System of record capability is the holy grail for transactional databases. Companies need to run their most trusted workloads on a database that has many ways to ensure that transactions are completed and to back up completed transactions, with fast and efficient restore capability. SingleStoreDB Self-Managed 7.0 includes new features that deliver very fast synchronous replication – including a second copy in the initial write operation, atomically – and incremental backup, which offers increased flexibility and reliability. With these features, SingleStoreDB Self-Managed 7.0 offers a viable alternative for Tier 1 workloads that require system of record capability. When combined with SingleStore Universal Storage, and SingleStore’s long-standing ability to combine transactions and analytics on the same database software, SingleStoreDB Self-Managed 7.0 now offers unprecedented design and operational simplicity, lower costs, and higher performance for a wide range of workloads.
The Importance of System of Record Capability
The ability to handle system of record (SoR) transactional workloads is an important characteristic for a database. When a database serves as a system of record, it should never lose a transaction that it has told the user it has received.
In providing system of record capability, there’s always some degree of trade-off between the speed of a transaction and the degree of safety that the system provides against losing data. In SingleStoreDB Self-Managed 7.0, two new capabilities move SingleStore much further into SoR territory: fast synchronous replication and incremental backups.
Synchronous replication means that a transaction is not acknowledged as complete – “committed” – until it’s written to primary storage, called the master, and also to a replica, called the replica. In SingleStoreDB Self-Managed 7.0, synchronous replication can be turned on with a negligible performance impact.
Synchronous durability – requiring transactions to be persisted to disk before a commit – is an additional data safety tool. It does take time, but writing to disk on the master happens in parallel with sending the transaction to the replica; there is an additional wait while the transaction is written to disk on the second system. The performance penalty is, of course, greater than for synchronous replication alone.
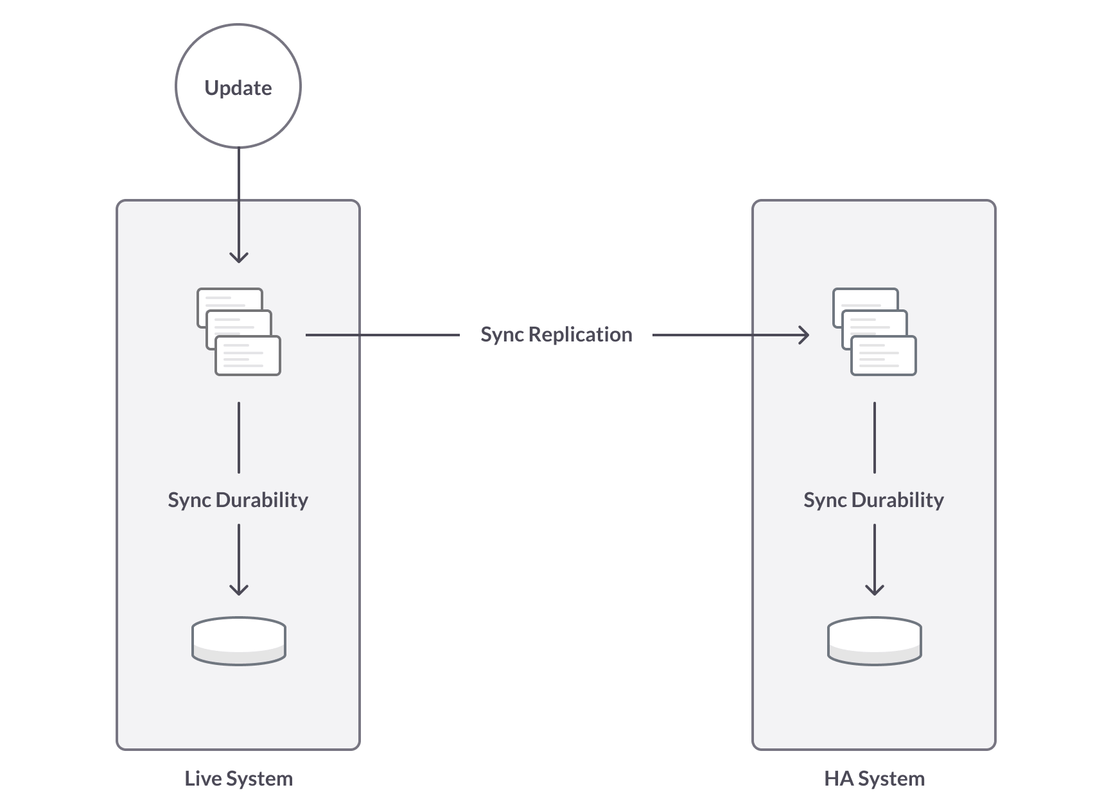
In addition to synchronous replication and synchronous durability capabilities, a system of record database needs flexible restore options. In SingleStoreDB Self-Managed 7.0, we add incremental backups, greatly increasing backup flexibility. Incremental backups allow a user to run backup far more often, without additional impact on the system. An incremental backup means only the data changed since the last backup needs to be stored. So the amount of time it takes to do the backup (and the resources required to implement the backup) are significantly reduced. This means a shorter RPO (Recovery Point Objective), which in turn means less data is lost in the event of an error that requires restoring a backup.
