SingleStore Universal Storage is a new vision for how databases can work – first blurring and then, for most use cases, erasing any apparent difference between today’s rowstore and columnstore tables. In SingleStore Universal Storage™ Phase 1, shipping as part of SingleStoreDB Self-Managed 7.0 (currently in beta), rowstore tables get null compression, lowering TCO in many cases by 50%. Columnstore tables get seekable columnstores, which support fast seeks and updates, giving columnstore tables many of the performance and usability features of rowstore tables. The hard choices developers have faced up to now between rowstore and columnstore tables – or between separate rowstore and columnstore database software offerings – are significantly reduced, cutting costs and improving performance. With the new system of record improvements, also offered in SingleStoreDB Self-Managed 7.0, our vision of “one database to rule them all” begins to be realized.
This is the first in a series of four articles that describe SingleStore's unique, patented Universal Storage feature. Read Part 2, Part 3 and Part 4 in the series to learn the whole story.
Introducing SingleStore Universal Storage
SingleStore Universal Storage is a breakthrough in database storage architecture to allow operational and analytical workloads to be processed using a single table type. This will simplify the developer’s job while providing tremendous scalability and performance, and minimizing costs.
As a significant first step, in SingleStoreDB Self-Managed 7.0, Universal Storage Phase 1 allows OLTP applications to use columnstore tables to run operational transactions on data much bigger than RAM. This is supported via new hash indexes and related speed and concurrency improvements for disk-based columnstore tables, delivering seeks and updates at in-memory speeds. Universal Storage Phase 1 also now supports transactional applications on larger data sets more economically, via in-memory compression for null values in fast, memory-based rowstore tables, with memory savings of roughly 50% for many use cases.
Together, these improvements give SingleStore customers better performance at lower cost, the flexibility to get the most from computing resources, and the ability to tackle the largest data management problems economically.
Our Vision for the Ultimate Table Format
SingleStore supports two types of data tables in the same database: in-memory rowstores, which are ideal for online transaction processing (OLTP) and hybrid transactional/analytical (HTAP) applications, and disk-based columnstores, which are the best choice for purely analytical applications. Customers love the speed and predictability of rowstores for OLTP and HTAP. They also love the truly incredible analytical performance of columnstores, plus their ability to store far more data than will fit in RAM economically.
But customers have been asking for us to improve the total cost of ownership (TCO) of rowstores, because they have to provision servers with large amounts of RAM when tables get big, which can be costly. They’ve also asked for us to add OLTP-like features to columnstores, such as fast UPSERTS and unique constraints. In response, we’ve developed a vision of the future in which one table type can be used for OLTP, HTAP, and analytics on arbitrarily large data sets, much bigger than the available RAM, all with optimal performance and TCO. We call this SingleStore Universal Storage.
Our ultimate goal for Universal Storage is that performance for OLTP and HTAP is the same as for a rowstore table, if the amount of RAM that would have been required for an explicitly defined rowstore table is available, and that OLTP performance degrades gracefully if less RAM than that is available. For analytics, utilizing large scans, joins, aggregates, etc., the goal is to provide performance similar to that of a columnstore table.
The old-fashioned way to support OLTP on tables bigger than RAM would be to use a legacy storage structure like a B-tree. But that could lead to big performance losses; we need to do better. In the Universal Storage vision, we preserve the performance and predictability of our current storage structures and compiled, vectorized query execution capability, and even improve on it. All while reducing the complexity and cost of database design, development, and operations by putting more capability into the database software.
In the 7.0 release, we are driving toward solving the customer requirements outlined above, and ultimately realizing our vision for a “Universal Storage” in two different ways. One is to allow sparse rowstores to store much more data in the same amount of RAM, thus improving TCO while maintaining great performance, with low variance, for seeks. We do this through sparse in-memory compression. The other is to support seekable columnstores that allow highly concurrent read/write access. Yes, you read that right, seekable columnstores. It’s not an oxymoron. We achieve this using hash indexes and a new row-level locking scheme for columnstores, plus subsegment access, a method for reading small parts of columnstore columns independently and efficiently.
In what follows, we’ll explain how we achieve a critical first step in achieving our vision for a Universal Storage in SingleStoreDB Self-Managed 7.0. And this is just the beginning.
