
This case study was originally presented as part of a webinar session by Mike Boyarski, Sr. Director of Product Marketing at SingleStore. It’s been updated to include additional information and references. In the webinar, which you can view here, and access the slides here, Mike describes the challenges facing financial services institutions which have decades’ worth of accumulated technology solutions – and which need to evolve their infrastructure immediately to meet today’s needs. In this case study, which was also described in the webinar, Mike shows how a major US bank created a new streaming data architecture with SingleStore at its core. Using SingleStore enabled them to move from overnight, batch fraud detection to fraud detection “on the swipe,” applying machine learning models in real time. He presents a reference architecture that can be used for similar use cases, in financial services and beyond.
This case study presents a reference architecture that can be used by leading retail banks and credit card issuers to fight fraud in real time, or adapted for many other real-time analytics use cases as well. In addition, it describes how SingleStore gives fraud detection services an edge by delivering a high-performing data platform that enables faster ingest, real-time scoring, and rapid response to a broader set of events. A similar architecture is being used by other SingleStore customers in financial services, as described in our Areeba case study.
This case study was originally presented as part of our webinar series, How Data Innovation is Transforming Banking (click the link to access the entire series of webinars and slides). This series includes several webinars, described in these three blog posts:
- Real-Time Fraud Detection for an Improved Customer Experience
- Providing Better Wealth Management with Real-Time Data
- Modernizing Portfolio Analytics for Reduced Risk and Better Performance
Also included are these two case studies:
- Replacing Exadata with SingleStore to Power Portfolio Analytics
- Machine Learning and Fraud Detection “On the Swipe” For Major US Bank (this case study)
You can also read about SingleStore’s work in financial services – including use cases and reference architectures that are applicable across industries – in SingleStore’s Financial Services Solutions Guide. If you’d like to request a printed and bound copy, contact SingleStore.
Real-Time Fraud Case Study
This application is a credit card solution. The SingleStore customer was looking to deliver a high-performance, agile fraud detection platform using standard SQL, with challenging performance requirements. And so I’ll talk about what that means around agility and some of the sort of performance demands they have.
The customer has a time budget of one second from the time the card is swiped to the approval or refusal. There’s a very sort of sophisticated set of queries that need to be run in a very short window of time. They have about a 50 millisecond budget to work with to run a number of queries. In this application they are looking at about a 70-value feature record. And so we’ll spend a little bit of time on how that looks.
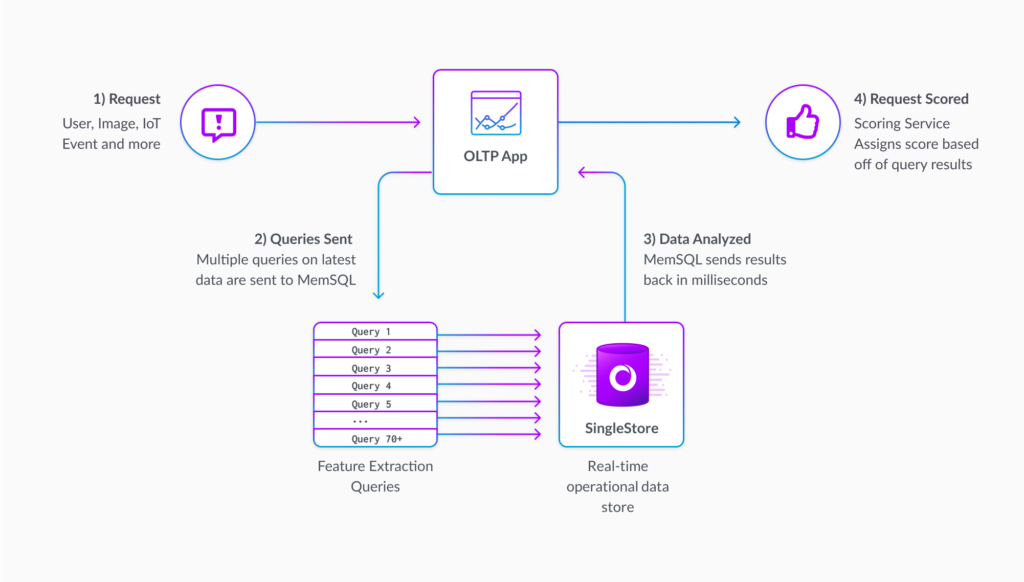
Processing starts with a request, which is a transaction at a terminal or a point of sale system. The request hits, and that event is collected into the bank’s online transaction processing (OLTP) application. That’s a transactional operational database that is collecting that information. And that request is then converted by that OLTP app into a number of disparate queries.
