
It’s time for us to admit what we have all known is true for a long time: NoSQL is the wrong tool for many of the modern application use cases, and it’s time that we move on.
NoSQL came into existence because the databases at the time couldn’t handle the scale required. The rise of this new generation of data services solved many of the problems of web scale and rapidly growing data sets when it was created more than a decade ago. NoSQL also offered a new, cost-effective method for cold storage/occasional batch access for petabyte scale data. However, in the rush to solve for the challenges of big data and large numbers of concurrent users, NoSQL abandoned some of the core features of databases that make them highly performant and easy to use.
Dealing with these trade-offs might be NoSQL’s greatest contribution to the database world. It forced an evolution, combining the best of the big data capabilities with the structure and flexibility of the proven relational model to produce a scalable relational database.
Relational databases evolved to create an entirely new generation of systems that can handle nearly all of the workloads, with the scalability, reliability, and availability requirements that modern applications demand. From traditional workloads such as transactional applications and business analytics, to newer workloads such as multi-tenant services and operational analytics. The rise of new databases such as Google Spanner, Azure Data Warehouse, and our eponymous database, SingleStore, have proven that, for the majority of use cases, relational databases are easier to use and generally perform better than the NoSQL systems.
I know this might be controversial. I also know that you might quickly dismiss my perspective as biased. But let me break down the history, architecture, and applications of these databases, then judge for yourself.
This blog post, originally published in July 2018, has been updated with references to newer SingleStore releases. – Ed.
How NoSQL Rose in Popularity
NoSQL came full force onto the scene in the late 2000s, although it started much further back. It was developed largely to address the scale problems of existing database systems. It was clear that scale out was a more cost-effective model for building large systems. For the largest systems such as email and search built by Google, Facebook, Microsoft, and Yahoo, it was the only way to scale.
The value of scale-out first clicked for me personally when I read James Hamilton’s paper on designing and deploying Internet Scale Services in 2007. Scaling the application tier came first because it was easier to scale a stateless system. The storage layer was another story. By definition, databases are stateful, and maintaining the guarantees (i.e. ACID) on that state across a distributed system is really hard. So layers were built on top of the existing database systems (MySQL, SQL Server, etc.) to create a distributed storage layer.
I ran into a couple of examples of this while working as a Product Manager in the SQL Server team at Microsoft. The first example was internal at Microsoft where the company built Webstore, which was a sharding layer on top of SQL Server used by Hotmail and the associated services. In fact, Webstore was the motivation to build what eventually became today’s Azure SQL Database. Webstore was clunky and lacked a lot of core functionality but it worked and gave Microsoft an ability both to scale to the size of data it needed and achieve high availability. But Webstore required an entire team of engineers to build and maintain.
In the mid-2000s, MySpace had a large number of SQL Servers to manage the rapidly growing site. The company was adding users so fast that new SQL Server boxes needed to be added every day. Running all those SQL Servers and querying across them was a massively complicated endeavor that took a large number of engineers to maintain.
The same patterns were repeated at Facebook and others, because all of the burgeoning tech giants struggled with scale.
It became clear that, with their massive usage and growth, these new digital services demanded a new solution for ingesting, managing, and surfacing data. Ideally, we needed something that could natively present a single interface but scale out over many machines with built-in high availability.
Eventually, the large scale cloud services (Google, Facebook, Yahoo, Microsoft, and others) all built their own custom systems to handle scale demand. Those systems were all different but the basic ideas were shared, either directly or through academia. Eventually open source systems started popping up using those same ideas, and the NoSQL movement was born.
To solve for web scale, NoSQL departed from the traditional databases in a few critical ways, So let’s look at why these choices were made.
ACID and BASE: Pros and Cons of Eventual Consistency
There are two models for storage systems, ACID and BASE.
ACID stands for Atomic, Consistent, Isolation, and Durable. It covers the guarantees you get with most relational databases. ACID guarantees that writes have to wait for the data to hit disk before returning success to the client. Further, if you are really paranoid about durability (i.e. not losing data) you configured the database to wait until the write traveled over the network to some other machine and hit the disk on that side as well. So there is a guarantee that the data is always what you wrote but you give up some performance in write speed.
