
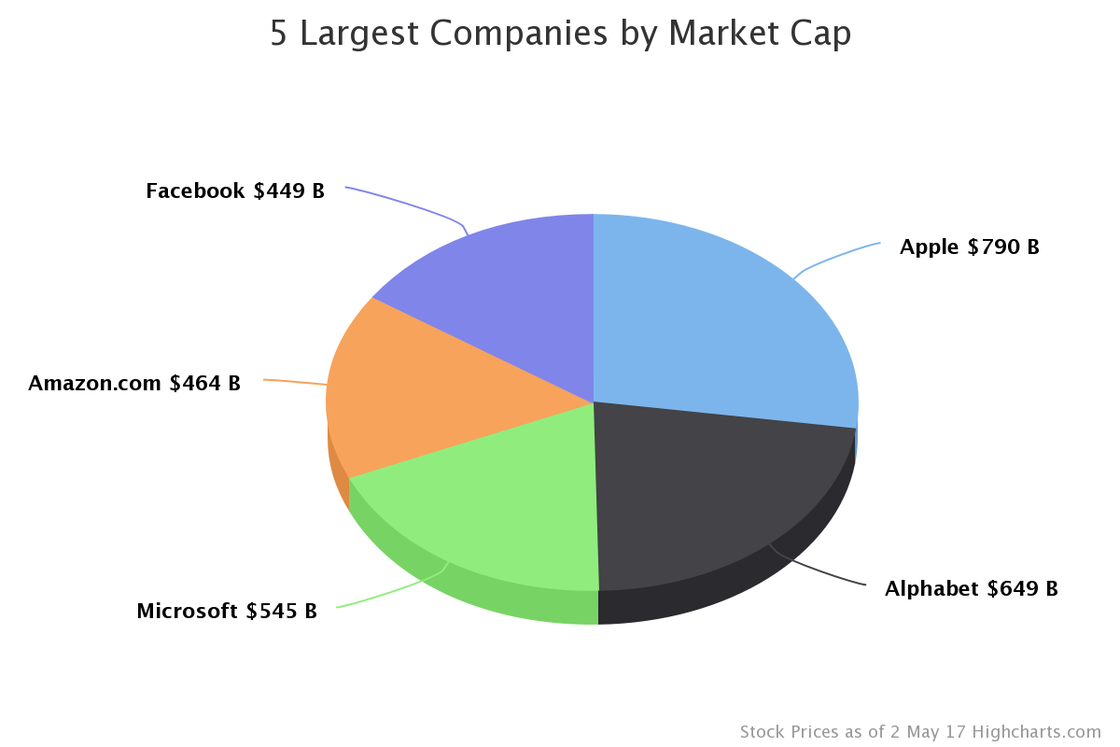
Data is fueling the world’s most valuable companies. Today the list is topped by Apple, Google, Microsoft, Amazon, and Facebook. These top companies harness data to drive outsized value. While the companies are unique, they share a more common approach to analytics than you might expect.
The Rapid Rise of Data Capture for Analytics
In a short span, entire industries have been born that didn’t exist previously. Each of these areas is supported by one or more of the world’s largest companies
- App stores from Apple and Google
- Online music, video, and books books Apple, Google, and Amazon
- Seller marketplaces from Amazon.com
- Social networks from Facebook
These areas have common characteristics driving the data workloads
– Incredibly large end user bases numbering hundreds of millions
– A smaller (but still large) base of creators or sellers
The platform providers (Apple, Google, Amazon, Facebook) seek analytics for
– Themselves
– the content producers or sellers
– and often all the way to the end users
All of these characteristics culminate in a stack that starts with the platform provider, extends up to the creators or sellers, and ends with consumers. At each level, there is a unique analytics requirement.
The App Store Example
Let’s use the App Store example to explore analytics architectures across this type of stack. App Stores are also an ideal example of new workloads that require a fresh approach to data engineering.
App Store Characteristics
The largest App Stores have the following characteristics
- 100s of millions of end users
- Millions of application developers
- Dozens of app segments
- One primary platform provide (Apple, Google)
App Stores also represent a large, fast-growing segment of the economy. According to a recent article in the San Francisco Chronicle based on data from analytics firm App Annie, both Apple and Google are growing, with Android taking a recent lead.
