
Using Apache Kafka and SingleStore together makes it much easier to create and deliver intelligent, real-time applications. In a live webinar, which you can view here, SingleStore’s Alec Powell discussed the value that Kafka and SingleStore each bring to the table, shows reference architectures for solving common data management problems, and demonstrates how to implement real-time data pipelines with Kafka and SingleStore.
Kafka is an open source messaging queue that works on a publish-subscribe model. It’s distributed (like SingleStore) and durable. Kafka can serve as a source of truth for data across your organization.
What Kafka Does for Enterprise IT
Today, enterprise IT is held back by a few easy to identify, but seemingly hard to remedy, factors:
- Slow data loading
- Lengthy query execution
- Limited user access

These factors interact in a negative way. Limited data messaging and computing capabilities limit user access. The users who do get on suffer from slower data loading and lengthy query execution. Increasing organizational needs for data access – for reporting, business intelligence (BI) queries, apps, machine learning, and artificial intelligence – are either blocked, preventing progress, or allowed, further overloading the system and slowing performance further.
Organizations try a number of fixes for these problems – offered by both existing and new vendors, usually with high price tags for solutions that add complexity and provide limited relief. Solutions include additional CPUs and memory, specialized hardware racks, pricey database add-ons, and caching tiers with limited data durability, weak SQL coverage, and high management costs and complexity.
NoSQL solutions offer fast ingest and scalability. However, they run queries slowly, demand limited developer time for even basic query optimization, and break compatibility with BI tools.
How SingleStore and Kafka Work Together
SingleStore offers a new data architecture that solves these problems. Unlike NoSQL solutions, SingleStore offers both scalability – which affords extreme performance – and an easy-to-use SQL architecture. SingleStore is fully cloud-native; it is neither tied to just one or two cloud platforms, nor cloud-unfriendly, as with most alternatives.
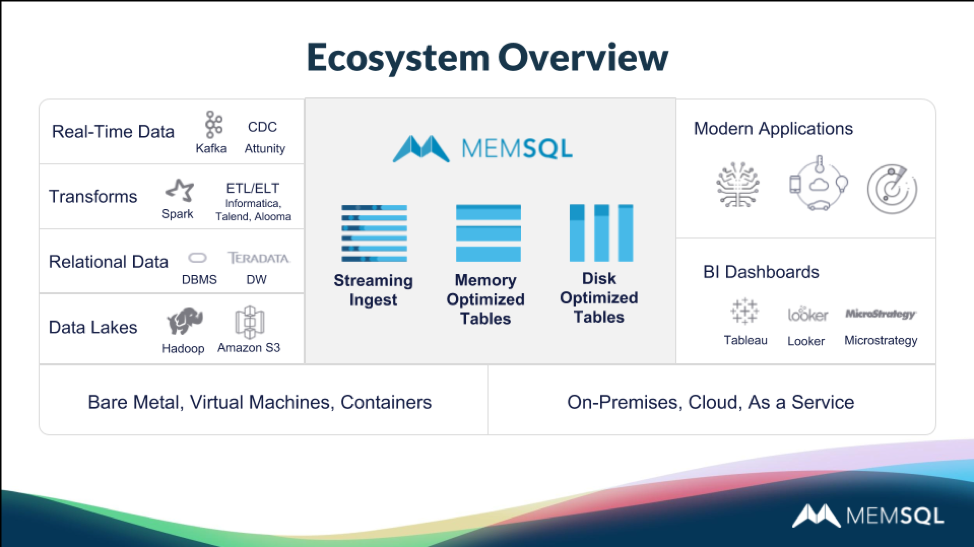
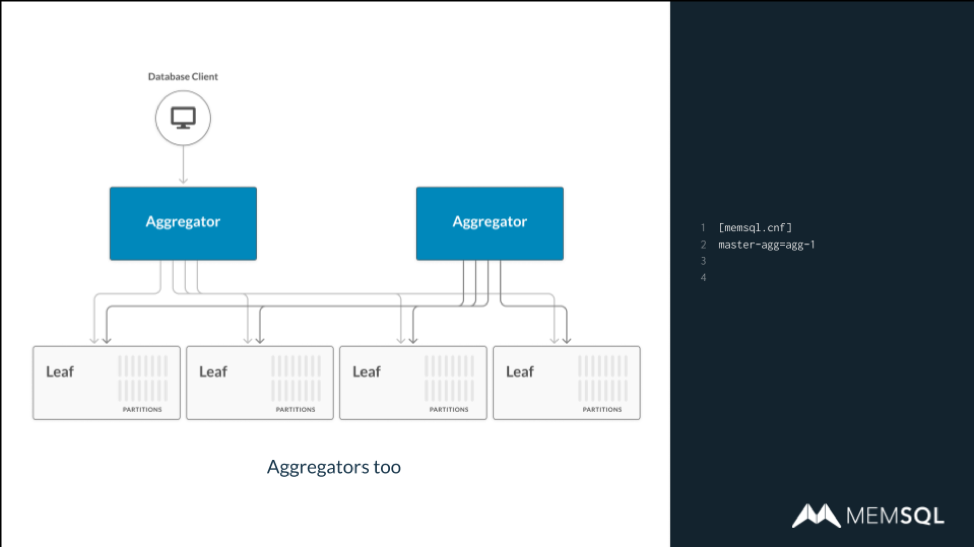
In the webinar, Alec shows how SingleStore works. Running as a Linux daemon, SingleStore offers a fully distributed system, and is cloud-native – running in the cloud and on-premises, in containers or virtual machines, and integrating with a wide range of existing systems. Within a SingleStore cluster, an aggregator node communicates with the database client, manages schema, and shares work across leaf nodes. (A master aggregator serves as a front-end to multiple aggregator nodes, if the scale of the database requires it.)