BASE, which is typical for NoSQL systems, stands for Basically Available, Soft State, and Eventually Consistent. Eventual consistency is faster on writes because the application doesn’t have to wait to see if the write persisted. As soon as the data store captured the write, but before it is persisted to disk or to another machine, it could tell the application the write was successful and the application could move on to the next operation. So you gain a performance advantage but at the risk of not seeing the data you just wrote, or the data might be lost altogether in an error condition.
Eventual consistency is a reasonable trade-off of durability risk versus availability. Developers continue to have to make these trade-offs as documented in this report.
If your business is consumer engagement and latency has a direct impact on your income (which is true for all content, community, and commerce applications), you want the most responsive UI you can get. If you have to scale to millions of concurrent users you can’t tolerate any bottlenecks. What you trade-off by adopting eventual consistency in your database architecture is occasionally losing someone’s post or a comment, which is an acceptable risk for these types of applications.
The other side of the spectrum of durability versus risk are things such as financial applications. You don’t want your bank using eventual consistency to store the result of your ATM transactions or your stock sales. In these cases, you still have users demanding little to no latency but are unwilling to accept a transaction not getting written to disk.
There is a place for eventual consistency, but it is not always the only answer. Architects and developers of data systems should be able to choose what level of consistency they want. That choice should be at the use case level, not a platform level.
Why Schema Is Important
It’s not clear why schema was lost as part of the NoSQL movement. Yes, it was hard in the early days to build a distributed metadata manager to maintain schemas across a distributed system to support operations, such as adding a column. So it was unsurprising for schema to have been left out of the early designs. But instead of finding a way to add it in later, schema was simply eliminated altogether. It’s also understandable why folks make the argument that it makes you less agile. Good schema design is hard and requires careful upfront thinking. When things are changing rapidly (as they were then and continue to be now) you don’t want to be locked into a schema.
But this is a fallacy.
It is true that lack of schema increases agility for the engineer who owns putting data into the system. However, it kicks the problem down to the readers of the data, who are usually an order of magnitude greater in number and often don’t have the context about the state of the data when it was written. These users are usually the ones who are generating value from that data and should have as few roadblocks as possible.
To give an analogy, imagine libraries saying they are doing away with the Dewey Decimal System and just throwing the books into a big hole in the ground and declaring it a better system because it is way less work for the librarians. There is a time and place for semi-structured data, because sometimes you don’t know the shape of some of the data ahead of time or it is sparsely populated. But if you truly don’t understand any of the data coming or what it will look like, then what good is it?
The truth is that there is always schema. The data always makes sense to someone. That someone should take the time to encode that knowledge into the platform so it is usable by the next people. If it is a mix of data that is understood and some that is changing rapidly, put the latter into a semi-structured column in a database, then figure out what columns to project out of it later. SQL Server and Oracle could do this with XML 15 years ago. SingleStore, and a number of other modern databases, can do it now with JSON data. Document data storage (and key/value) should be a feature of a modern database, not the sole capability of a product.
Non-SQL Syntax for Query
This decision in the design of NoSQL databases follows going schema-less. If you don’t have schema, then ditching SQL syntax kind of makes sense. In addition, query processors are hard to build for a single box, and building a distributed one is much harder. Most notably, if you are a developer trying to get a new app up and running, this kind of system feels easier.
MongoDB perfected the art of a simple installation and first-use experience. But it turns out the relational model is pretty powerful. Just having get and put functions is great if you never want to answer any question other than “fetch object with id 2”. But the majority of the applications out there end up needing more than that. If you want to read a great article by someone (who does not work on a data store product) who came to this conclusion after working on two separate projects with MongoDB read this. It is an excellent example of where document databases fall short.
In anything but the most trivial systems you always end up wanting to query the data a different way then you stored it. Ironically, the relational model was invented in the 1960s to solve this exact problem with the data stores of the time (IMS and Codasyl). A relational model with the ability to join is the only reasonable way to get data out. Yes, it is harder up front, but it is way easier than pulling all the data up into your app and building the join yourself. I have seen customers try to do this over and over again with NoSQL databases, and it always leads to madness.
Many of these NoSQL systems achieved their primary goal. They provided a data store with a single interface that could scale out over many machines with built-in high availability. While there has certainly been some success, NoSQL adoption has run into blockers.