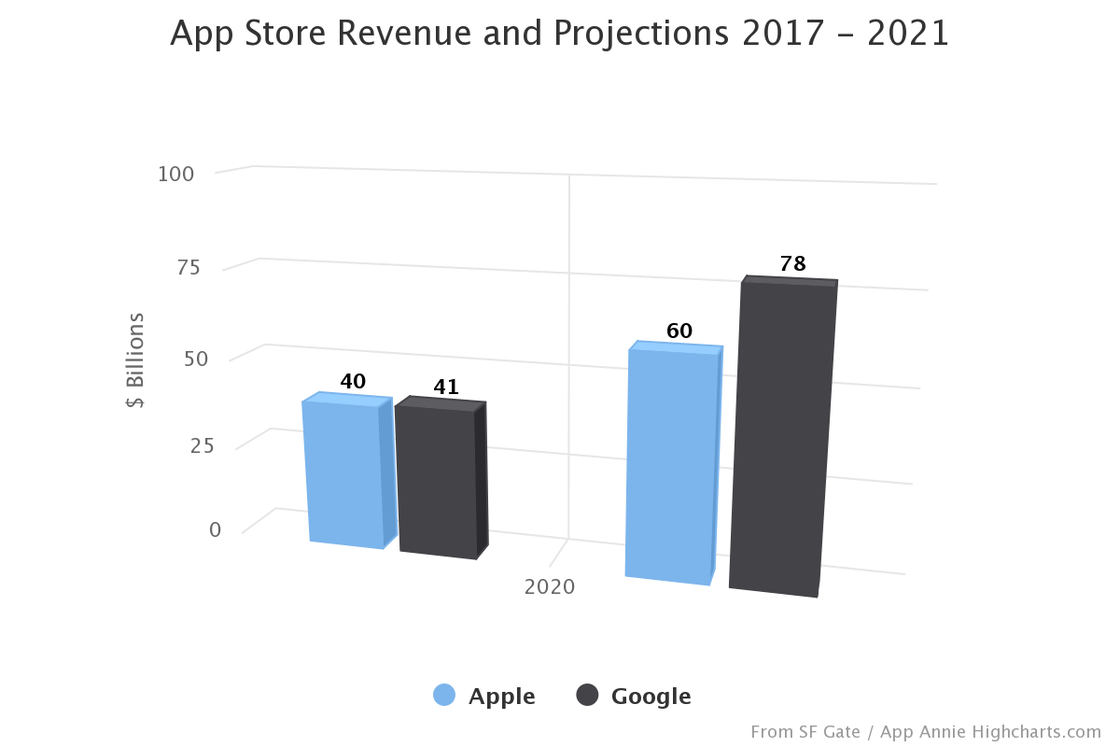
This year, things are changing: Android app distributors will leap ahead of the App Store, according to projections by analytics firm App Annie. In 2017, the App Store will generate $40 billion in revenue, while Android app stores run by Google and other parties will generate $41 billion, App Annie said. That gap is expected to widen in 2021, with Android app stores generating $78 billion and Apple’s store at $60 billion, according to the analytics firm’s report, which was released on Wednesday.
Data Workloads from App Stores
App Store workloads produce and collect information on
**1) The distribution of apps to end users
- App data coming from each app from each end user**
– Transactional data
– Log data
Desired Data Engineering Capabilities
To meet the needs for comprehensive, and multilevel App Store analytics, data solutions need to provide
Fast data capture
Including the ability to ingest data in real-time
Low latency query capability
To support sophisticated queries with sub-second responses
High concurrency
Enabling many users to access the system simultaneously without slowdown

Desired Analytical Capabilities
To serve all levels of requirements, App Stores (and many other areas with similar characteristics) need to deliver
Analytics for the platform
– Real-time analytics to understand operationally what is happening at any moment
– Ad hoc analytics for impromptu drill downs on specific queries
Analytics for app developers
– This includes ad hoc queries, so developers can segment the data any way they want
– With traditional solutions, serving many groups of analytics users often required pre-computing results. But this negated the option for ad hoc analytics
Analytics for end users
– Responsive, lightweight analytics for hundreds of millions of users, such as what apps are installed and up to date
Analytics Architecture Strategies
For App Stores, or any other large data-driven business, the following goals and implementation approaches can make analytics at scale easier to achieve.
Goals
Multilevel
A multilevel approach provides analytics across the platform, developers, and end consumers. Using the appropriate indexing and sharding approaches, the platform provider can architect a solution to meet the needs of all three constituents
Self-service
Empowering self-service analytics ensures that results are instant and up-to-date without the cost and complexity of pre-computing
Implementation recommendations
Use a scale-out distributed system
A distributed system can support both the speed and volume required for large scale analytics. Further the right indexing and sharding allows for queries to be segmented appropriately. For example, if thousands of developers are each issuing queries about data regarding their own applications, those queries can be directed to data partitions specific to those developers, and not the entirety of the distributed system. This approach allows a high degree of concurrent access.
Ensure a modern query execution system
Newer systems include features such as
– Code compilation to facilitate sub-second responses on repetitive queries
– Distributed joins for efficient operations across multiple tables
– Vectorization to take advantage of the latest CPU capabilities such as Single Instruction Multiple Data (SIMD)
– Bundle transactions support for enable real-time analytics
In a real-time world, there is no time to wait for lengthy Extract, Transform, and Load processes. Using a system that supports transactions as well as analytics allows data to be analyzed in place.
Get Started Today
If you are interested in building your own multilevel analytics solution visit www.singlestore.com






