
Why did the world need SingleStore? In this blog post, updated from a few years ago, early SingleStore Product Manager Carlos Bueno explains why SingleStore works better, for a wide range of purposes, than a NoSQL setup. (Thanks, Carlos!) We’ve updated the blog post with new SingleStore product features, graphics, and relevant links. To wit, you should also see Rick Negrin’s famous blog post on NoSQL and our recent case study on replacing Hadoop with SingleStore.
Tell us if this sounds familiar. Once upon a time a company ran its operations on The Database Server, a single machine that talked SQL. (Until the advent of NewSQL, most relational database systems – the ones that support SQL – ran on a single core machine at a time. – Ed.) It was tricked out with fast hard drives and cool blue lights. As the business grew, it became harder for The Database to keep up. So they bought an identical server as a hot spare and set up replication, at first only for backups and failover. That machine was too tempting to leave sitting idle, of course. The business analysts asked for access so they could run reports on live-ish data. Soon, the “hot spare” was just as busy – and just as mission-critical – as the master server. And each machine needed its own backup.
The business grew some more. The cost of hardware to handle the load went way up. Caching reads only helped so much, and don’t get us started about maintaining cache consistency. It was beginning to look like it would be impossible for The Database Server to handle the volume of writes coming in. The operations people weren’t happy either. The latest semi-annual schema change had been so traumatic and caused so much downtime that they were still twitching.
It was then that the company took a deep breath, catalogued all their troubles and heartache, and decided to ditch SQL altogether. It was not an easy choice, but these were desperate times. Six months later the company was humming along on a cluster of “NoSQL” machines acting in concert. It scaled horizontally. The schemas were fluid. Life was good.
For a while, anyway. It turned out that when scaled up, the NoSQL cluster worked fine except for two minor things: reading data and writing data. Reading data (“finding documents”) could be sped up by adding indexes. But each new index slowed down write throughput. The business analysts weren’t about to learn how to program just to make their reports. That task fell back onto the engineers, who had to hire more engineers, just to keep up. They told themselves all this was just the price of graduating to Big Data.
The business grew a little more, and the cracks suddenly widened. They discovered that “global write lock” essentially means “good luck doing more than a few thousand writes per second.”
A few thousand sounds like a lot, but there are only 86,400 seconds in a day, and the peak-hour of traffic is generally two or three times the average – because, people sleep. A limit of 3,000 writes per second translates to roughly 90 million writes a day. And let’s not talk about reads. Flirting with these limits became as painful as the database platform they’d just abandoned.
Tell us if this sounds familiar. I’ve seen a lot of companies suddenly find themselves stuck up a tree like this. It’s not a fun place to be. Hiring performance experts to twiddle with the existing system may or may not help. Moving to a different platform may or may not help either. A startup you’ve definitely heard of runs four – count ‘em, four – separate NoSQL systems, because each one had some indispensable feature (eg, sharding or replication) that the others didn’t. That way lies madness.
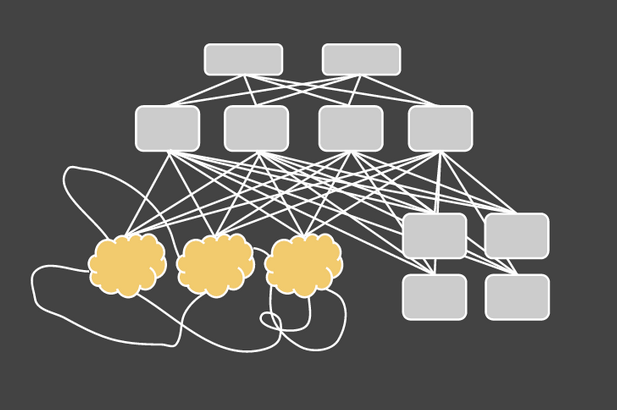
Let’s look at the kinds of hardware running Hypothetical Corp’s business.
- 50 application servers (lots of CPU)
- 10 Memcached servers (lots of RAM)
- Four NoSQL servers (lots of disk)
The interesting thing is that Hypothetical has several times more RAM in its fleet than the size of their database. If you ask them why, they’ll tell you “because accessing data from RAM is much faster than from disk.” This is, of course, absolutely true. Accessing a random piece of data in RAM is 100,000 times faster than a spinning hard disk, and 1,000 times faster than from SSDs.
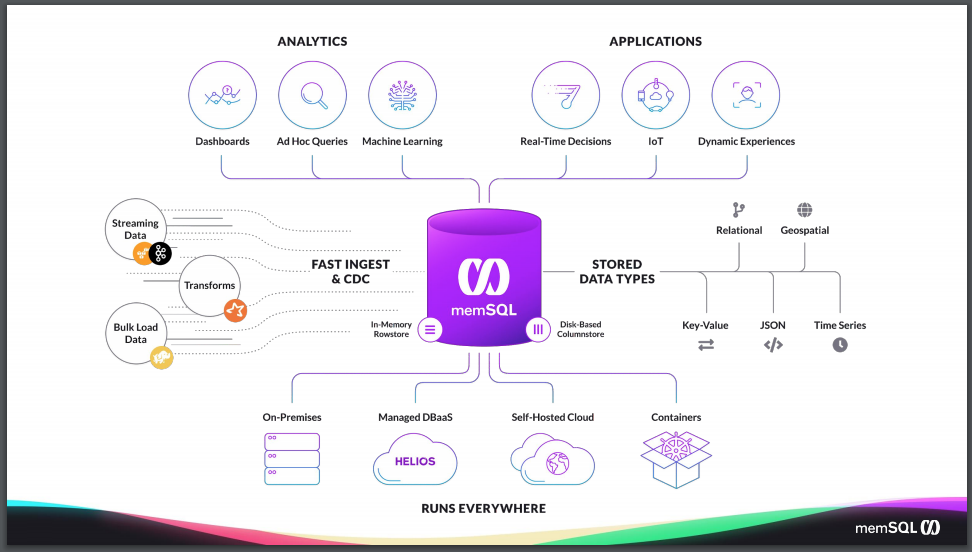
Here’s a crazy idea: instead of throwing a bunch of memory cache around a disk-based NoSQL database that has only half the features you want, what if you cut to the chase and used a database with in-memory rowstore tables, and disk-based columnstore tables, instead? One that talks SQL? And has replication? And sharding that actually works? And high availability? And massive write throughput via lock-free data structures? And transactions – including transactions in stored procedures? And flexible schemas with JSON & non-blocking ALTER TABLE support…
…and one that’s steadily growing in capabilities and features. Since this blog post was written, SingleStore has added columnstore tables (see above), SingleStore Studio visual tool for managing clusters, Singlestore Helios – our elastic cloud database service, SingleStore Universal Storage, the ability to run SingleStore for free – on premises or in the cloud – and so much more.
As mentioned above, please see Rick Negrin’s NoSQL blog post and our case study on replacing Hadoop with SingleStore. You can then get started with SingleStore for free or contact Sales.
Notes:
http://docs.mongodb.org/manual/core/write-performance/
“After every insert, update, or delete operation, MongoDB must update every index associated with the collection in addition to the data itself. Therefore, every index on a collection adds some amount of overhead for the performance of write operations.”
https://tech.dropbox.com/2013/09/scaling-mongodb-at-mailbox/
“…one performance issue that impacted us was MongoDB’s database-level write lock. The amount of time Mailbox’s backends were waiting for the write lock was resulting in user-perceived latency.”
http://redis.io/topics/partitioning
“The partitioning granuliary [sic] is the key, so it is not possible to shard a dataset with a single huge key like a very big sorted set.”