There are couple of different reasons. Performance is a key one, in particular doing analytic queries with any sort of SLA. Manageability is another, because distributed systems are notoriously hard to manage. But the thing preventing traction with NoSQL more than anything, is the need to retrain people. There are a lot of people trained and educated in the relational world. NoSQL has been trying to convert the world for the last 10 years but it has only made a small dent. The NoSQL companies all together make up just a few percent of the $50 billion in the database market.
While software engineers seemed to love NoSQL, data people (DBAs, data architects, analysts) went reluctantly into the NoSQL world as seemingly the only way to achieve the scale necessary. But it meant they had to relearn new APIs, tools, and an ecosystem, throwing out years of successful approaches, patterns, and assets. They wanted to do things using a proven model, but still get the scale without compromising the durability, availability, and reliability of the system.
NewSQL – Best for Performance and Scale
When we built SingleStore, we started with the premise that customers liked the capabilities of relational databases but wanted the availability and reliability of a scale out systems. Our goal was to allow a customer to have the best of both worlds.
SingleStore is a distributed relational database that supports transactions and analytics and scales out on commodity hardware. You get the familiar relational model, SQL query syntax, and a giant ecosystem of tools coupled with the scalability and availability of modern, cloud-native systems.
Let’s revisit this in the context of the core differences of a NoSQL system.
SingleStore – Best for Consistency and Performance
SingleStore has knobs that let you tune how much you want to trade-off between consistency and performance. The trade-off will always be there, but now you don’t have to choose between these things at the platform level. You can make the choice for each use case that makes sense.
Consistency versus performance is not some hardcore philosophical choice, it is a choice of what is better for your application and requirements. SingleStore has two settings that let you tune for this. The first lets you decide whether to wait for disk persistence or not. There is an in-memory buffer that stores the transactions before they are persisted to disk. You can either have success return as soon as it hits the buffer or when it hits the disk. If you return when it hits the buffer there is a chance that a machine failure or reboot could happen before it is persisted and the data will be lost. On the other hand, waiting for it to persist to disk will take longer.
In addition, with HA you have two modes of replication, sync and async, that ensures a second copy of the data on another machine. If you set the replication to synchronous mode you wait until the transaction is received on the secondary before returning success to the client. If async mode for replication is on, then the transaction returns success before the data is replicated to the secondary. This gives you the ability to tune the trade-off consistency and durability for performance for what fits your risk/performance profile.
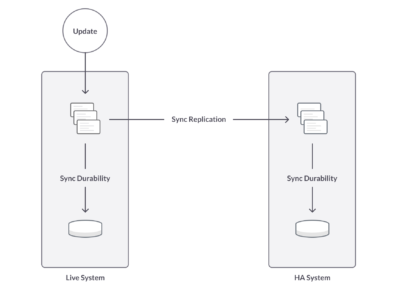
SingleStoreDB Self-Managed 7.0 includes fast sync replication and sync durability.
SingleStore – Schema (JSON, Spatial Types, Full-Text Indexes)
SingleStore implements schema by storing the metadata in small internal database and synchronously replicating the metadata to all the nodes when it is changed. It uses a two-phase commit to ensure that DDL changes propagate properly through the cluster and are built in a way so that they do not block select queries.
SingleStore supports more than just relational though. You can type a column as JSON and store a JSON document in it. If you decide there are some columns you want to query later, you can project the properties as columns and index them. SingleStore also supports Spatial types and Full-Text indexes as well. We understand that customers need a mix of data types in a system that is familiar and where all the types of data can co-exist naturally.
Take a deeper dive into SingleStore with our free managed service trial.
SingleStore – Lingua Franca
SingleStore has solved for using SQL syntax across distributed databases at scale. A distributed query processor allows you to express your query using standard SQL syntax, and the system takes care of distributing your query across the nodes in the cluster and aggregating the results back for you. SingleStore supports all of the common ANSI SQL operators and functions which gives you a powerful model for expressing just about any query.