Sparse Rowstore Compression
To address the TCO concerns of our customers with wide tables that have a high proportion of NULL values – a situation often found in the financial sector – we’ve developed a method of compressing in-memory rowstore data. This relies on a bitmap to indicate which fields are NULL. But we’ve put our own twist on this well-established method of storing less data for NULL values by maintaining a portion of the record as a structure of fixed-width fields. This allows our compiled query execution and index seeking to continue to perform at the highest levels. We essentially split the record into two parts: a fixed-width portion containing non-sparse fields and index keys, and a variable-width portion containing the fields which have been designated as sparse.
Our NULL bitmap makes use of four bits per field instead of one, to enable room for future growth. We’ve created a pathway where we can add the ability to compress out default values like blanks and zeros, and also store normally fixed fields as variable-width fields – e.g., storing small integers in a few bytes, rather than 8 bytes, if they are declared as bigints.
The following figure illustrates how sparse compression works for a table with four columns, the last three of which are designated as SPARSE. (Assume that the first one is a unique NOT NULL column, so is not designated as SPARSE). The fact that the first column is not sparse and the last three columns may be sparse is recorded in table-level metadata.
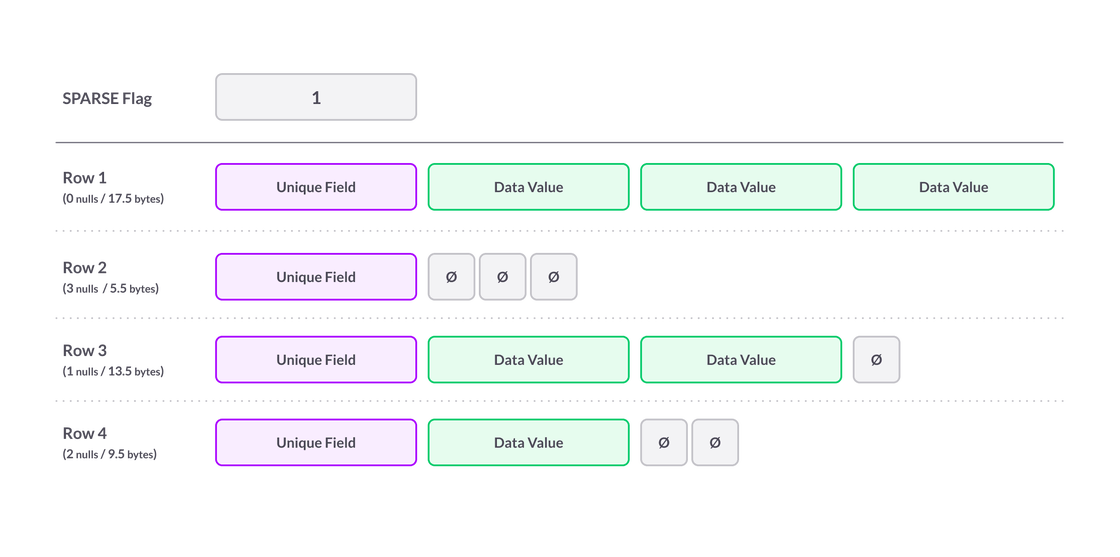
In the table, the width of the wide fields represents 32 bits and the width of the narrow fields represents 4 bits. Actual space usage also depends on the presence of indexes and storage allocation structures and can’t be easily summarized, but this illustration is a useful visual representation of space savings for sparse fields that can be NULL.
The sweet spot for SPARSE compression is a wide rowstore table with more than half NULL values. Here’s an example:
CREATE TABLE t (
c1 double,
c2 double,
…
c300 double) compression = sparse;
Specifying compression = sparse at the end of CREATE TABLE causes SingleStore to use sparse encoding for nullable structured fields, including numbers, dates, datetimes, timestamps, times, and varchars.
Using this table schema with SingleStoreDB Self-Managed 7.0, loaded with 1.05 million rows, of which two-thirds are NULL, we observe the following memory usage with no compression vs. roughly half the memory usage with sparse compression:
| Compression Setting | Memory Use | Savings (percent) |
|---|---|---|
| NONE | 2.62GB | N/A |
| SPARSE | 1.23GB | 53% |
So, for this wide table with two-thirds NULL values, you can store more than twice the data in the same amount of RAM. This of course can lead to big TCO savings, or enable you to tackle bigger problems to generate more business value with SingleStore.
