
Modern businesses are geared more toward generating customer value, making decisions and predictions using highly demanding technologies like Artificial Intelligence (AI), Natural Language Processing (NLP) and Machine Learning (ML). Naturally, the demand for data is rapidly growing.
To train highly accurate machine learning models, extensive amounts of data known as data corpus are essential. In this guide, you’ll be introduced to the data corpus concept and its importance in ML and AI domains, how the data corpus and machine learning capabilities are adopted by databases like MySQL (and MySQL wire-compatible databases) and how as a MySQL wire-compatible database, SingleStoreDB leads the market with high-demanding machine learning & artificial intelligence capabilities with immense support for data corpus.
The Corpus of Data
At present, a large corpus of data is massively useful across all industries to generate beneficial insights, predictions and decisions for businesses.
Generally, a data corpus is a collection of genuine audio or text that is spoken or written by a native speaker. A corpus can be generated from numerous sources including social networks, like Facebook and WhatsApp, Google and Apple app stores, Amazon marketplaces, tweets, movies, television shows, newspapers, etc. This data is extremely useful in the natural language processing domain to model artificial intelligence and machine learning models. To support a specific problem in an identified domain, it is a must to have a bunch of data that represents the given domain, and the problem to be achieved with ML and NLP.
Some of the features associated with a good data corpus include:
- High-quality. Quality is critical for a data corpus, since it’s made up of a massive amount of data — and a minor error in the training set may lead to inaccurate outputs in the trained system.
- Balance. It is important to keep the balance of the corpus of data by aligning and structuring the data assembly procedure, which balances the relevancy of the corpus to the addressed domain or problem.
- Clean data. In ML and NLP domains, data cleaning is the process of eliminating incorrect, duplicate, incomplete and incorrectly formatted data within a corpus. At the end of the day, data cleaning provides a more reliable corpus of data for ML models.
- Large Corpus. Usually, large datasets provide more accurate and reliable outputs from trained machine learning models So, a large corpus is recommended.
Data Backbone for ML and AI
Machine learning is an application of artificial intelligence, which is capable of learning and improving itself without the need for human intervention. This area is mainly focused on implementing models that can access a large set of data — or corpus of data — to learn and update themselves. So, it has already been proven that a corpus of data is the fundamental piece or backbone of a machine learning model. Hence, data capturing, loading and querying with low latency is critical.
With the significant need for data corpus in machine learning environments, database technologies have evolved to support massive amounts of data streamed in from different sources to store, query and train machine learning models in real time. MySQL is one of the popular databases that adopts machine learning features with its new tool called HeatWave.
Apart from that, several other MySQL wire-compatible databases like AWS Aurora ML, MariaDB and ClickHouse with MindsDB support machine learning capabilities up to some extent — which still lacks support for storing the corpus of data and retrieving data with low latency to support training ML models in real time.
In contrast, SingleStoreDB, the real-time, distributed SQL database which features MySQL wire protocol compatibility, is capable of storing, loading and querying various types of corpus and providing high-speed machine learning querying to train ML models in real time as a single unit.
MySQL HeatWave ML

MySQL uses a HeatWave plugin to accelerate the performance of analytical workloads and machine learning. In short, the HeatWave cluster helps MySQL accelerate data processing, which in turn opens the door for Online Analytical Processing(OLAP) and machine learning model training with a data corpus. In addition, the HeatWave cluster provides access to HeatWave ML, which is a machine-learning solution to train ML models.
As mentioned, MySQL’s HeatWave ML is a separate cluster program that has been connected to the MySQL system as a plugin — since MySQL lacks handling, loading and machine learning querying with a data corpus.
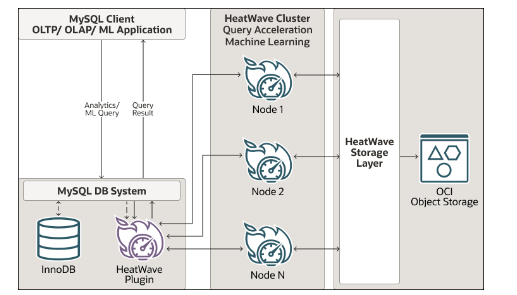
As a MySQL-compatible database, SingleStoreDB provides all these features within a single engine, without the need for a separate plugin or service.
Amazon Aurora ML

Amazon Aurora is a MySQL wire-compatible cloud database system offered by Amazon Web Services. Like MySQL, Amazon Aurora clusters enable its machine learning capabilities with the help of Aurora ML services like Amazon SageMaker or Amazon Comprehend.
Amazon SageMaker is a fully managed machine learning service that is used to train, build and test machine learning models. Additionally, Amazon Comprehend is a NLP service offered by Amazon for mining insights from various written documents.
However, any of these services should be set up separately and ready to be integrated with your Amazon Aurora DB system. These are not in-built features of the Amazon Aurora database and upon integration, they enhance the performance of operating with data corpus and machine learning queries.
To highlight, Amazon Aurora lacks in-built machine learning capabilities like working with data corpus, loading, and querying data with low latency — whereas SingleStoreDB provides all these data handling/querying features with the speed needed to train machine learning models out of the box.
Machine Learning & AI with MindsDB for MariaDB, ClickHouse
MariaDB and ClickHouse both are MySQL-compatible cloud databases that are not primarily built to load or query the corpus of data required to deal with complex machine learning model training, building and testing. With the help of MindsDB, MariaDB and ClickHouse enable high-performance machine learning querying, loading a corpus of data and training models up to some extent. But they are still far behind the ML features and performance of SingleStoreDB.
SingleStoreDB as a Data Backbone for Machine Learning & Artificial Intelligence
As highlighted in the first segment of this article, the corpus of data is the backbone for machine learning, natural language processing and artificial intelligence.
SingleStoreDB acts as a data backbone for machine learning and AI-based systems. Several significant properties are associated with SingleStoreDB, which is capable of dealing with a corpus of data to become one of the best players among other databases.
SingleStoreDB Features as a Data Backbone
- Ultra-fast, flexible & real-time data ingestion
- High performance query processing
- Low latency
- High Concurrency
- Real-time data warehouse
- Built-in machine learning functions
- Real-time machine learning scoring
- Machine learning in SQL with extensibility
- Code Engine — Powered by Wasm to apply machine learning algorithms.