SingleStore does this by having two node types in the system, aggregators and leaves. Aggregators handle the metadata of the distributed system, route queries, and aggregate results. Leaves store the data and do the heavy lifting of executing the query on the partitions. Where it can, SingleStore will execute joins locally, which is why schema design is pretty important. If it can’t, SingleStore will shuffle the data as needed. So customers can use the SQL language without knowing how the data is partitioned underneath. If you would like to learn more, SingleStore docs have more detail on how this is built.
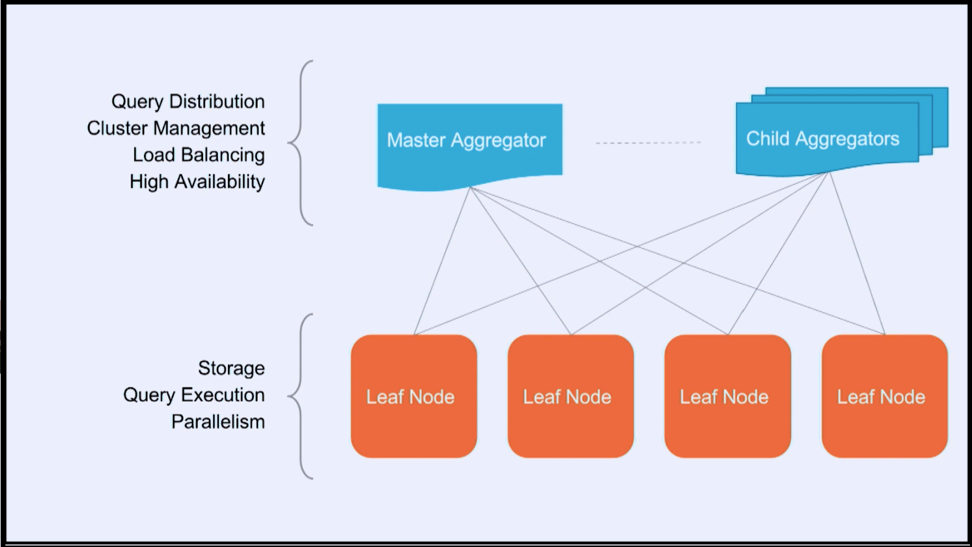
SingleStore distributes data across aggregator and leaf nodes.
What this means is that you are able to use the skills, investments, and tools you already have in your company with SingleStore, or people can use SingleStore the way they use any other relational database and don’t have to be retrained. In addition, because SingleStore supports the MySQL wire protocol, the existing massive ecosystem of BI, ETL, and other middleware tools just work with SingleStore. You don’t have to hire new staff, learn a bunch of new tools, or bring in new software. It just works.
Why You Shouldn’t Use NoSQL
NoSQL came along to handle the scale requirements as web apps and multi-tenant services were taking off. Given how hard the problems were to solve, it is understandable that these early attempts at dealing with scaling at the storage layer forced customers into a difficult set of trade-offs.
But relational databases have evolved. They can can handle nearly all of the workloads, with the scalability, reliability, and availability requirements that modern applications demand.
Workloads such as operational analytics. As all companies realize the value of being data driven they want to enable all their employees with up-to-date data. To do this requires a new breed of analytics systems that can scale to hundreds of concurrent queries, deliver fast queries without pre-aggregation, and ingest data as it is created. On top of that, they want to expose data to customers and partners, requiring an operational SLA, security capabilities, performance, and scale not possible with current data stores. This is just one of several new workloads that are driving demand for new capabilities beyond what the legacy databases and NoSQL systems can offer.
The relational model has stood the test of time. It continues to add new innovations, such as SingleStore Universal Storage. In addition, it has absorbed the new data types (search, spatial, semi-structured, etc.) and consistency models so they can coexist in one system. There is no inherent scalability challenges with the relational model or the SQL query syntax. It just needed a different storage implementation to take advantage of a scale-out architecture.
The new databases such as SingleStore have proven that, for the majority of use cases, relational databases are easier to use and generally perform better than the NoSQL systems.
Thank you NoSQL. You put pressure on the database community to force it to solve the challenges of the cloud-scale world. It worked. Relational databases have evolved to meet those requirements. We got it from here.
Singlestore Helios and SingleStoreDB Self-Managed 7.0 are available now. You can get started instantly with SingleStore today for free or contact Sales.