The MPSQL code used to do this experiment is given in Appendix A.
Note. A handy query for calculating table memory use is:
select database_name, table_name, format(sum(memory_use),0) m
from information_schema.table_statistics
group by 1, 2;
This gives the actual memory used for each rowstore table.
Seekable Columnstores with Support for High Concurrency
To increase the scope of operational analytics and OLTP applications that can be handled with best-in-class performance and TCO with SingleStore, the sparse rowstore compression method described in the previous section can take you a long way. But it still requires all data to be kept in RAM, leading to a TCO and scale limit for some potential users. To drive to truly low TCO per row, while enabling operational applications, we’ve also enhanced our columnstore. (SingleStore’s columnstore is disk-based, with portions cached in memory for better performance.)
This enhancement, the second prong of Universal Storage Phase 1, is to make columnstores seekable. How, you ask, is that possible? Aren’t columnstores designed for fast scanning, with no thought given to making OLTP-style seeks fast enough? Based on other columnstore implementations available on the market, you might think this is the case. But SingleStoreDB Self-Managed 7.0 introduces new technology to make columnstores seekable, and updatable at fine grain with high concurrency.
First, here’s a little background on our columnstore implementation to help understand what we’ve changed. SingleStore columnstores tables are broken into one-million-row chunks called segments. Within each segment, columns are stored independently – in contiguous parts of a file, or in a file by themselves. These stored column chunks are called column segments. Prior to 7.0, accessing a field of a single row would require scanning the entire, million-row column segment for that field.
Subsegment Access
SingleStoreDB Self-Managed 7.0 speeds up access to a row in a columnstore by allowing the system to calculate the location of the data for that row, and then read only the portion of a column segment that is needed to materialize that row. This is called subsegment access. This may involve reading data for up to a few thousand rows, but it is nowhere near the full million rows of the segment. Once the offset of a row in a segment is known, only portions of that row and adjacent rows need to be retrieved, in the typical case. In some other cases, such as a run-length-encoded column, only a small number of bytes of data may need to be retrieved to materialize a column, simply due to the nature of the compression strategy. This also allows efficient seeking.
The figure below illustrates how just a portion of the file data for a segment needs to be read to find one or a few rows at a specific position in a segment.
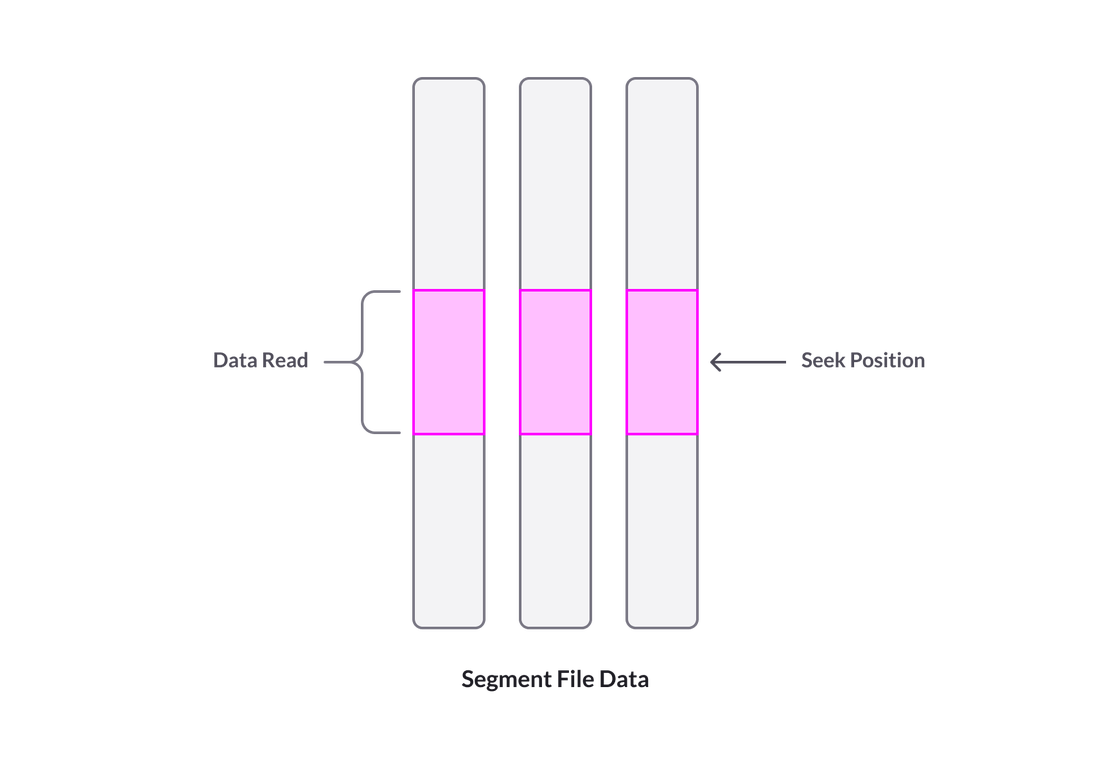
Subsegment access allows rows to be materialized efficiently via seek-style access once the row position in a segment is known. So the question is, how can we come to know the row position, and do that efficiently? One way is to scan a single column to apply a filter, and record the row numbers that match the filter. While this can be extremely fast in SingleStore, based on the use of operations on encoded data and vectorization, it can ultimately require time proportional to the number of rows.