The rest of this blog post focuses on synchronous replication, a breakthrough feature in SingleStoreDB Self-Managed 7.0.
Sync Replication in Action
Synchronous replication in pre-SingleStoreDB Self-Managed 7.0 release was very deliberate, and quite slow. Data was replicated as it was committed. So if there were lots of small commits, you would pay the overhead of sending the data network many separate transactions with small amounts of data. In addition, data sent to the replica partition would be replayed into memory on that system, and then acknowledged by the replica to the master – and, finally, acknowledged in turn to the user. This was slow enough to restrict throughput in workloads that did many writes.
In SingleStoreDB Self-Managed 7.0, we completely revamped how replication works. Commits are now grouped to amortize the cost of sending data on the network. The replication is also done lock-free, as it is with SingleStore’s use of skiplists. Lastly, the master doesn’t have to wait for the replica to replay the changes. As soon as the replica receives the data, an acknowledgement is sent back to the master, who then sends back success to the user.
Because SingleStore is a distributed database, it can implement a highly available system by keeping multiple copies of the data, and then failing over to another copy in the event that it detects a machine has failed. The following steps demonstrate why a single failure – of a network partition, of a node reboot, of a node that runs out of memory, or of a node that runs out of disk space – can’t cause data to be lost. In the next section, we’ll describe how this failure-resistant implementation is also made fast.
To provide failure resistance, here are the steps that are followed:
- A CREATE DATABASE command is received. The command specifies Sync Replication and Async Durability. SingleStore creates partitions on the three leaves, calling the partitions db_0, db_1, and db_2. (In an actual SingleStore database, there would be many partitions per leaf, but for this example we use one partition per leaf to make it simpler.)
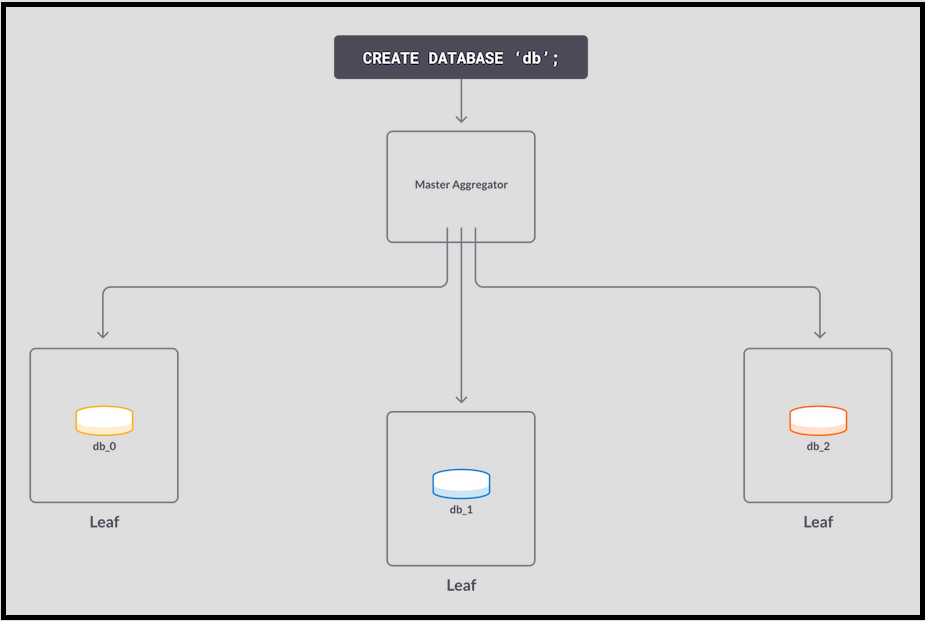
- For redundancy 2 – that is, high availability (HA), with a master and replica copy of all data – the partitions are each copied to another leaf. Replication is then started, so that all changes on the master partition are sent to the replica partition.