There are various models that they have to identify this event and match it against a number of other activities that may have occurred over time. And in this application, again, it’s roughly 70 queries that are being run. And so it’s running events like trying to identify engagement between this customer and that vendor over the past days, months, and years. They’re trying to identify a trend around that customer and that merchant. They’re also looking at other activity, like geolocation event information about prior sort of transactions and the location that the event is taking place in.
Without listing every single query, there is a distinct set of queries that are being run all in parallel against a reference store, which is on SingleStore. SingleStore is the real-time operational data store. And so this is all about delivering a check against a fairly sophisticated model to do a score. And so the data is analyzed in SingleStore. We’ll score against the 70 odd queries and provide essentially, at the end of the day, a yes or no against that most recent transaction. And so that scoring service can occur within the timeframe that they required, which is around a 50 millisecond window.
And what, ultimately, this particular customer was looking to do was get to more agility so that they can add even more feature extraction queries over time, so that can continue to optimize their model using continuous insights from their data. Think about this as a continuously moving model that needs to adjust to the insights that they’re gaining on the different and new fraud prevention techniques that some of their customers are taking advantage of.
And so when you compare and contrast the previous solution that they were using before SingleStore, they were taking advantage of nightly batch jobs and accumulating these feature records for each customer, doing analysis overnight and trying to identify if the score in fact was correct or not. As any of you know who’s ever lost their credit card or debit card details, a fraudster can accumulate multiple charges in a day, if the check doesn’t occur until nighttime. So fraud events were getting through the system, resulting in lost revenue.
And also, the other challenge that they had was they couldn’t easily change their fraud model. So their iterating of features and adding new queries was very slow in their sort of update process. When they could identify a profile or fingerprint of fraudulent activity, it took them, in some cases, many weeks to make an update to the system in order to catch that source or type of fraud on an ongoing basis or a go-forward basis.
SingleStore’s Advantages for Real-Time Fraud Detection
As a result, they had a number of reasons for moving to SingleStore. One was that they wanted to get to a fairly sophisticated number of queries running concurrently, all within this 50 millisecond window. That was something that was not possible for them with the previous system. That system was inconsistent, so they weren’t getting reliable performance.

What they got from SingleStore that they are really excited about is the ability to add new features to their model scores using standard SQL, and do that an a more iterative basis. So this was giving them the flexibility to do further updates to their platform without having to re-engineer the system or wait for a lengthy sort of change management process that was part of their prior system. And a lot of the issues with the previous system had to do with the fact that they were using some technologies that were non-standard, meaning non-SQL or non-relational based.
And so, ultimately what they are able to model out was that this continuous improvement and this real-time sort of refinement was going to save them literally tens to potentially hundreds of millions of dollars and sort of lost fraud events. So for them, it’s all about getting more agile with their fraud detection platform using standard SQL, getting the great performance so that their customers don’t notice any disruption in their experience and service, and then of course saving money and making money from that more advanced service.
SingleStore Overview
SingleStore is used by a lot of banks, because a lot of banks like the performance of SingleStore. They like the familiar relational SQL. And we typically see us beating out the competition on a price/performance basis on a regular basis.
This diagram sums up SingleStore’s features. We jokingly call it a “markitecture” diagram, because it sums up our selling points in a form that relates to a lot of the reference architectures we derive from customer implementations of SingleStore.
