
Today, we announced the general availability of SingleStoreDB Self-Managed 6.7. This latest release introduces features that provide faster query performance and improved usability with more robust monitoring, simplified deployment tooling, and a new free tier that anyone can use.
Data and the ability to analyze and act on it are the most critical capabilities of modern businesses. Leveraging data quickly and effectively is key to delivering new customer experiences, enabling competitive advantage, and optimizing operations.
Query performance, concurrency, and scalability are critical requirements for modern applications and analytical systems, yet legacy databases and big data systems struggle to keep up. SingleStore addresses all these challenges, and SingleStoreDB Self-Managed 6.7 makes processing and analyzing data easier and faster for both streaming data and big data, while continuing to support familiar, standard SQL, and the broad ecosystem that uses it.
New advances include a free production license for SingleStoreDB Self-Managed 6.7, within limits; dramatically faster queries; new tooling for monitoring and management; new native connections; and a new developer forum for tips and troubleshooting.
SingleStoreDB Self-Managed 6.7 Now Free to Use, Making Maximum Performance Available to Everyone
SingleStoreDB Self-Managed 6.7 can be used for free in production, up to a limit of 128GB of RAM capacity, with unlimited disk/solid state drive (SSD) usage.
Unlike many of our competitors, the free tier of SingleStore offers all the capabilities found in the Enterprise licensing tier of the database, including the full performance and security features.
The free tier offers tremendous value. Customers of legacy databases are paying \$100,000 and more per year for similar capacity for operational systems, data warehouses, and data marts. Yet these existing systems have fundamental scalability limits that are not present with SingleStore.
The free tier is backed by extensive documentation and a community of users, but does not include professional SingleStore support. Companies looking for interactive, ticket-based support and guidance, or who want more than 128GB of RAM capacity (with no limits on disk/SSD usage), will need to upgrade to an Enterprise license. Contact SingleStore for more details.
Faster Queries Out of the Box
Getting excellent database performance often requires experimentation. Developers and analysts try various query hints and tuning steps as stop-gaps when query optimization, execution, or indexing don’t work fast enough. The result is more time spent tuning, and less time discovering and acting on new insights.
Star Joins are a type of query commonly used in data analytics, in which a large table is joined to one or more smaller tables. SingleStoreDB Self-Managed 6.7 has made Star Joins faster – up to 100x faster, in some cases – by leveraging query vectorization and single instruction, multiple data (SIMD) technology, a kind of parallel processing. Queries will also execute faster at first run with improved sampling eliminating cumbersome hints and tuning often associated with new query development. You can read more about SingleStoreDB Self-Managed 6.7 performance results.
New Monitoring and Management Tooling Simplifies Tuning and Deployment
SingleStore Studio gives users a simple way to visualize the health of SingleStore clusters across resources, events, and queries. The new query inspector, for example, enables immediate discovery and debugging of query bottlenecks across the spectrum of CPU, memory, disk, and IO, which enables faster tuning and improved integration with other management and DevOps tools.
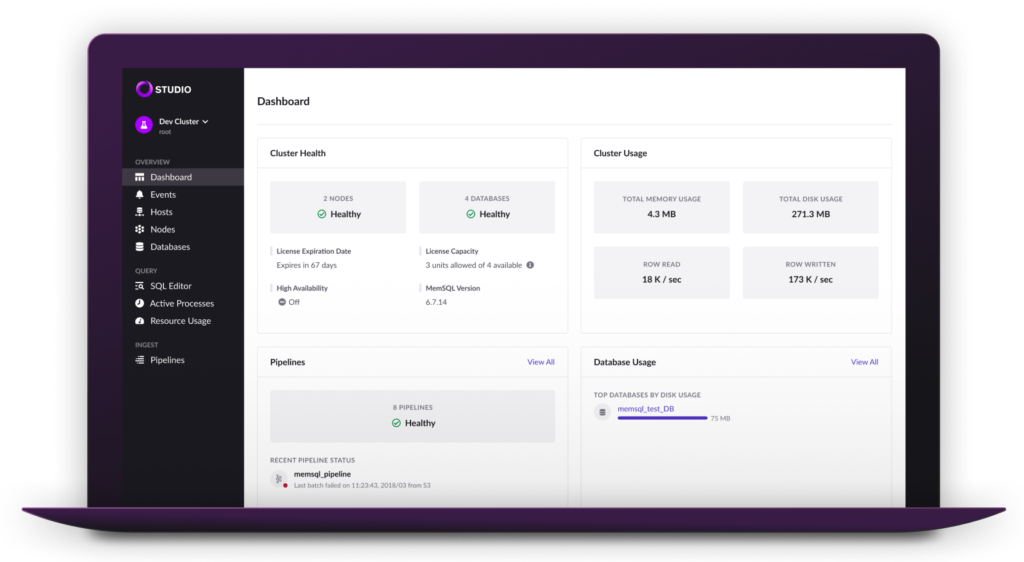
Additional improvements include command line tooling that simplifies multi-node setup and cloud formation templates to automate cluster deployments and configuration. With these changes, the power of SingleStore, and the ability to optimize it as part of speeding data updating and access, becomes more accessible to everyone, from new users to established industry partners. We have a separate blog post where you can learn more about SingleStore Studio and the associated tooling.
Improved Loading and Backups
In SingleStoreDB Self-Managed 6.7, we’ve added native ingest for the JavaScript Object Notation (JSON) and Avro data formats. (Avro is a protocol for remote procedure calls and data serialization that uses JSON format.) You can now load Avro or JSON from files or Apache Kafka directly into a relational schema or into a semi-structured JSON column. While SingleStore ingests both file types at high speed, Avro, being a modern binary format, provides the highest performance ingest possible. Both JSON and Avro allow for schema flexibility on ingest.
Developer Forums for Tips and Troubleshooting
For people who prefer to run our free tier, we have introduced a new developer forum for developers to post, research, and answer questions about SingleStore. Developers can learn best practices, engage with experts, and mature as a member of the No-Limits Database™ community. Check out our new forum.
Want to Learn More?
Join our SingleStoreDB Self-Managed 6.7 webinar, where we’ll explain the new capabilities of SingleStoreDB Self-Managed 6.7, the free tier, and deliver a live demo of our new monitoring and management tools.
For more information on SingleStoreDB Self-Managed 6.7, see the press release and all eight blog posts on the new version: Product launch (this post); managing and monitoring SingleStoreDB Self-Managed 6.7 (includes SingleStore Studio); the new free tier; performance improvements; the Areeba case study; the Wag! case study; the creation of the Visual Explain feature; and how we developed adaptive compression.
.png?auto=webp&width=320&disable=upscale)




