In this webinar, which you can view here, SingleStore’s Mike Boyarski describes how real-time fraud detection represents a major digital initiative for banks. He shows how SingleStore gives fraud detection services, along with other real-time analytics, an edge with faster ingest, real-time scoring, and rapid response to a broader set of events. He also describes a major US bank’s implementation of this approach, which is described separately in our case study about fraud detection on the swipe.
This webinar was originally presented as part of our webinar series, How Data Innovation is Transforming Banking (click the link to access the entire series of webinars and slides). This series includes several webinars, described in these three blog posts:
- Real-Time Fraud Detection for an Improved Customer Experience (this webinar)
- Providing Better Wealth Management with Real-Time Data
- Modernizing Portfolio Analytics for Reduced Risk and Better Performance
Also included are these two case studies:
- Replacing Exadata with SingleStore to Power Portfolio Analytics
- Machine Learning and Fraud Detection “On the Swipe” For Major US Bank
You can also read about SingleStore’s work in financial services – including use cases and reference architectures that are applicable across industries – in SingleStore’s Financial Services Solutions Guide. If you’d like to request a printed and bound copy, contact SingleStore.
New Data Initiatives for Banks
There’s a great deal of digital transformation occurring around data initiative for banks. Banks are finding a great deal of value in moving to a digital experience for their customers. Digitizing operations allows banks to deliver new services and products to the market, creating new sources of revenue.
These initiatives create pressure on existing data infrastructure, which tends to have a great deal of latency between events in the real world and insights that banks can use to drive new applications and make better decisions. Banks, like other organizations, are seeking to enable more continuous data-driven actions and decision-making. They need a data infrastructure that can adapt to those changing conditions.
More and more queries need to fit into a service level agreement window. SingleStore has customers that need all of their queries to run within a 200 millisecond requirement. And that’s ultimately to deliver the best experience for their own clients. We also see customers that want to innovate, but want to do it using the existing operations and skills.
This means augmenting or supplementing what’s already in place to keep compatibility with existing tools, existing skills – SQL and other standard technology, relational technology – and also provide a path for cloud adoption. So cloud-native technologies that work in multi cloud or hybrid cloud configurations are the technologies that we find banks are investing in.
Fraud Detection Challenges and Opportunities
The market for fraud detection is significant. It’s moving from, in this study, $14 billion in 2018 to $34 billion in 2024. This represents a recognition that fraud is becoming very challenging and it can be addressed and augmented with technology.RSA reports a 600% increase in mobile fraud over the last three years. So obviously as more transactions are occurring on mobile channels, the reality of fraud occurring on that sort of engagement path is going up.

Fraud is also very broad. Fraud applies to online payments, detecting insider trading, building or creating new accounts, and the synthetic identity issue, which is fake accounts using a blend of different information from hacked information. This creates a very complex hard problem for banks to mitigate, but also they want to provide the best possible experience to their customers to compete. Banks have to figure out that balance between enabling a frictionless digital experience but also protecting the assets of the business.
Fraud detection is very much powered by analytics, the ability to apply data to detection through anomaly detection, or predictive classification, or clustering. Where the battle really gets fought is identifying the appropriate model and analytic functions to identify something to block or approve. Having the sort of advanced analytics powered by big data to find the best fit, to find the most accurate models, that’s where a lot of the art and science of fraud detection exists. You can see more about this in our case study of a bank’s fraud detection application, where they have moved from overnight fraud processing to checking for card fraud in real time, on the user’s card swipe.
SingleStore Overview
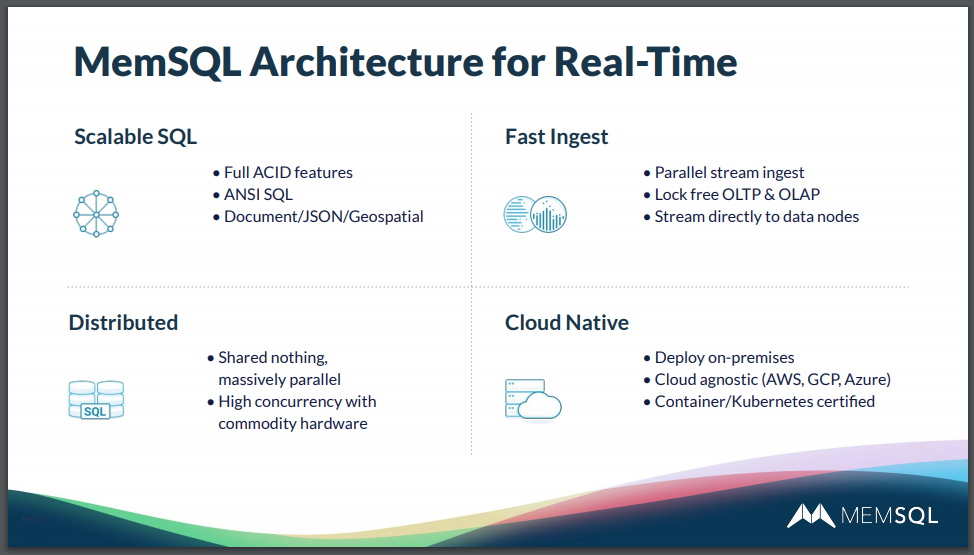
What makes SingleStore a great solution for something like fraud detection? SingleStore describes itself as the “no-limits database” because of the software’s architecture. Ultimately we have a distributed scale-out system, so our ability to support growing workloads and the growth in data is baked in, because it’s just a node-based scale-out system. SingleStore also has an innovative lock-free architecture, supporting the continuous ingestion and continuous data movement that are part of what we call operational analytics applications. SingleStore is an operational database that can do very fast analytics.