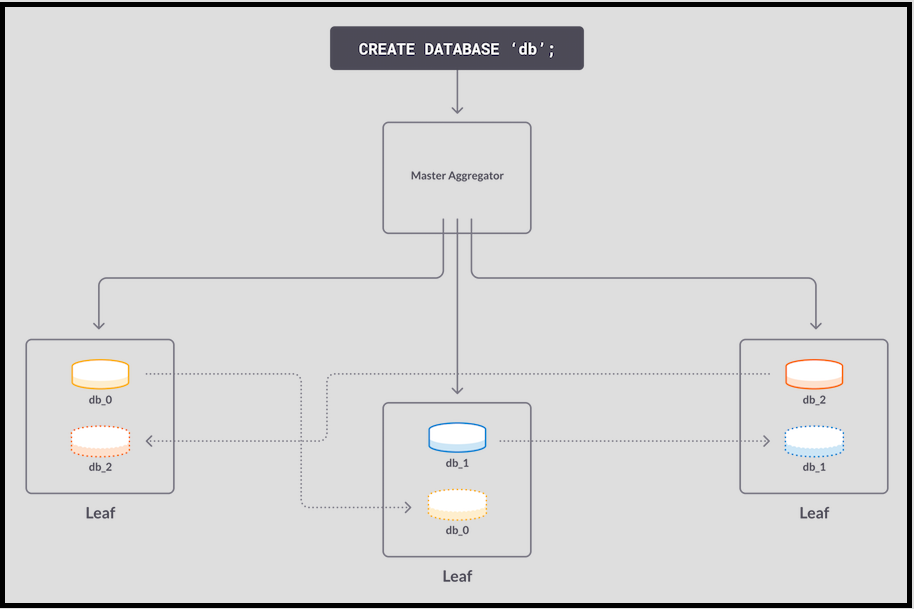
- An insert hits db_1. The update is written to memory on the master, then copied to memory on the replica.
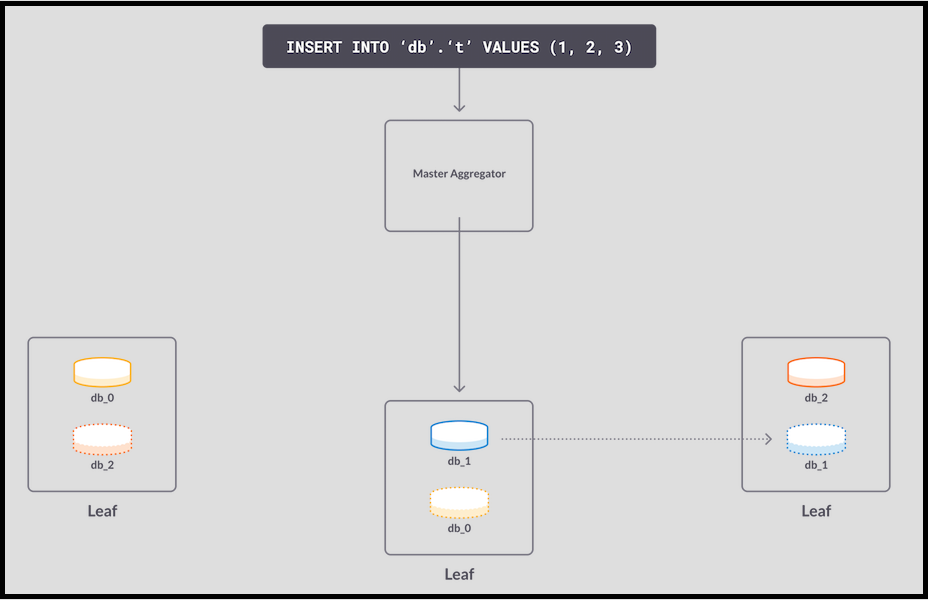
- The replica receives the page and acknowledges it to the master. The master database acknowledges the write to the master aggregator, which finally acknowledges it to the user. The write is considered committed.