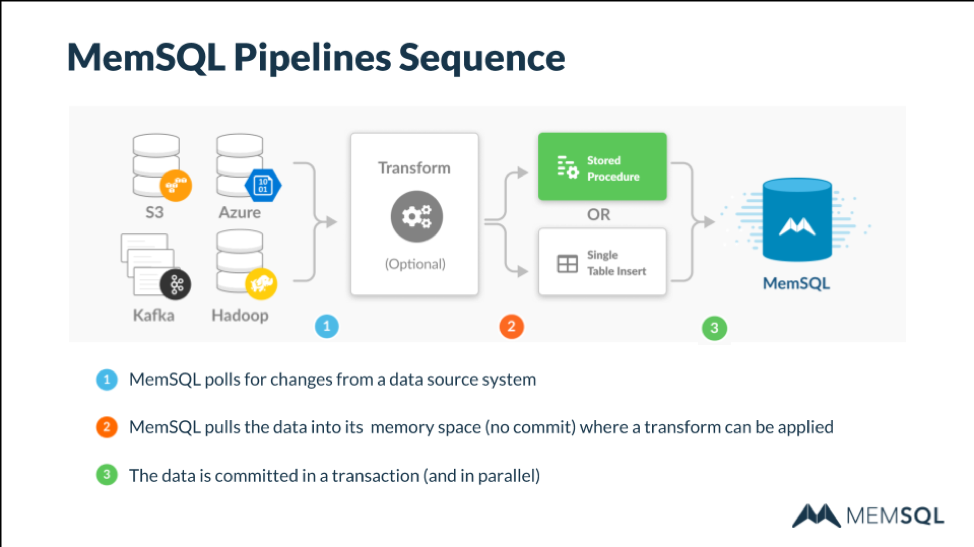
SingleStore Pipelines integrate tightly with Kafka, supporting the exactly-once semantics for which Kafka has long been well-known. (See the announcement blog post in The New Stack: Apache Kafka 1.0 Released Exactly Once.) SingleStore polls for changes, pulls in new data, and executes transactions atomically (and exactly once). Pipelines are mapped directly to SingleStore leaf nodes for maximum performance.
Together, Kafka and SingleStore allow live loading of data, which is a widely needed, but rarely found capability. Used with Kafka, or in other infrastructure, SingleStore handles mixed workloads and meets tight SLAs for responsiveness – including with streaming data and strong demands for concurrency.
Kafka-SingleStore Q&A
There was a lively Q&A session. The questions and answers here include some that were handled in the webinar and some that could not be answered in the live webinar because of time constraints.
Q. Can Kafka and SingleStore run in the cloud?
A. Both Kafka and SingleStore are cloud-native software. Roughly half of SingleStore’s deployments today are in the cloud; for instance, SingleStore often ingests data from AWS S3, and has been used to replace Redshift. The cloud’s share of SingleStore deployments is expected to increase rapidly in the future.
Q. Can SingleStore replace Oracle?
A. Yes, very much so – and other legacy systems too. Because of the complexities of many data architectures, however, SingleStore is often used first to augment Oracle. For instance, customers will use a change data capture (CDC) to copy data processed by Oracle to SingleStore. Then, analytics run against SingleStore, offloading Oracle (so transactions run faster) and leveraging SingleStore’s faster performance, superior price-performance, scalability, and much greater concurrency support for analytics.
Q. How large can deployments be?
A. We have customers running from the hundreds of megabytes up into the petabytes.
Q. With SingleStore Pipelines, can we parse JSON records?
A. Yes, SingleStore has robust JSON support.
Summing Up Kafka+SingleStore and the Webinar
In summary, SingleStore offers live loading of batch and streaming data, fast queries, and fully scalable user access. Together, Kafka and SingleStore remove access to data streaming and data access right across your organization. You can view the webinar now. You can also try SingleStore for free today or contact us to learn how we can help support your implementation plans.