Machine learning (ML) and AI can bring a great deal of value to the business, so we see a lot of customers taking advantage of real-time ML with SingleStore. And we see a lot of customers making a transition from their legacy, on-premises architecture to the cloud, and doing it in a flexible, adaptable way. You can run SingleStore and deploy that on any cloud and/or on your own on-premises infrastructure; it’s all about flexibility.
SingleStore’s claim to fame is around delivering speed, scale, and SQL all in one package. Think of our system as being able to efficiently take data into the platform and then run queries on that data as fast as any data warehouse product in the market, including both legacy platforms like Teradata and Vertica, and some of the newer cloud-based data warehouses.
SingleStore came into existence about five or six years ago. So we were built in the cloud. We took advantage of distributed processing, all the sort of cloud-native functions that you would expect, like Kubernetes and containers, making SingleStore a really good choice for those modern cloud-based platforms.
Q&A
How does SingleStore compare to Cassandra?
Cassandra is used pretty heavily in the fraud detection market, and it’s largely because of the ingest … The ability to ingest data into Cassandra is very solid. The challenge with Cassandra, though, is if you want to do any sort of advanced additional query logic, we have found that customers really have a hard time getting insights out of Cassandra. So it’s okay for running a well-defined analytic function, but if you want to change that analytic function or iterate it quickly, that’s where the limitations come into play.
Cassandra is a NoSQL system. That means their support for joins, and their ad hoc query support, and their ability to run additional sort of query functions and analytic functions, it’s not standard, right?
At SingleStore, we are on par, if not better, with the ingest requirement. And then what’s the best about SingleStore is you’re getting a relational SQL environment, whereas with Cassandra, you’re getting their own custom implementation of SQL, which means you have to learn their language. So you’re getting a little bit more complexity around doing more continuous improvement of the analytics.
So the takeaway is, you get the same ingest performance as Cassandra, but then you get the power of SQL using the SingleStore platform.
Can you explain how SingleStore works with Kafka?
Yes. In terms of ingest, SingleStore does have support for a number of sort of ingest techniques, whether it’s file systems, S3 – and SingleStore has a built-in connector to Kafka. So what that means is, you can, in a very simple way, using one command line function called “start pipeline,” it essentially automatically configures and identifies the connection point from your Kafka topic into SingleStore. It’s very easy to set up; there’s not a lot of hand-wringing and custom coding required to connect a Kafka environment to SingleStore.
And then out of the box, you get exactly-once semantics, you get extremely high throughput, and then you can do really sort of fun things like put stored procedure logic onto the Kafka stream process so that you can do scoring on the stream, for example, if you’d like. You can also do pretty advanced things around doing logic on the data movement of Kafka into SingleStore, for example to identify where to land the data, particular on a node basis or into a particular type of table.
So there’s a lot of power that you can get with Kafka and SingleStore. It’s probably the reason why, I think, it’s probably the number one ingest technology that’s used in conjunction with SingleStore. It’s a top-notch feature, and it’s really well regarded within our community.
Can SingleStore be used with Hadoop? And how do customers typically deploy in that kind of environment?
So Hadoop we see more and more being used as an archive storage layer. So we can do a couple things with Hadoop. One is you can stream data into both SingleStore and Hadoop concurrently. (As shown in this case study – Ed.) It’s your classic Lambda-style architecture. And so that means you can use SingleStore to do your analytics on the most current active data, and then your Hadoop cluster can be used for other types of analytics, more data science oriented or just archival style analytics.
We do see some customers also landing data first into Hadoop, and then they use the HDFS connector to pull data from HDFS into SingleStore. And you can do that in a continuous fashion. So there’s an ability to stream data from Hadoop directly into SingleStore, and that allows for sort of, land once and then pull into SingleStore for spot queries, or maybe a segment of queries, or a segment of data. And then when that period of time ends or that query sort of project goes away, you can flush the data of SingleStore and keep all your data in HDFS.
So there are a lot of different ways that people use SingleStore with Hadoop. And it has a lot to do with the application and the query requirements that you have. But I guess the net of it all is our HDFS pipeline is super robust and very commonly used to accelerate query performance of Hadoop. You get the nice relational SQL structure, all that interactive query response that you want.
Conclusion
You can take a free download of SingleStore. It’s a no-time-bomb version of our product. You can deploy it to production. Of course, it is limited by its scale and the number of nodes deployed, but you can do a lot with what’s available there. And then you can get support from the SingleStore Forums, which are community-driven, but also supported by some folks here at SingleStore.