
This case study was presented as part of a webinar session by Rick Negrin, VP of Product Management at SingleStore. In the webinar, which you can view here, and access the slides here, Rick demonstrates how a major financial services company replaced Oracle Exadata with SingleStore to power portfolio analytics, with greatly increased responsiveness for users and the ability to easily incorporate machine learning models into their applications. In this case study, we’ll emphasize the bank’s digital infrastructure using Exadata, then present their implementation of SingleStore as a reference architecture that you can consider for your own organization’s needs.
This case study was originally presented as part of our webinar series, How Data Innovation is Transforming Banking (click the link to access the entire series of webinars and slides). This series includes several webinars, described in these three blog posts:
- Real-Time Fraud Detection for an Improved Customer Experience
- Providing Better Wealth Management with Real-Time Data
- Modernizing Portfolio Analytics for Reduced Risk and Better Performance
Also included are these two case studies:
- Replacing Exadata with SingleStore to Power Portfolio Analytics (this case study)
- Machine Learning and Fraud Detection “On the Swipe” For Major US Bank
You can also read about SingleStore’s work in financial services – including use cases and reference architectures that are applicable across industries – in SingleStore’s Financial Services Solutions Guide. If you’d like to request a printed and bound copy, contact SingleStore.
Case Study, Before: The Previous Architecture, with ETL, Exadata, and RAC
This case study describes an asset management company. It’s a fairly large asset management company, with about a thousand employees and probably just under a half a trillion in assets under management. They have been in business for several decades. They’ve invested heavily in a lot of different technologies, primarily in some legacy database technologies. Things were working pretty well for awhile, but as new requirements started to come in and more users are using the system, they’ve started running into trouble.
So this is what their architecture looked like. And it should be fairly familiar to most of you. They have a variety of data sources, obviously their own internal operational systems, mostly legacy databases. Combined with some external third-party data and partner data that they would bring in. As well as behavioral data from how their users are using the system, both on the web and with mobile. And all of that data was moved, via standard extract, transform, and load (ETL) processes, into a traditional data warehouse.
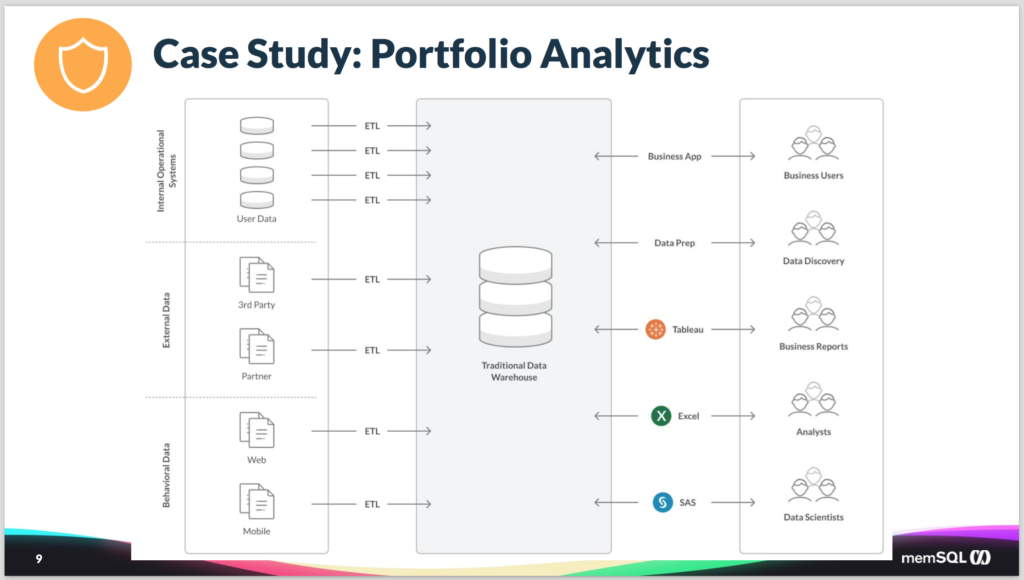
And then that data was accessed by a variety of different users. So you had business users who are using custom business applications, that are doing data exploration and doing data prep on that data. As well as business users using a combination of Tableau and Excel to do analysis. And some data scientists using SAS to do some data science and data exploration of the data. It’s trying to move the models forward.
