let’s talk about how to query data effectively with time, when it’s time series data. Window functions allow you to aggregate data over a window of rows. You have to specify your input set of rows by a partition key. Then within each partition, you will have an ordering or sort order.

The window functions compute a result for each row within a partition, so the window function result depends on the order of the rows within that partition. So, as an example, as illustrated on the right above, you may have an input set of rows like that entire larger block. You see the purple color between start and end is your window, and there’s a concept of the beginning of the window, the end of the window and the current row within the window that you can specify with SQL using this new extension in SQL for Window functions.
SingleStore supports a bunch of different Window functions. We support ranking functions, as well as value functions like LAG and LEAD, and aggregate functions like SUM, MEAN, MAX, AVERAGE, COUNT, et cetera. Then special percentile functions to give you a percentile value.

SingleStore for Time Series Examples
I’m going to give a simple example of a time series application, just based on a Tick stream. Imagine that you have very simple financial Tick stream which has a table called Tick, which has a high resolution daytime, daytime six.
SingleStore supports a daytime or timestamp type, which has six digits after the decimal place. So it supports resolution down to the microsecond, which is a high resolution timestamp you may need for some of your time series of applications.
In this example table, I’ve got a high resolution timestamp, then a stock symbol, and then the trade price. This is oversimplified, but I just want to use this simple example for some future queries I’m going to show you.

One important thing that you may need to do with time series data is to smooth the data. So you might have Ticks coming in, or you might have events coming into a time series. Perhaps there’s a lot of noise in those events, and the curve that looks jagged, you want to smooth it out for easier display, easier understanding for your users.
You can do that with Window functions and SingleStore. So this is an example of a query that computes the moving average over the last four entries in a time series. In this case, the example is just pulling out the stock ABC, and we want to know what the stock symbol is, what the timestamp is, the original price and the smooth price. So you can see there in the tabular output below how price moves up and down, a little bit chunky. Then the smooth price averages over a sliding window of between three rows preceding and the current row.

So that’s how we get the four entries that we’re averaging over for the smooth price. You can define that window any way you want. You could average over the entire window, or rows preceding and the current row, or rows from preceding the current row to after the current row. You can define the window whoever you like.
Another important operation that people want to do on time series data is to aggregate over well-defined time buckets. This is called time bucketing. Maybe you want to convert an irregular time series to a regular time series. So an irregular time series has entries at irregular intervals. They may arrive at random intervals, so you might not have say one entry every second. You might have on arrival time on average, one entry every half a second, but maybe like a statistical process, like a Poisson process of arrival time.

