SME Solutions Group is a SingleStore partner. An SME customer, a utility company, was installing a new meter network, comprising 2 million meters, generating far more data than the old meters. The volume of data coming in, and reporting needs, were set to overwhelm their existing, complex, Hadoop-based solution. The answer: replacing 10 different data processing components with a single SingleStore cluster. The result: outstanding performance, scalability for future requirements, the ability to use standard business intelligence tools via SQL, and low costs.
SME Solutions Group (LinkedIn page here) helps institutions manage risks and improve operations, through services such as data analytics and business intelligence (BI) tools integration. SingleStore is an SME Solutions Group database partner. George Barrett, Solutions Engineer at SME, says: “SingleStore is like a Swiss Army knife – able to handle operational analytics, data warehouse, and data lake requirements in a single database.” You can learn more about how the two companies work together in this webinar and in our previous blog post.
Introduction
A utility company had installed a complex data infrastructure. Data came in from all the company’s systems of record: eCommerce, finance, customer relationship management, logistics, and more.
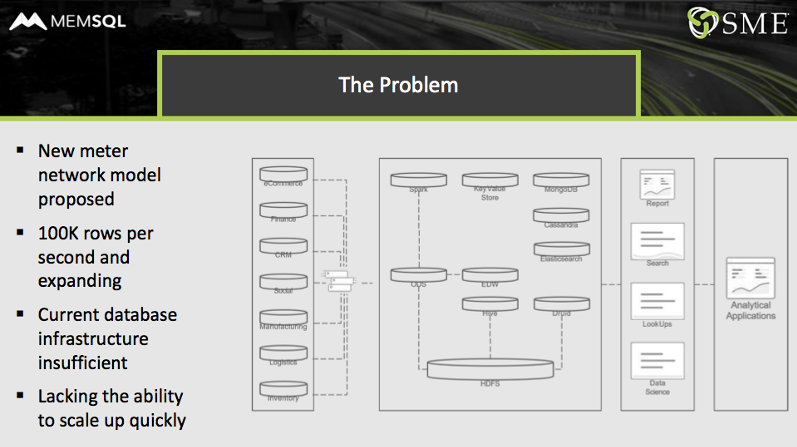
The new meter network was going to blow up ingest requirements to 100,000 rows per second, with future expansion planned. The existing architecture was insufficient, and it lacked the ability to scale up quickly. It featured ten components:
- HDFS, Hive, and Druid. The core database was made up of the Hadoop Distributed File System (HDFS); Hive, for ETL and data warehousing; and Druid, an online analytics processing (OLAP) database, all frequently used together for big data / data lake implementations.
- ODS, EDW, and Spark. An operational data store (ODS) and an electronic data warehouse (EDW) fed Spark, which ran analytics and machine learning model.
- Key-value store, MongoDB (document-based), Cassandra (columnstore data), and ElasticSearch (semi-structured data). Four different types of NoSQL databases stored data for different kinds of reporting and queries.
The Old Solution Fails to Meet New Requirements
This mix of different components was complex, hard to manage, and hard to scale. Worse, it was simply not up to the task of handling the anticipated ingest requirements, even if a lot of effort and investment were expended to try to make it work.
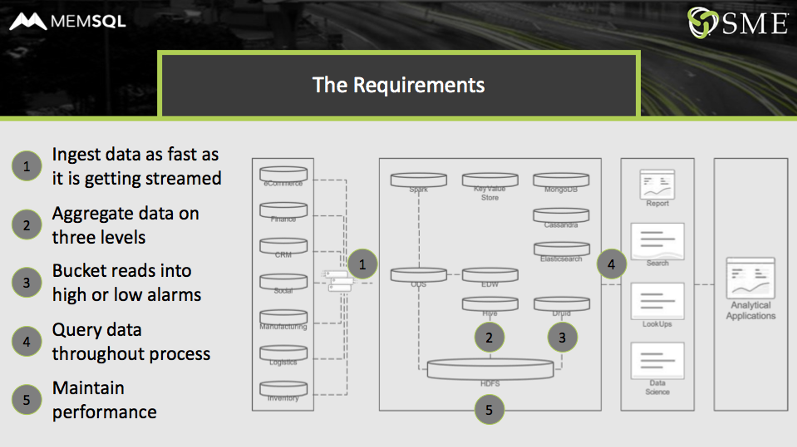
Core requirements would have hit different parts of this complex system:
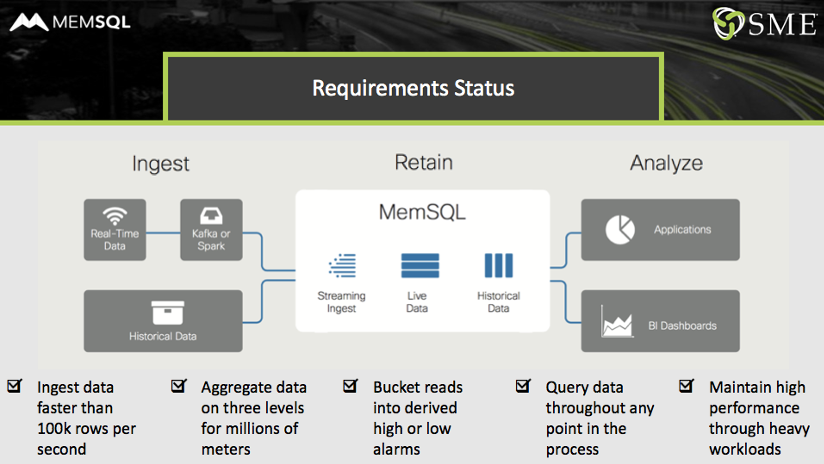
- Ingest data as fast as it was getting streamed. HDFS, for example, is best used for batch processing. Though it can handle micro-batches, it’s not really adapted for true streaming, as required for the new meter system.