Columnstore Hash Indexes
To run selective queries even faster, we need indexes. Hence, SingleStoreDB Self-Managed 7.0 introduces hash indexes on columnstores. You can create a hash index on any individual column in a columnstore table. Filters on these columns can thus be solved using the index. Seeks of a hash index to solve selective filters can identify the positions of the qualifying rows at a speed that’s orders of magnitude faster than a scan. Then, once the row positions are known, the new subsegment access capability is used to seek into each column referenced by the query to retrieve the data for the qualifying records.
Multi-column filters can also be solved with multiple hash indexes via index intersection, i.e. intersecting the rowid lists from multiple indexes to produce a final set of qualifying rowids.
Fine-Grain Locking for Columnstores
Now that highly-selective, OLTP-style queries can be processed fast on columnstores, what else stands in the way of highly efficient read/write access for hundreds or even thousands of transactions per second? Anything that could make these fine-grain read and write transactions wait, of course. What might they wait for? Each other.
Waiting in SingleStoreDB Self-Managed 6.8 and earlier may happen for columstore updates in conflict with other updates, based on locking at the granularity of a million-row segment. Since this granularity is somewhat coarse, that can limit total concurrency. We’ve dramatically improved concurrency in 7.0 via row-level locking for columnstores.
Performance Gains
To measure the performance of columnstore seeks through hash indexes, I created a table with 1.074 billion (1024 x 1024 x 1024) rows, which has two columns, and a hash index on each column. The two columns are in completely different orders, and each value in the column is unique, or close to it. The schema of this table is as follows:
create table f(a bigint, b bigint,
shard key(a), key(a) using clustered columnstore,
key(a) using hash, key(b) using hash
);
I created the same table on a 7.0.4 cluster and a 6.8.9 cluster, except that on the 6.8.9 cluster, the hash keys were omitted. I wrote a stored procedure to seek N times into the index and measure the average time to run the query (ignoring client-to-server communication time). This gave the following performance results.
| Column being seeked | Table size (millions of rows) | Runtime (ms), 6.8, no hash indexes | Runtime (ms), 7.0, w/hash indexes | Speedup (times) |
|---|---|---|---|---|
| a | 1,074 | 6.70 | 2.46 | 2.72X |
| b | 1,074 | 271 | 2.54 | 107X |
Notice the dramatic 107X speedup for seeking on column b, which was not ordered by the columnstore key (a). This shows the combined benefit of hash indexes and subsegment access. The key point is that the seek time on column b has gone from being too slow for a highly concurrent OLTP application (271ms) in Version 6.8, to fast enough for OLTP (2.54ms) in Version 7.0, with hash indexes. This greatly expands the kinds of workloads you can run on columnstore tables.