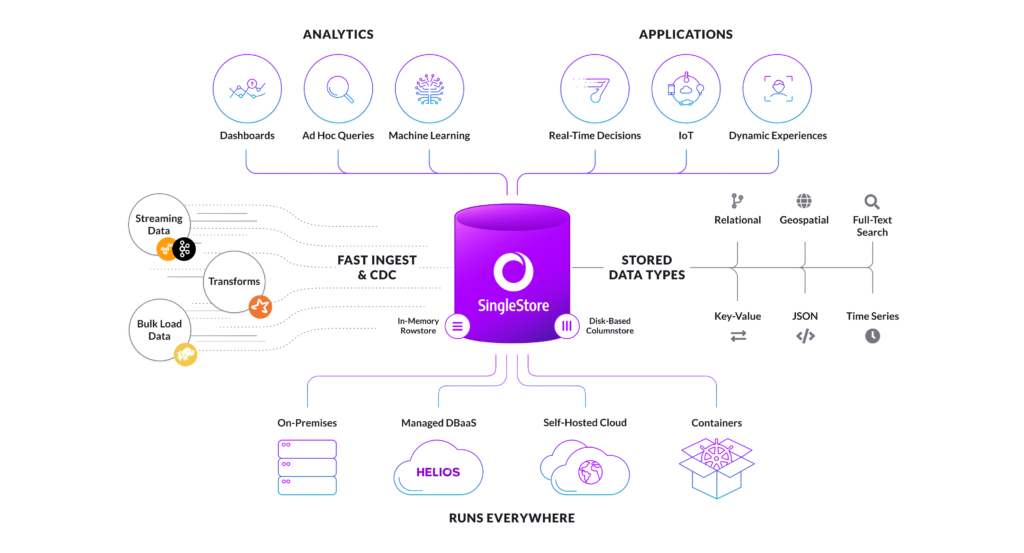
Our claim to fame is around delivering speed, scale, and SQL, all in one package. So of course most databases will say they’re fast, but I would argue that SingleStore is probably the world’s fastest database, because of our ability to really optimize the entire pipeline of data to the platform. So that includes ingestion. We have a lock-free architecture, so that means we can handle streaming events from Kafka or custom application logic and/or change data capture (CDC) logic.
So just think of our system as being able to efficiently take data into the platform and then run queries on that data as fast as any data warehouse product in the market. That includes the great legacy platforms like Teradata and Vertica and others, and also some of the newer cloud-based data warehouses. We are fast, we have a strong columnstore engine that’s disk-based, along with a strong rowstore engine that runs in memory. I’ll talk a little bit about our underpinnings and our architecture in a moment, but it’s all about speed, getting data in, and then once the data has landed, running those queries as quickly as possible.
I mentioned earlier about SingleStore’s scale, which is powered by our distributed scale-out architecture. It’s a node-based, shared-nothing architecture. That’s what makes SingleStore really, really fast. And we believe strongly in relational SQL, because we think that’s the easiest way to get data out of your system. It works really well with existing tools. But also, more importantly, it works with the skill set that already exists inside most organizations.
In terms of our architecture and ecosystem support, as you can see on the left, we can ingest data from a variety of sources: Kafka, Hadoop/HDFS, AWS S3, Spark, and custom file systems. So our ingestion technology is top notch, and that’s another reason why a lot of customers, mostly banks, really like our platform. It works very well for those types of high-ingest environments.
And then once data lands into SingleStore, we have two different storage engines. You have an in-memory based rowstore that’s really fast for point look-ups, transactions, and is fully ACID compliant. And of course we also have a columnstore engine that looks and feels like a traditional data warehouse. So great compression, it can query and do fast aggregate queries. We did a performance test on a trillion row scan in a second. So it’s very, very fast for data warehousing type jobs as well.
And SingleStore has all the flexible data types that you would expect of a modern database, whether it’s JSON, whether it’s relational structure, key-value, time series, etc. Our deployment flexibility is mostly based on our Kubernetes and container support. You can run us on anything, whether that’s in the cloud or on your own, on-premises infrastructure. Of course, if you want to run it on bare metal or any other Linux environment, you can do that as well.
Lastly, getting into a little bit more depth on our architecture, we are fully ACID compliant. That means that transactions can be committed, guaranteed, and logged to a disc. We treat every event as its own entity. SingleStore is fully ANSI SQL-compliant, and we have all of the flexible data type support that you would expect of a modern database.
SingleStore’s ingestion is, again, world-class. We can do parallel stream ingest, we can ingest directly to rowstore, or columnstore, or both. It depends on your application needs. And that’s ultimately why customers really like the platform, is it gives you the flexibility to determine what’s the best outcome, the best process flow to get the SLA result that you need.
We are a shared-nothing, massively parallel, highly concurrent database. Which means that, if you’ve got lots of users accessing your system or lots of data ingestion points coming into the system, concurrency for our platform, unlike most other platforms, is really not a challenge.
That wraps up the story of how SingleStore is being applied to real-time fraud detection. While there’s a lot of depth that can be gone into around the types of functions and queries that are required of a fraud detection application, our goal here today was to give you a starting point to understand how we fit for this real-time fraud application.
We invite you to learn more about SingleStore at SingleStore.com, or give us a try for free at SingleStore.com/cloud-trial/.





