
Wag! has been called the “Uber for dogs”. The service matches dog owners with dog walkers, tracking and visualizing each walk in real time. The service is now available in more than 100 cities across America. Now, Wag! is using SingleStore to help them meet the demands of rapid growth.
Dog owners start with a live map of dog walkers near them. They connect with a walker, set up the walk for their dog, and watch it proceed live, on a map of their neighborhood. Every walk ends with an activity report. The report features a photo of the dog, the time and distance for the walk, and more.
Every single walk generates significant amounts of real-time data. Wag! needs to handle the traffic smoothly and be ready for spikes and future growth.
App performance is key to business success at Wag!, so the technical challenges of scaling data ingest have serious business implications.
JOINing Business and Technical Challenges
Earlier this year, Wag!’s core database was reaching its maximum computing capacity. One of the main reasons was the large amount of writes that the main database had to handle. The writes also caused delays on database Replicas, which prevented Wag! from scaling read queries.
“We didn’t have much head room for growth,” said Franck Leveneur, data service tech lead at Wag! “The goal was to move our ‘log type’ writes out of MySQL and to SingleStore, to free up resources. This move would diminish our lag, freeing up the MySQL database to handle read-only queries.”
Leveneur was familiar with SingleStore and knew it was the best fit for Wag! based on several key capabilities:
- Drop-in solution. MySQL and SingleStore both support SQL, so there was no learning curve and implementation was quick. “SingleStore has done a great job in building a database that is very easy to use if you’re coming from the MySQL world. Our engineers had no issues using SingleStore; it felt natural,” said Leveneur.
- In-memory rowstore and on-disk columnstore support. Wag! performs initial processing in-memory, in rowstore format, with very high performance. They then use the columnstore engine to compress data up to 70 percent. SingleStore can then run aggregate queries much faster than MySQL, which is a huge win.
- Pipelines. SingleStore can plug directly into S3 and ingest data at amazing speeds. “Think backfilling a 700M row table in less than 20 minutes on a live SingleStore database in production,” said Leveneur. “I’ve dealt with large backfilling before; it’s challenging. SingleStore makes this process a walk in the park”.
- Support. Like other SingleStore customers, Wag! finds SingleStore’s support to be outstanding. “The team is always available to answer questions, to help us optimize queries, or to share Python code for implementing transformations. Their training material and documentation are also excellent.”
The overall results have been excellent. “Today, after migrating all the needed tables from MySQL to SingleStore, we have reduced our average CPU utilization to the high teens,” said Leveneur. “We have not yet used other great SingleStore features such as geospatial data type, full-text search, and windowing yet, but we’re planning to explore them.”
Next Steps for Wag! with SingleStore
Although he wouldn’t say so himself, Leveneur is an expert in solving thorny problems, such as improving ingest performance. A few years ago, he gave a talk on ultra-fast data reporting with very large data sets at the Los Angeles MySQL Meetup group. He leads a data management course at UCLA and includes SingleStore in the curriculum.
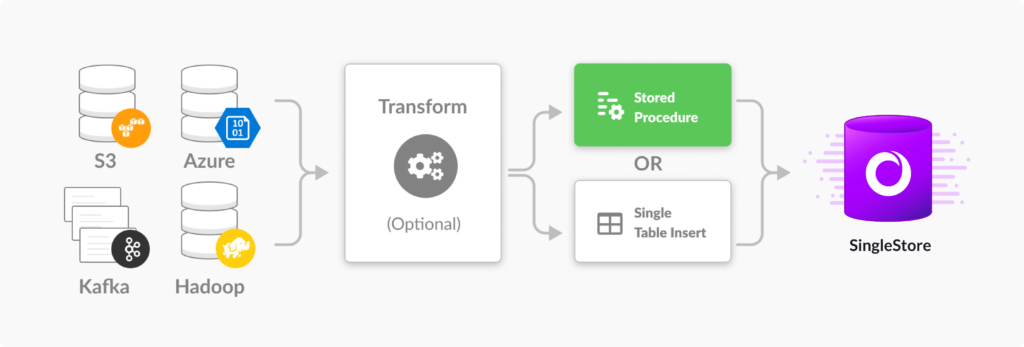
Wag! still has more to do with SingleStore. One feature it will look at soon was introduced in SingleStoreDB Self-Managed 6.5: Pipelines to Stored Procedures.
Existing Pipelines integrate the Extract, Transform, and Load (ETL) elements of a wide range of ingest problems. The new, upgraded Pipelines to Stored Procedures can break a data stream up into multiple tables, JOIN them to existing data, and update existing rows with the enriched data, with high performance.
Leveneur is also excited about a publicly accessible database of taxi data from New York that would be suitable for student lab work. “They love that! Coding and learning, on the cutting edge.”
Wag!, too, is on the cutting edge.
For more information on SingleStoreDB Self-Managed 6.7, see the press release and all eight blog posts on the new version: Product launch; managing and monitoring SingleStoreDB Self-Managed 6.7 (includes SingleStore Studio); the new free tier; performance improvements; the Areeba case study; the Wag! case study (this post); the creation of the Visual Explain feature; and how we developed adaptive compression.