The MPSQL code used for these tests is given in Appendix B. You may wish to try variations of the test, such as adding more columns to the table. Of course, adding more columns will slow down the seek time, since each column will have to be accessed. But even with dozens of columns, seek time can be in single-digit milliseconds, depending on your hardware — good enough to no longer be a bottleneck for many concurrent operational applications. Moreover, even for very wide tables, say with hundreds of columns, if the query selects from one to a few dozen columns, subsegment access and hash indexes can provide single-digit millisecond row lookup times.
Design and Operational Improvements
SingleStore offers both rowstore and columnstore tables in a single database software offering, with JOINs and other operations working smoothly across the two table types. (And more so in SingleStoreDB Self-Managed 7.0.) This makes database design and operations simpler than with some competing solutions.
However, even with SingleStore, there is still complexity in choosing which table type, or set of table types, to use to solve various problems. And operations work becomes more complex as more separate tables and different table types are used.
For many use cases, Universal Storage simplifies the database design process, and therefore the level of operations work needed on the resulting implementation. These improvements are significantly realized by the improvements offered in Universal Storage Phase 1 / SingleStoreDB Self-Managed 7.0, with room to grow as Universal Storage is more fully realized in future releases.
The specifics of how these improvements affect our customers depend, of course, on the specifics of what they need to accomplish. In general, improvements include:
- Rowstore covers more requirements. Customers doing OLTP and HTAP work are sometimes forced to use columnstore for part or all of their needs because the amount of RAM required is too expensive, or impractically large. The null compression in Universal Storage Phase 1 helps considerably – as we’ve mentioned, by a factor of 2 for many of our customers. Future improvements in rowstore compression will extend these gains. (Intel’s Optane memory can help too.)
- Columnstore covers more requirements. Customers who have rowstore-type problems to solve, but are forced to use columnstore for cost or practicality reasons – or for whom columnstore is a good fit, except for a few impracticably slow operations – will find columnstore performance much improved. This improvement is quite strong in the initial implementation of Universal Storage, and also has more room to grow in future versions.
- Fewer two-headed beasts. Customers often have to put new, active data in rowstore for speed, then move it to columnstore as it ages for cost reasons, despite the complexity this adds to their applications. Or they put a subset of data in a logical table in rowstore for some operations, and the full data set in columnstore for broad analytics purposes, duplicating substantial amounts of data across table types. With Universal Storage, the need to use multiple table types often goes away. Future versions will reduce this need further, as SingleStore absorbs the former need for complex table architectures into enhancements in the database software.
Summary and Where We Go From Here
SingleStoreDB Self-Managed 7.0 introduces two major categories of enhancements that allow more data to be processed efficiently for OLTP, HTAP, and analytics workloads:
- Sparse rowstore compression to improve TCO for OLTP-style applications that need very fast and predictable row lookup times on multiple access paths, and
- Subsegment access, hash indexes, and improved concurrency for columnstore tables, to enable more OLTP-style work to function efficiently with columnstore tables that are larger than the available RAM.
The Universal Storage features we’ve built for 7.0 are a down payment on additional capabilities we envision in future releases, including:
- Hybrid row/columnstore tables that are an evolution of our existing columnstores, allowing you to tune the amount of RAM used for the updatable, in-memory rowstore segment, and have more granular index control over all parts of the data. The goal here is that customers won’t have to try to store the data in two different ways, under application control, thus simplifying application development
- Unique hash indexes and unique constraints on columnstores
- Multi-column hash indexes on columnstores
- Ordered secondary indexes on columnstores
- Rowstores to cache results of columnstore seeks
- Automatic adaptation of the size of the updatable rowstore segment of a columnstore
- A columnstore buffer pool managed directly by SingleStore, rather than simply relying on the file system buffer pool
- Rowstore compression for zeros and blanks, and variable width encoding of small values
As you can see, the SingleStoreDB Self-Managed 7.0 release delivers a big part of the Universal Storage vision. And if you get on board with SingleStore now, you can expect the speed, power, and simplicity of SingleStore to continue to grow and improve. SingleStore Universal Storage will truly become a store to rule them all!
Read Part 2, Part 3 and Part 4 in the series to learn the whole story behind SingleStore's patented Universal Storage feature.