This interaction between the master partition and its replica makes transactions failure-resistant. If either machine were to fail, the system still has an up-to-date copy of the data. It’s fast because of the asynchronous nature of log reply on the replica system: the acknowledgement to the primary system takes place after the log page is received, but before it’s replayed in the replica.
Making Log Page Allocation Distributed and Lock-Free
There’s still a danger to this speedy performance. Even if the number of transactions is large, if the transactions are all relatively small, they can be distributed smoothly across leaves, and fast performance is maintained. However, occasional large transactions – for instance, loading a large block of data – can potentially prevent any smaller transactions from occurring until the large operation is complete.
The bottleneck doesn’t occur on actual data updating, as this can be distributed. It occurs on the allocation of log pages. So, to make synchronous replication fast on SingleStore, we made log reservation and replication lock-free, reducing blocking. The largest difficulty in making our new sync replication was the allocation of log pages distributed and lock-free. There are several pieces that work together to prevent locking.
The first part to understand is the replication log. Transactions that interact with the replication log are as follows: Reserve, Write out log record(s), Commit.
The replication log is structured as an ordered sequence of 4KB pages, each of which may contain several transactions (if transactions are small), parts of different transactions, or just part of a transaction (if a transaction is > 4KB in size). Each 4KB page serves as a unit of group commit, reducing network traffic – full pages are sent, rather than individual transactions – and simplifying the code needed, as it operates mostly on standard-size pages rather than on variable-sized individual transactions.
To manage pages, each one is identified by a Log Sequence Number (LSN), a unique ID which begins with the first page numbered zero, then increments by one with each subsequent page. Each page has a page header, a 48 byte structure. The header contains two LSNs: the LSN of the page itself, and the committed LSN – the LSN up to which all pages had been successfully committed at the time the page in question was created. So a page could have LSN number 53, and also record the fact that the committed LSN at the point this page was created was 48 – all of the first 48 pages have been committed, but page 49 (and possibly also other, higher-numbered pages) has not been.
When a transaction wants to log something that it is doing to the log, there is an API which gives it logical space in the log and enough physical resources that it can be guaranteed not to fail, barring the node itself crashing. Next the transaction writes out into the log all the data that it wants within the log. Finally it calls the commit API, which is basically a signal to the log that the data is ready to be shipped over to the replica machine or to disk, or both.
With this background, we can look at how the log works internally. We have a 128-bit structure called the anchor in the log, which we use in order to implement a lock-free protocol for the log reservations. The anchor consists of two 64-bit numbers. One is the LSN of the current page in the log, and the other is the pointer into the page where the next payload of data can be written.
And all threads operate on the anchor using the compare-and-swap instruction, a CPU primitive which allows you to check that a particular location in memory has not changed, and then change it atomically, in one structure. It is very useful for lock-free operations, as we will see in a moment.
SingleStoreDB Self-Managed 7.0 Sync Replication Demonstration
Let’s say we have four threads, and this diagram shows the current state of the anchor. And just for simplicity I’m not going to show the second part of the anchor, only the LSN.
- With all compare and swaps, the threads working on trying to write to the log start by loading the most recent LSN, which has the value 1000.
