The limitations of a typical, traditional relational database management system (RDBMS) have forced all sorts of compromises on data processing systems: from limitations on database size, to the separation of transaction processing from analytics. One such compromise has been the “sharding” of various customer data sets into separate database instances, partly so each customer could fit on a single computer server – but, in a typical power law, or Zipf, distribution, the larger databases don’t fit. In response, database application developers have had to implement semi-custom sharding schemes. Here, we describe these schemes, discuss their limitations, and show how an alternative, SingleStore, makes them unnecessary.
What follows are tales of two different database application architects who face the same problem—high skew of database size for different customer data sets, meaning a few are much larger than others—and address this problem in two different ways. One tries to deal with it via a legacy single-box database and through the use of “clever” application software. The other uses a scalable database that can handle both transactions and analytics—SingleStore. Judge for yourself who’s really the clever one.
The Story of the Hero Database Application Architect
Once there was a database application architect. His company managed a separate database for each customer. They had thousands of customers. They came up with what seemed like a great idea. Each customer’s data would be placed in its own database. Then they would allocate one or more databases to a single-node database server. Each server would handle operational queries and the occasional big analytical query.
When a server filled up, they’d just allocate additional databases to a different server.
Everything was going great during development. The application code only had to be written once, for one scenario — all data for a customer fitting one DBMS server. If a database was big, no problem, just provision a larger server and put that database alone on that server. Easy.
Then they went into production. Everything was good. Success brought in bigger customers with more data. Data grew over time. The big customer data grew and grew. The biggest one would barely fit on a server. The architect started losing sleep. He kept the Xanax his doctor prescribed for anxiety in the top drawer and found himself dipping into it too often.
Then it happened. The biggest customer’s data would not fit on one machine anymore. A production outage happened. The architect proposed trimming the data to have less history, but the customers screamed. They needed 13 months minimum or else. He bought time by trimming to exactly 13 months. They only had two months of runway before they hit the wall again.
He got his top six developers together for an emergency meeting. They’d solve this problem by sharding the data for the biggest customer across several DBMS servers. Most queries in the app could be directed to one of the servers. The app developers would figure out where to connect and send the query. Not too hard. They could do it.
But some of the queries had aggregations over all the data. They could deal with this. They’d just send the query to every server, bring it back to the app, and combine the data in the app layer. His best developers actually thought this was super cool. It was way more fun than writing application software. They started to feel really proud of what they’d built.
Then they started having performance problems. Moving data from one machine to the other was hard. There were several ways they could do things. Which way should they do it? Then someone had the great idea to write an optimizer that would figure out how to run the query. This was so fun.
Around this time, the VP from the business side called the architect. She said the pace of application changes had slowed way down. What was going on? He proudly but at the same time sheepishly said that his top six app developers had now made the leap to be database systems software developers. Somehow, she did not care. She left his office, but it was clear she was not ready to let this lie.
He checked the bug count. Could it be this high? What were his people doing? He’d have to fix some of the bugs himself.
He started to sweat. A nervous lump formed in the pit of his stomach. The clock struck 7. His wife called and said dinner was ready. The kids wanted to see him. He said he’d leave by 8.
The Story of the Disciplined Database Application Architect
Once there was a database application architect. His company managed a separate database for each customer. They had thousands of customers. They at first considered what seemed like a great idea. Each customer’s data would be placed in its own database on a single-node database server. But, asked the architect, what happens when there’s more data than will fit on one machine?
One of the devs on his team said he’d heard of this scale-out database called SingleStore that runs standard SQL and can do both operational and analytical workloads on the same system. If you run out of capacity, you can add more nodes and spread the data across them. The system handles it all automatically.
The dev had actually tried the free version of SingleStore for a temporary data mart and it worked great. It was really fast. And running it took half the work of running their old single-box DBMS. All their tools could connect to it too.
They decided to run just a couple of SingleStore clusters and put each customer’s data in one database on one cluster. They got into production. Things were going great; business was booming. Their biggest customer got really big really fast. It started to crowd out work for other customers on the same cluster. They could see a problem coming. How could they head it off?
They had planned for this. They just added a few nodes to the cluster and rebalanced the biggest database. It was all done online. It took an hour, running in the background. No downtime.
The VP from the business side walked in. She had a new business use case that would make millions if they could pull it off before the holidays. He called a meeting the next day with the business team and a few of his top developers. They rolled up their sleeves and sketched out the application requirements. Yeah, they could do this.
Annual review time came around. His boss showed him his numbers. Wow, that is a good bonus. He felt like he hadn’t worked too hard this year, but he kept it to himself. His golf score was down, and his pants still fit just like in college. He left the office at 5:30. His kids welcomed him at the door.
The Issue of Skewed Database Sizes
The architects in our stories are facing a common issue. They are building services for many clients, where each client’s data is to be kept in a separate database for simplicity, performance and security reasons. The database sizes needed by different customers vary dramatically, following what’s known as a Zipf distribution [Ada02]. In this distribution, the largest databases have orders of magnitude more data than the average ones, and there is a long tail of average and smaller-sized databases.
In a Zipf distribution of database sizes, the size y of a database follows a pattern like
size(r) = C r^(-b)*
with b close to one, where r is the rank, and C is a constant, with the largest database having rank one, the second-largest rank two, and so on.