You might have several seconds between arrivals of Ticks, and you might want to convert that so you’ve got one entry every second. That’s something you can do with time bucketing.
Another application of time bucketing is if you may want to convert a high resolution time series to a lower resolution. For example, you might have one entry per second, and you might want to convert it to have one entry per minute. That’s reducing the resolution of your time series.
There are a couple of different ways you can do time bucketing in SingleStore. One is to group by a time expression. So, for example, that query that says select ts:> daytime and so on. That first one, that expression ts :> daytime, that’s a typecast in SingleStore. It converts that timestamp to the daytime, not a daytime six. So that is going to have resolution of a single second. We won’t have fractional seconds.
You can convert to daytime, take an aggregate, then group by the first expression, and order by the first expression. That’ll convert a high-resolution time series to a one-second granularity time series.
You can also use user-defined functions to do time bucketing. I’ve written a time bucket function which takes two arguments. The first argument is a time pattern that says something like one second, one minute, three seconds, et cetera. So you can define with a phrase what your time bucket is. The second argument is the timestamp.
You can do this with an expression in the query, but just as a simplification, I’ve written this time bucket user-defined function and there’s a blog post that’ll be coming out soon. (For more detail, and for an additional example with candlestick charts, view the webinar. We will link to the more detailed blog post when it’s available – Ed.)
More on SingleStore for Time Series
SingleStore can solve time series development challenges for you in a number of different ways, because we have incredibly high performance through our scale-out, our query compilation, and our vectorization. Your time series queries will run fast and we can scale to handle large workloads and large data volumes.
Also, we support very fast ingest of time series events through just regular insert statements, upserts, load, or pipelines. Also, we support powerful SQL Window function extensions that are terrific for time series. They’re fully built into SingleStore, as native implementations. If you want, you can make your time series processing a little bit easier using user-defined functions, and user-defined aggregate functions, and stored procedures, just to add more power and flexibility to your time series processing.
Finally, SingleStore provides all the capabilities of a distributed SQL DBMS. So if you’re going to build a time series application, you may have a choice between using a purpose-built time series database that’s specific to time series, or a general purpose database like SingleStore.
If you choose a general purpose database, you’re going to have a lot of extra benefits that come with that, including SQL transactions, backup and restore, full cluster management, rowstore, indexes on the rowstore, columnstore, concurrency, high availability. You can handle general purpose applications that are transactional. You can handle analytical applications like data warehouses, data marts, operational data stores, or analytical extensions to your operational apps.
You have full SQL capability to do outer joins and other kinds of things that may be difficult to do in a time series specific database. So the generality of SingleStore can handle a lot of different application needs. Moreover, SingleStore can still handle time series really effectively with powerful Window functions and user-defined extensions.
We invite you to try SingleStore today, if you haven’t tried it already. You can download SingleStore today. SingleStore can be used free in production for up to 128GB of RAM capacity; if some of your data is in columnstore format, that can represent hundreds of gigabytes of total database size. Or, you can use our Enterprise trial, which has unlimited scale, for up to 30 days for development.
Q&A
Q: There are a few technologies out there that build time series functions on top of PostgreSQL. So the general question is, what would make the SingleStore offering different vs. something that is implemented on top of a PostgreSQL-based solution?
A: The main difference is the performance that you’re going to get with SingleStore for ingest and for large-scale query. So a PostgreSQL-oriented system, depending on which one you’re looking at, it may not provide scale-out. Also, SingleStore has an in-memory rowstore and a disk-based columnstore. We compile queries to machine code and use vectorization for columnar queries. We have a higher-performance query processing engine than you might get for standard query processing operations on PostgreSQL.
Q. What would be some differences or advantages between a NoSQL-based time series implementation, versus something that SingleStore offers?
A. Standard NoSQL systems don’t necessarily have special time series support, and they often don’t support full SQL. So one thing that you find different about SingleStore is that we do support full SQL and Window functions, which are good for processing time series style queries. So that’s the main difference that I see.
Q. What are techniques that can allow SingleStore to extend the throughput from an ingest perspective?
A. You saw, earlier in the talk, I showed ingesting 2.85 million rows per second into a single server transactionally. So that’s a pretty phenomenal rate. As I said, if you need to scale more than that because we support scale-out, you can add more servers and we can load data – basically limited only by how much hardware you’re providing. You can add extra aggregators and extra leaves.
If you’re inserting data directly by adding aggregators, you can increase the insert rate that you can handle. Also, our pipelines capability is fully parallel, at the leaf level. So if you want to do ingest through pipelines, you can scale that out by adding more leaves to your cluster.
In addition, our loader is pretty high performance and we’ve done some work in that area recently. In the last release, the 6.7 release, we introduced dynamic data compression into our loader – because when you’re loading data, you may need to shuffle the data across your nodes as part of that operation.
We have an adaptive data compression strategy that compresses data as it’s flowing between the leaves over our internal network, if we’re bandwidth limited on the network. So there’s a bunch of techniques you can use to increase the performance of SingleStore for loading by scaling. Then just the implementation of our load is pretty high performance, through techniques like compilation to machine code, and also dynamic compression.
Q. Are there limitations to pipelines in terms of the number of concurrent, or parallel pipelines used. Is there any sort of physical limitation there?
A. I’m not aware of any limitations other than the capacity of your cluster, the hardware capacity of the cluster. I don’t think there are any fixed limits.
Click to view the webinar on DZone.