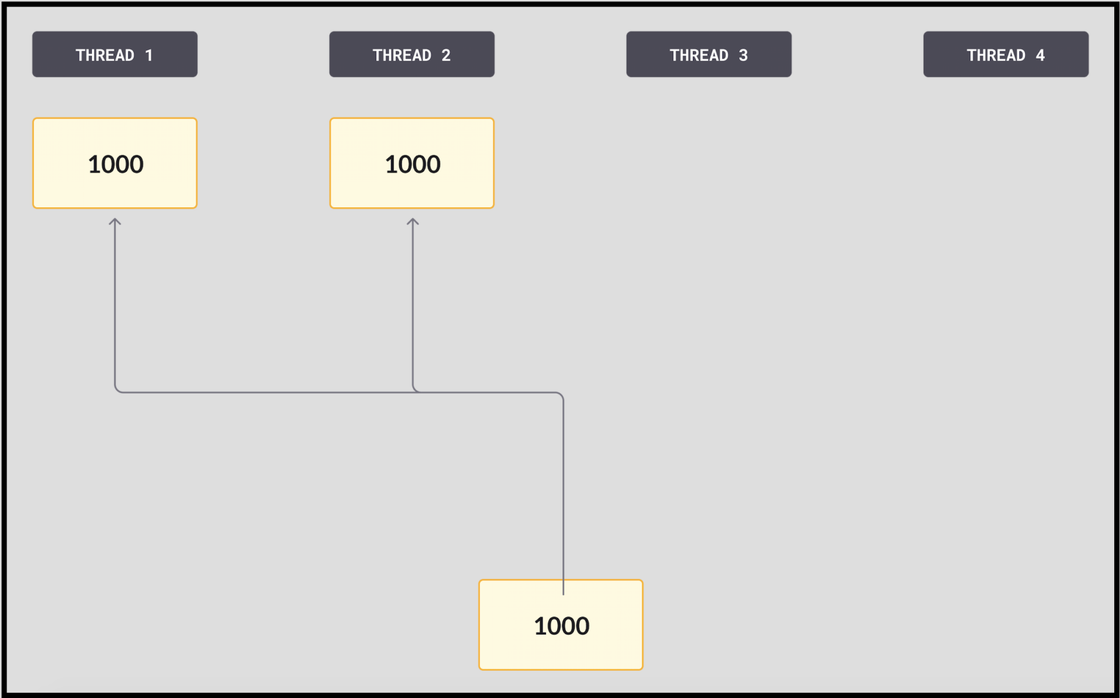
- Each thread reserves the number of pages it needs for the operation it’s trying to commit. In this case, Thread 1 is only reserving part of a page, so it wants to change the most recent LSN to 1001, while Thread 2 is reserving a large number of pages, and trying to change it to 2000. Both threads attempt to compare and swap (CAS) at the same time. In this example, Thread 2 gets there first and expects the LSN to be 1000, which it is. It performs the swap, replacing the anchor – the committed LSN – with 2000. It owns this broad swathe of pages and can stay busy with it for a long time.
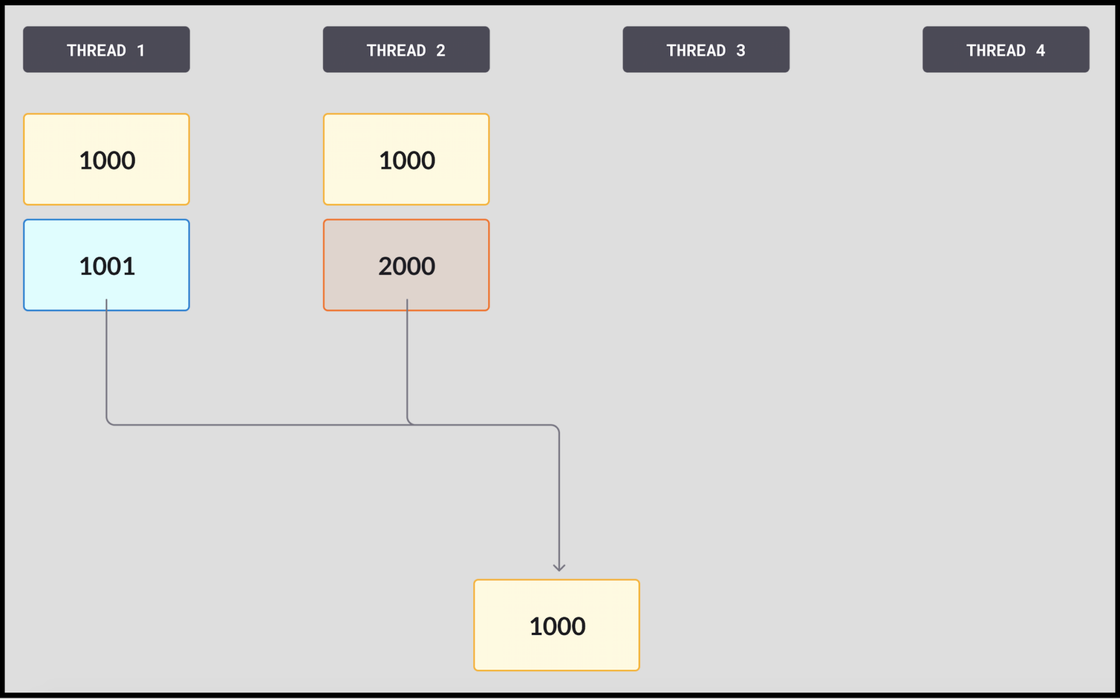
- Then Thread 1 reads the anchor expecting it to be 1000. Seeing that it’s a different number, 2000, the compare fails.