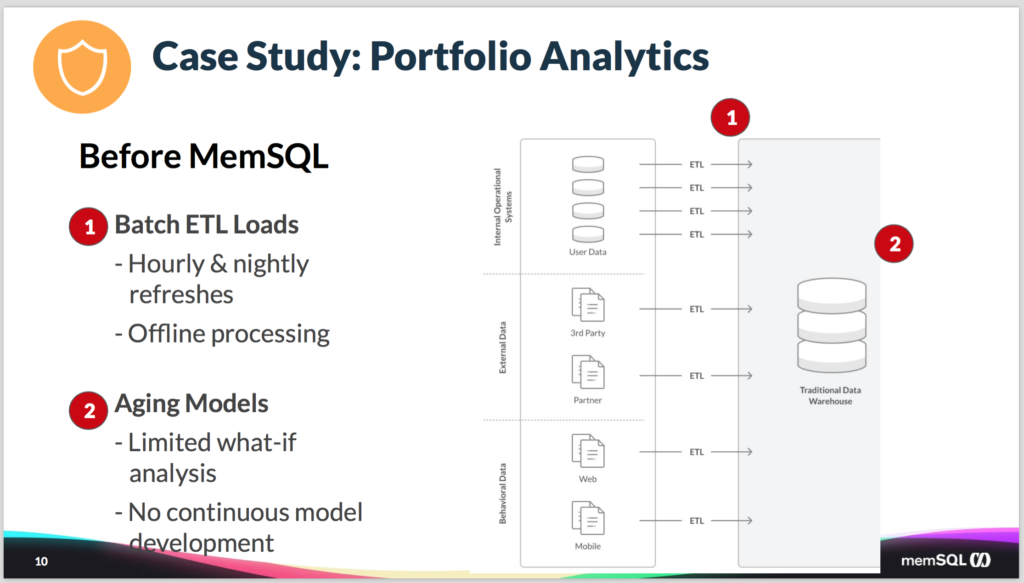
Now this resulted in a number of problems. So one is they were stuck with batch ETL. Which initially was okay, but as they’ve been trying to move to a more streaming system and more real time, this was becoming a bottleneck. And the existing database technology and the ETL technology they had, was just not sufficient. They couldn’t make it work go more often than nightly refreshes and hourly updates. This basically resulted in the system being offline whenever they would ingest large amounts of data.
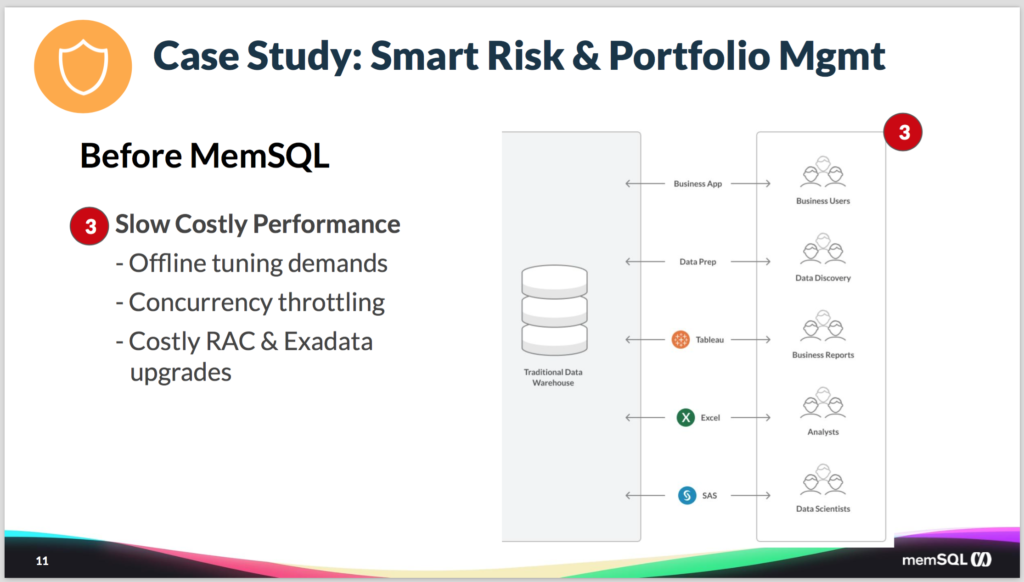
On top of that, the data models that were in use by their data scientists were aging, they were somewhat limited. It didn’t allow continuous development, so it was tough to evolve them as they learned new things and then got new data. And probably the most painful thing is that as more and more users who are trying to use the system, the queries were getting slower and slower. As concurrency ratcheted up, the queries would slow down.