The following figure shows a hypothetical, yet realistic Zipf distribution of database size for b = 1.3 and C = 10 terabytes (TB). Because of the strong variation among database sizes, the distribution is considered highly skewed.
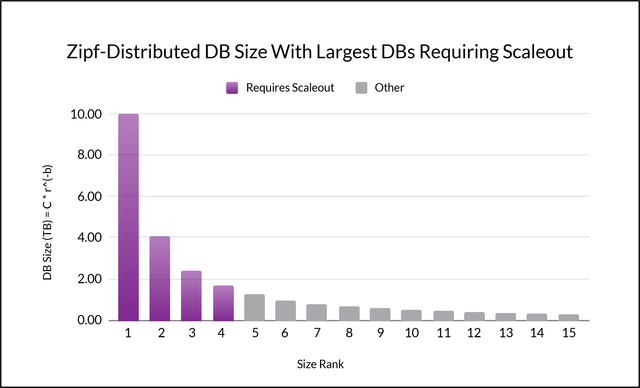
If your database platform doesn’t support scaleout, then it may be impossible to handle, say, the largest four customer databases when database size is distributed this way–unless you make tortuous changes to your application code, and maintain them indefinitely.
I have seen this kind of situation in real life more than once. For example, the method of creating an application layer to do distributed query processing over sharded databases across single-node database servers, alluded to in the “hero” story above, was tried by a well-known advertising platform. They had one database per customer, and the database sizes were Zipf-distributed. The largest customers’ data had to be split over multiple nodes. They had to create application logic to aggregate data over multiple nodes, and use different queries and code paths to handle the same query logic for the single-box and multi-box cases.
Their top developers literally had to become database systems software developers. This took them away from application development and slowed the pace of application changes. Slower application changes took money off the table.
An Up-to-Date Solution for Skewed Database Sizes
Writing a distributed query processor is hard. It’s best left to the professionals. And anyway, isn’t the application software what really produces value for database users?
Today’s application developers don’t have to go the route of application-defined sharding and suffer the pain of building and managing it. There’s a better way. SingleStore supports transactions and analytics on the same database, on a single platform. It handles sharding and distributed query processing automatically. It can scale elastically via addition of nodes and online rebalancing of data partitions.
Some of our customers are handling this multi-database, Zipf-distributed size scenario by creating a database per customer and placing databases on one or more clusters. They get a “warm fuzzy feeling” knowing that they will never hit a scale wall, even though most of their databases fit on one machine. The biggest ones don’t always fit. And they know that, when a database grows, they can easily expand their hardware to handle it. They only have to write and maintain the app logic one way, one time, for all of their customers. No need to keep Xanax in the top drawer.
SingleStore doesn’t require performance compromises for transactions or analytics [She19]. Quite the contrary, SingleStore delivers phenomenal transaction rates and crazy analytics performance [She19, Han18] via:
- in-memory rowstore structures [Mem19a],
- multi-version concurrency control [Mem19c],
- compilation of queries to machine code rather than interpretation [Mem19e], and
- a highly-compressed, disk-based columnstore [Mem19b] with
- vectorized query execution and use of single-instruction-multiple-data (SIMD) instructions [Mem19d].
Moreover, it supports strong data integrity, high availability, and disaster recovery via:
- transaction support
- intra-cluster replication of each data partition to an up-to-date replica (a.k.a. redundancy 2)
- cluster-to-cluster replication
- online upgrades.
Your developers will love it too, since it supports popular language interfaces (via MySQL compatibility) as well as ANSI SQL, views, stored procedures, and user-defined functions.
And it now supports delivery as a true platform as a service, Singlestore Helios. Singlestore Helios lets you focus even more energy on the application rather than running–let alone creating and maintaining–the database platform. Isn’t that where you’d rather be?
References
[Ada02] Lada A. Adamic, Zipf, Power-laws, and Pareto – a ranking tutorial, HP Labs, https://www.hpl.hp.com/research/idl/papers/ranking/ranking.html, 2002.
[Han18] Eric Hanson, Shattering the Trillion-Rows-Per-Second Barrier With SingleStore, https://www.singlestore.com/blog/memsql-processing-shatters-trillion-rows-per-second-barrier/, 2018.
[Mem19a] Rowstore, SingleStore Documentation, https://archived.docs.singlestore.com/v6.8/concepts/rowstore/, 2019.
[Mem19b] Columnstore, SingleStore Documentation, https://archived.docs.singlestore.com/v6.8/concepts/columnstore/, 2019.
[Mem19c] SingleStore Architecture, https://docs.singlestore.com/db/latest/en/introduction/how-singlestore-db-works.html, 2019.
[Mem19d], Understanding Operations on Encoded Data, SingleStore Documentation, https://archived.docs.singlestore.com/v6.8/concepts/understanding-ops-on-encoded-data/, 2019.
[Mem19e], Code Generation, SingleStore Documentation, https://archived.docs.singlestore.com/v6.8/concepts/code-generation/, 2019.
[She19] John Sherwood et al., We Spent a Bunch of Money on AWS And All We Got Was a Bunch of Experience and Some Great Benchmark Results, https://www.singlestore.com/blog/memsql-tpc-benchmarks/, 2019.