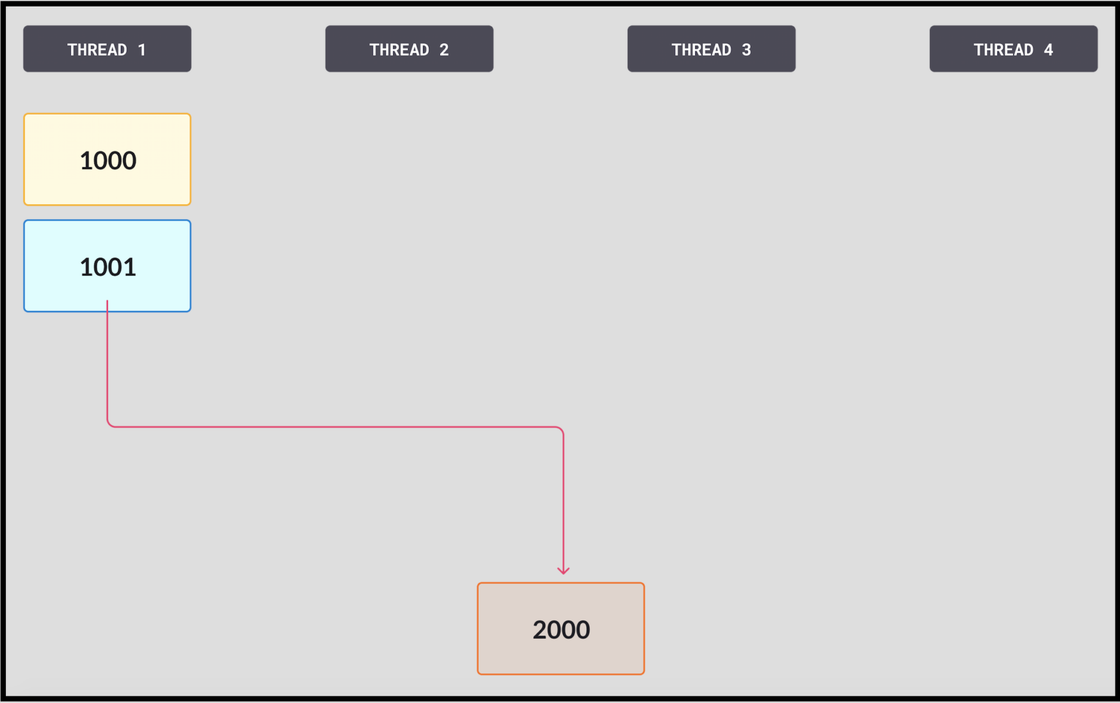
- Thread 1 tries again, loading the new value of 2000 into its memory. It then goes on to succeed.