- Aggregate data on three levels. The utility needed to aggregate data continuously, at five second intervals per meter, per day, and per month, with the ability to add aggregations going forward. The interaction between HDFS and Hive could not run fast enough to provide the needed aggregations without resorting to multi-second, or longer, response times.
- Bucket selected reads into high alarms and low alarms. Some reads needed to be marked off as alarms due to a value being too high or too low, with the alarm levels changed as needed by the utility. (SingleStore’s new time series features can help here.) The HDFS/Druid pairing could not handle this requirement flexibly and with the needed performance.
- Query data throughout process. The utility needed to allow operations personnel, analysts, and management to interactively query data throughout the process, and to be able to add applications and machine learning models in the future. The 10-component stack had a variety of interfaces, with different levels of responsiveness, altogether too limited and too complex to support query needs from the business.
- Maintain performance. Performance that could meet or exceed tight service level agreements (SLAs) was needed throughout the system. The variety of interfaces and the low performance levels of several components almost guaranteed that performance would be inadequate initially, and unable to scale up.
SingleStore Meets and Exceeds Requirements
The utility built and tested a new solution, using Kafka to stream data into SingleStore. The streaming solution, with SingleStore at its core, pulled all the functionality together into a single database, instead of 10 different components, as previously. And it more than met all the requirements.
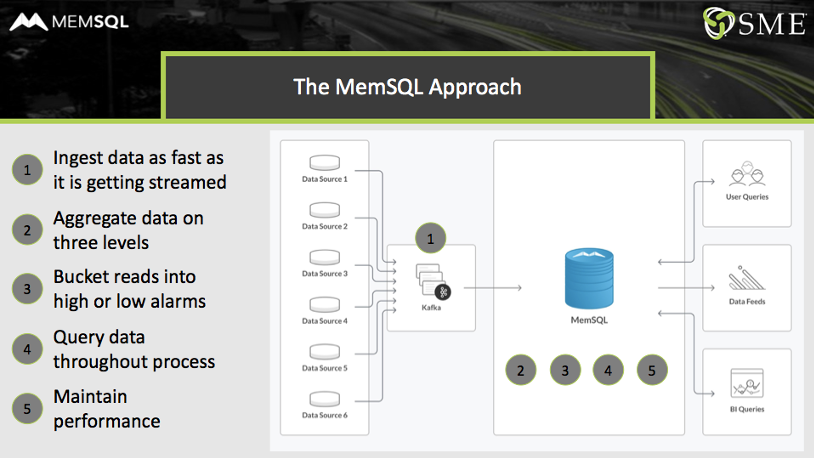
- Ingest data as fast as it’s getting streamed. The combination of Kafka and SingleStore handles ingest smoothly, with Kafka briefly holding data when SingleStore is performing the most complex operations, such as monthly aggregations.
- Aggregate data on three levels. SingleStore handles the three aggregations needed – per meter, meter/day, and meter/month – with room for more.
- Bucket selected reads into high alarms and low alarms. SingleStore’s ability to run comparisons fast, on live data, makes it easy to bucket reads into alarm and non-alarm categories as needed.
- Query data throughout process. SingleStore supports SQL at every step, as well as the MySQL wire protocol, making it easy to interface SingleStore to any needed tool or application.
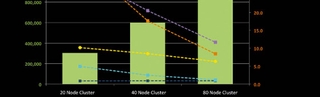
- Maintain performance. SingleStore is so fast that a modestly sized cluster handles the entire operation. If data volumes, query volumes, or other business needs require it, SingleStore scales linearly to handle the increased demands.
There are also obvious operational advantages to using a single database, which supports the SQL standard, to ten disparate components which don’t.
Machine learning and AI are now also much easier to implement. With a single data store for all kinds of data, live data and historical data can be kept in separate tables in the same overall database. Standard SQL operations such as JOINs can unify the data for comparison, queries, and more complex operations, with maximum efficiency.
The Future with SingleStore
With SingleStore at the core, SME’s customer is able to run analytics and reporting across their entire data-set using a wide variety of tools and ad-hoc processes. Although the original use case was 140 million rows of historical meter read data, they are easily able to scale their environment as their data grows to billions and even trillions of rows.
George and others are also excited about the new Universal Storage capability, launched in SingleStoreDB Self-Managed 7.0. In this initial implementation of Universal Storage, rowstore tables have compression, and columnstore tables have fast seeks. The tables are more alike, and the need to use multiple tables, of two different types, to solve problems is greatly reduced. Over time, more and more problems will be solved in one table type, further simplifying the already much-improved operations workload.
You can learn more about how the two companies work together in this webinar and in our previous blog post. To get in touch with the SME Solutions Group, you can schedule a demo or visit their Linkedin page. To try SingleStore, you can run SingleStore for free; or contact SingleStore.