Appendix A: Data Generation SPs for SPARSE Compression Measurement
set sql_mode = PIPES_AS_CONCAT;
-- load t using SPARSE compression
call buildTbl(300, 0.666, 1000*1000, "compression = sparse");
-- load t with no compression
call buildTbl(300, 0.666, 1000*1000, "compression = none");
delimiter //
create or replace procedure buildTbl(numCols int, sparsePercent float, nRows bigint,
compression text)
as
begin
drop table if exists t;
call createTbl(numCols, compression);
call loadTbl(numCols, sparsePercent, nRows);
end //
create or replace procedure createTbl(numCols int, compression text) as
declare stmt text;
begin
stmt = "create table t(";
for i in 1..numCols - 1 loop
stmt = stmt || "c" || i || " double, ";
end loop;
stmt = stmt || "c" || numCols || " double) " || compression || ";";
execute immediate stmt;
end //
delimiter //
create or replace procedure loadTbl(numCols int, sparseFraction float,
nRows bigint) as
declare stmt text;
declare q query(c bigint) = select count(*) from t;
declare n int;
begin
stmt = "insert into t values(";
for i in 1..ceil(sparseFraction * numCols) loop
stmt = stmt || "NULL,";
end loop;
for i in (ceil(sparseFraction * numCols) + 1)..numCols - 1 loop
stmt = stmt || "1,";
end loop;
stmt = stmt || "1);";
execute immediate stmt;
n = scalar(q);
-- Double table size repeatedly until we exceed desired number
-- of rows.
while n < nRows loop
insert into t select * from t;
n = scalar(q);
end loop;
end //
delimiter ;
Appendix B: Exercising Columnstore Hash Indexes
create database if not exists db1;
use db1;
drop table if exists f;
-- hash indexes on columnstores
create table f(a bigint, b bigint,
shard key(a), key(a) using clustered columnstore, key(a) using hash,
key(b) using hash
);
/*
-- Create table without hash indexes, for comparison
create table f(a bigint, b bigint,
shard key(a), key(a) using clustered columnstore
);
*/
-- This will keep increasing the size of f until it has a t least n rows.
-- the b column is a hash function of the a column and will
-- be unique for ascending
-- a values 1, 2, 3, ... up until 941083987-1. The data in the b column will
-- be in a different order than the a column. So you can seek on a value of
-- a and a value of b separately to show the benefit of hash indexes without
-- worrying about whether the sort key on a is skewing performance on seeks
-- on column b.
delimiter //
create or replace procedure inflate_data(n bigint) as
declare q query(c bigint) = select count(*) as c from f;
declare tbl_size bigint;
begin
tbl_size = scalar(q);
if tbl_size = 0 then
insert f values(1, 1);
end if;
while (tbl_size < n) loop
insert into f
-- use of two prime numbers in this formula for b
-- guarantees unique b for a=1..941083987-1
select a + (select max(a) from f), ((a + (select max(a) from f)) * 1500000001) % 941083987
from f;
tbl_size = scalar(q);
end loop;
optimize table f flush;
echo select format(count(*), 0) as total_rows from f;
end //
delimiter ;
-- load the data
call inflate_data(1024*1024*1024);
-- try some seeks - should take single-digit milliseconds in 7.0
select * from f where b = 937719351;
select * from f where a = 2206889;
-- show non-sortedness of column b when ordered by a.
select * from f order by a limit 100;
select * from f order by b limit 100;
delimiter //
create or replace procedure measure_q(stmt text, n int)
as
declare
q query(a bigint, b bigint) = to_query(stmt);
a array(record(a bigint, b bigint));
end_time datetime(6);
start_time datetime(6);
d bigint;
begin
start_time = now(6);
for i in 1..n loop
a = collect(q);
end loop;
end_time = now(6);
d = timestampdiff(MICROSECOND, start_time, end_time) as diff_us;
echo select format(d/n, 0) as avg_time_us;
end //
delimiter ;
-- measure seek time by seeking 100 times and taking the average,
-- seeking on b, then a columns independently
call measure_q("select * from f where b = 937719351", 100);
call measure_q("select * from f where a = 2206889", 100);