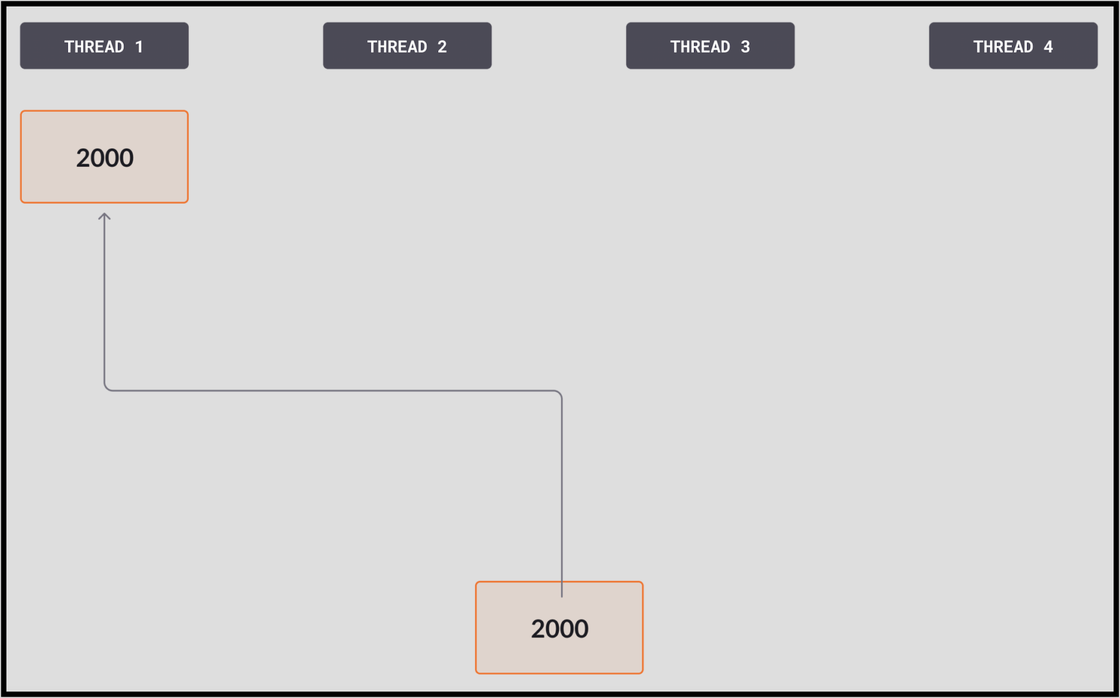
It’s important to note that the CAS operations are fast. Once a thread is successful, it starts doing a large amount of work to put its page together, write the log to memory, and send it. The CAS operation, by comparison, is much faster. Also, when it does fail, it’s because another thread’s CAS operation succeeded – there’s always work getting done. A thread can fail many times without a noticeable performance hit, for the thread or the system as a whole.
By contrast, in the previous method that SingleStore used, it was as if there were a large mutex (lock) around the LSN value. All the threads were forced to wait, instead of getting access and forming their pages in parallel. Compared to the new method, the older method was very slow.
On failovers, the master data store fails, and the replica is promoted to master. The new master now replays all the updates it has received.
It is possible that the old master received a page that was not also forwarded to the replica, because that’s the point at which the primary failed. However, with synchronous replication this is no problem – the page that only got to the master would not have been acknowledged to the user. The user will then retry, and the new primary will perform the update, send it to the new replica, receive an acknowledgement of successful receipt, and acknowledge to the user that the update succeeded.
Performance Impact
In the best case, there’s one round trip required per transaction, from user to master to replica, and back from replica to master to user. This is a low enough communication overhead that it is mostly amortized across other transactions doing work.
As we mentioned above, the cost of turning on synchronous replication is single digit percentage impact on TPC-C, a high-concurrency OLTP benchmark. This makes the performance hit of adding a much better data consistency story effectively free for most users!
The steps above show highlights, but there are many other interesting pieces that make the new synchronous replication work well. Just to name them, these features include async replication; multi-replica replication; chained replication, for higher degrees of HA; blog replication; garbage collection on blobs; divergence detection; and durability, which we’ve mentioned. Combined, all of these new features keep the impact of turning sync replication on very low, and give both the user and the system multiple ways to accomplish shared goals.
Conclusion
Synchronous replication without compromising SingleStore’s very fast performance opens up many new use cases that require system of record (SoR) capability for use with SingleStore. Also, the incremental backup capability, also new in SingleStoreDB Self-Managed 7.0, further supports SoR workloads.
We are assuming here that these will be performed using SingleStore’s rowstore tables, which are kept in memory. Both rowstore and columnstore tables support different kinds of fast analytics.
So SingleStore can now be used for many more hybrid use cases in which SingleStore database software combines transactions and analytics, including joins and similar operations across multiple tables and different table types.
These hybrid use cases may get specific benefits from other SingleStore features in this release, such as SingleStore Universal Storage. Our current customers are already actively exploring the potential for using these new capabilities with us. If you’re interested in finding out more about what SingleStore can do for you, download the SingleStoreDB Self-Managed 7.0 Beta or contact SingleStore today.