
Time series data is as old as databases themselves – and also the hot new thing. Interest in the topic has more than doubled during this decade. In this blog post, we’ll explain what time series data is, why there’s an increasing focus on it, and how SingleStore handles it. In a companion blog post, we explain the considerations that go into choosing a time series database.
Time series data is at the core of the Internet of Things, with frequent sensor readings coming in from all sorts of devices. But what is time series data?
We provide a brief answer below, for quick reference. For more detail, please see Chapter 1 of our free excerpt from the O’Reilly book, Time Series Databases.
For related information, see our companion blog posts on choosing a time series database and implementing time series functions with SingleStore. Also see our time series webinars from DZone and SingleStore.
Time series data is inherently well-structured… except when it isn’t. For a simple time series data record in IoT, for example, you might have the sensor number or other identifier, the date, the time, and a reading – that’s it.
| Sensor ID | Date | Time (sec) | Value |
|---|---|---|---|
| 4257 | 01012019 | 011304 | 233518 |
Notice that, in this simple example, the data is inherently well-structured – and therefore suitable for processing by both traditional transactional databases and analytical data warehouses with SQL support, or more effectively through a “translytical” NewSQL database such as SingleStore.
Also notice the timestamp field. More precise – that is, longer – timestamps make time series data more useful. However, they also make the data more voluminous, both in flight and in storage, as well as slower to process for comparison and queries. Given the frequent use of time series data for alerting, as discussed in our next article on this topic, the ability to do quick comparisons on time series data is an especially important consideration.
When you begin to collect and work with time series data at scale, the data can overwhelm the capacity of traditional databases at every stage of the data lifecycle: ingest, storage, transactions (if any), and queries. For example, a modern airliner generates half a terabyte of data per flight. A connected car can generate 300TB of data a year. And data that used to be considered disposable, such as routine transaction data, is now being seen as worth capturing and keeping online.
Now, how much of this kind of data can you afford to throw away? Using our example above, cars are subject to recalls, safety investigations, lawsuits, and much more. Their manufacturing and performance can be optimized to a significant extent – if you have the information needed to perform the analysis necessary to do it.
Cases such as these, where companies collect, analyze, and act on huge amounts of time series data, are expected to grow exponentially in the next 10 years.
The sheer volume of time series data, paired with its increasing value, is where the trouble starts; trouble which is (partly) handled by creating more complex data structures (see below).
Transaction Records as Time Series Data
Time series data has traditionally been associated with simple processes that produce lots of data, such as sensor measurements within a machine. But those of us who focus on transactions have been using – and, in some cases, ignoring – time series data for years.
Think of a customer database that includes the customer’s address. Every time the customer moves, that’s treated as a database update. The transaction record comes in, is held, and might append or overwrite the previous customer record. And the transaction record is thrown away – or, at best, is held in a transaction log somewhere in cold storage.
In a strict transactional scenario, you now no longer know all sorts of things you could have known. How often do your customers move? Is a given customer moving from lower- to higher-income zipcodes, or heading in the other direction? Does this correlate with – or even predict the direction of – their credit score and creditworthiness?
The answers to these questions, and many more, in a strict transactional scenario, are all the same: I don’t know, I don’t know, and I don’t know.
Furthermore, if the transactions aren’t online, you have no way of ever knowing these potentially important facts again – at least not without mounting a bunch of tapes currently gathering dust in a storage facility.
Part of the current mania for storing every transaction record you get, in raw or lightly processed form, in storage that is at least warm, comes from management’s expecting to be able to answer simple questions like those mentioned above. To be able to answer these questions, the organization must collect, store, and be able to quickly analyze data that was once thought irrelevant.
Per-Minute Time Series Data
Some of the complexity around processing time series data comes from a clever method used to battle its voluminousness. Sensors are likely to report (or, to be polled) at varying intervals. Instead of creating a separate record for each new reading, you can create one record, for example, per minute (or other time period).
Within the record of that minute, you can store as many values as come in. (Or, you can only record changed values, or values that change more than a prescribed amount, storing the time at which the change occurred and the new value.)
Because this data is not prescriptively structured – the number of values is not known in advance, so the size of the data in the field can vary – the field that holds the data qualifies as a blob.
| Sensor ID | Date | Time (min) | Values |
|---|---|---|---|
| 4257 | 01012019 | 0113 | [04,233518],[14,233649] |
The use of blobs, such as this one, in time series data has long been used as a rationale for using NoSQL databases to store it. For a long time, if you had anything but structured data – if you had unstructured data, or even semi-structured data, such as this – a traditional transactional database, the kind that had SQL support, couldn’t efficiently store it.
However, the emergence of JSON as a standard enables a new approach that makes it possible to answer this question differently. You can use key-value pairs in JSON format to store this variable data, and this approach is getting increasingly common. Over the last few years, SingleStore has steadily increased both its ability to store JSON data and the performance of processing and queries against data stored in JSON format.
SingleStore is now able to provide excellent performance for JSON processing and queries against JSON data. This capability makes SingleStore fully competitive with bespoke time series databases for many use cases for the things they’re optimized for. At the same time, SingleStore provides capabilities, such as fast transaction processing, support for many simultaneous users (concurrency), and query performance at volume, that most time series databases lack.
Time Series Data, Machine Learning, and AI
One of the big reasons for the newfound importance of time series data – and the increasing drive to keep as much data as possible, of all types, online – is the increasing use of machine learning and AI.
At the most basic level, executives are going to use machine learning and AI to ask the same questions they might have asked before – about such things as a customer’s house moves and their likely income. But now they might also ask far more detailed questions – about customers’ movements within a retail store, for instance, or across a website.
But machine learning and AI can also be more or less self-powered. Machine learning algorithms can run against a database and find out interesting things for themselves – things that no one could ever have predicted, such as a tendency among customers signed up at different times of year to be more or less valuable. (Companies have even gotten in hot water for sending baby product discounts to people whose families didn’t know they were expecting.)
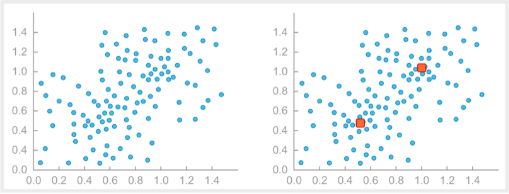
Machine learning algorithms can identify valuable “hot spots”
among seemingly random correlations. (Source: SingleStore)
The algorithms can only do their work, though, if the data is there to support this kind of investigation. Companies with more data will have a competitive advantage against their smaller competitors, as well as against those who ran their data storage policies in a more “lean and mean” fashion.
Don’t Isolate Your Time Series Data
Many organizations have only partially learned their lesson about the value of time series data.
There is an increasing drive to retain data and to keep it readily accessible for analytics and transactions, machine learning, and AI. However, the data is often kept in NoSQL databases, such as a Hadoop/HDFS data lake, where it’s harder to analyze.
Querying capability slows greatly when each query that you process has to do the work that a database with the right kind of structure – including, where needed, the ability to support semi-structured data in JSON format – has already done for you.
SingleStore gives you the best of both worlds. You can keep massive volumes of time series data in SingleStore, using it as an ultra-fast operational data store that also has excellent analytics support (something that NoSQL databases are inherently unsuited for). That way nothing is out of reach of your business.
For much more about choosing the right database for your time series data, see our blog post on choosing a time series database. For more about using SingleStore for time series applications, please watch our webinar on the topic.