On top of that, people wanted to be able to use the data all the time, not just nine to five. And so they want to be able to use this system even when the data’s loading constantly.
They tried to meet these new challenges by leveraging newer hardware, or appliances like Oracle RAC and Exadata. And those are extremely expensive, given the kind of hardware neeed to try to solve the problem.
Case Study, After: The New Architecture, with Kafka, Spark, and SingleStore
To solve these problems, they replaced the old architecture with something that looks like this. Basically with the combination of SingleStore and Kafka and Spark.
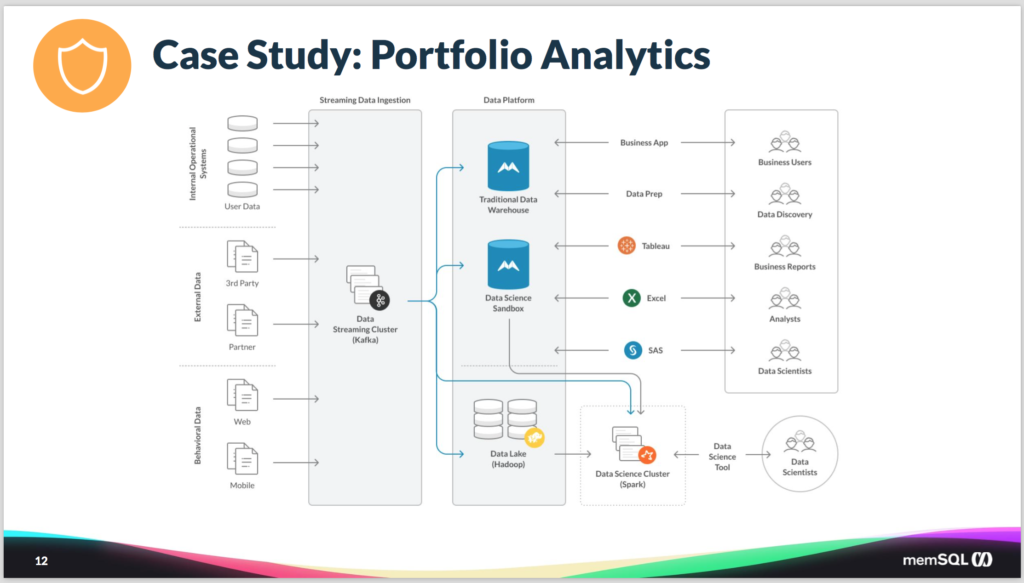
So the first step was to replace all the ETL technologies with the Kafka queue. For those who aren’t familiar, Kafka is an in-memory, distributed queue. It’s fairly easy to set up and scale and manage. And it’s a great landing place for data that’s waiting to be processed. So they changed the older data sources to funnel into a single Kafka queue. And then from there they fork the data into a couple of SingleStore instances, as well as into a data lake for long-term storage.
On top of that, they would then leverage a combination of the data that was security data and their data science sandbox SingleStore instance, as well as some data from the data lake, and pull that into a Spark cluster. So, leveraging the native integration that SingleStore has with Spark so they could train their machine learning models with the newest market data all the time, driving a continuous evolution of their machine learning algorithms. At the same time, the could continue to run queries into Tableau and Excel, continue to use SAS, and continue to run their business applications without having to disturb those approaches too much.
And lastly, they were able to get much better performance that they were getting before. They got significantly faster queries. They also, because of the more efficient use of storage and cost effectiveness, they’re able to store the required five years of history versus the three they were able to store in Oracle. And they did all this while still being three times cheaper than the cost of the Oracle solution.

To kind of summarize the benefits: the combination of Kafka, Spark, and SingleStore enabled them to do continuous trade and risk analysis using live market data, moving from batch into real time. They reduced their overall spend by 3x while still improving performance. And they have a new data platform for driving their ML and operational analytics delivery, making them much more agile and moving faster.
Conclusion
You can take a free download of SingleStore. It’s a no-time-bomb version of our product. You can deploy it to production. Of course, it is limited by its scale and the number of nodes deployed, but you can do a lot with what’s available there. And then you can get support from the SingleStore Forums, which are community-driven, but also supported by some folks here at SingleStore.





