
SingleStore CEO Nikita Shamgunov recently joined host Tobias Macey on the Data Engineering Podcast. Tobias drew out Nikita on SingleStore’s origins, our exciting present, and where we’re going in the future. In this blog post, we’ll try to get you excited about some of the business and engineering topics discussed in the podcast, but we urge you to listen to the full episode.
For your interest, here is a full list of the topics – with a few of them highlighted in this blog post:
- What is SingleStore and how did it start?
- What are the typical use cases for SingleStore?
- Why did we build data ingest in the database?
- The SingleStore architecture
- SingleStore performance
- Building SingleStore: how much open source do we use?
- SingleStore and the MySQL wire protocol
- How to set up SingleStore
- Challenges faced by customers when migrating to SingleStore
- Elasticity of SingleStore
- SingleStore licensing model
- Challenges with building a business around SingleStore
- When is SingleStore not the right choice
- The future of SingleStore
- Modern tooling for data management
Now, let’s dive into some of the business and technical concepts that were discussed in the podcast as a way to get you excited to listen to the entire thing.
Note: You might also be interested to read this recent interview with Nikita on HackerNoon.
How SingleStore Started
Nikita grew up and was educated in Russia, where he earned his PhD in computer science and became involved in programming competitions, winning several. (Quite a few SingleStore engineers have shared the same passion, including me.) Shortly after graduation, Nikita was hired by Microsoft. He flew to Seattle to join the SQL Server team and spent five years there.
Nikita describes his early days as a “trial by fire,” followed by a “death march”: testing and debugging SQL Server 2005, a landmark release that was five years in the making. The SQL Server effort was a “very, very good training ground.” It was also where the seeds of SingleStore were planted.
Internally, Microsoft worked on a scalable transactional database, knowing that it was sorely needed – but never shipped it. Nikita and Microsoft colleague Adam Prout, who became the chief architect and co-founder, with Nikita, of SingleStore, found that “incredibly frustrating”.
After Microsoft, Nikita joined Facebook, where “it became very apparent to me what the power and the value of such a system is.” So Nikita co-founded SingleStore in 2013, and the team soon delivered the first widely usable distributed transactional system.
SingleStore started out as an in-memory system. This “allowed us to onboard various high value workloads” and to start building a business. Later, SingleStore added disk-based columnstore capability, making it a very flexible, memory-led database.
Early in SingleStore’s history, most of the workloads that fit the new system were around analytics on live data. SingleStore can handle “a high volume of inserts, updates, deletes hitting the (transactional) system, but at the same time actually drive insights, drive analytics”.
But, notes Nikita, “the amount of technology that goes into a product like this is absolutely enormous.” That meant it would take time to complete the full vision: a “fully scalable, elastic transactional system that can support transactions and analytics in one product.”
Note: The photograph below comes from a talk by Nikita at the SQL NYC group in 2017. The talk is available on YouTube.

Key Architectural Decisions
Nikita discusses many of the key points of SingleStore’s architecture. When the work on SingleStore was started, Nikita and the rest of the team bet on RAM as the storage of the future, since it was predicted that the cost of RAM would go down by a lot. This hasn’t really happened for RAM as such, though flash memory is now dropping rapidly in cost, so SingleStore’s architecture had to evolve to support both disk and memory. Nikita also explains how SingleStore’s distributed nature is key for its scalability.
Nikita goes on to answer a very interesting question about SingleStore and the consistency, availability, and partition tolerance (referred to as the CAP theorem) of distributed database design – which holds that you can only have two out of the three. Partition tolerance is held to be mandatory in a distributed system.
In his answer, Nikita explains why SingleStore is not fully available (the A in CAP), in order to guarantee consistency and partition tolerance (the C and P). “The greatest sin of a database is to lose data”, explains Nikita, making the choice of building a CP system very natural.
Nikita also explores the ins and outs of converting from row-oriented data to column-oriented data (and vice-versa) in SingleStore. Since SingleStore supports row-oriented tables in memory and column-oriented tables on disk, but clients (e.g. SQL clients) expect row-oriented data, one might argue that the conversion from rowstore to columnstore could affect SingleStore’s performance.
However, that’s not (usually) the case, as Nikita explains in the podcast. Succinctly, the conversion from rowstore to columnstore when data is being inserted is actually I/O-bound and not, perhaps surprisingly, CPU-bound. Since CPUs are so fast at converting from one format to the other, disk performance actually matters most, and thus the conversion overhead becomes much less relevant.
Secondly, since most columnstore queries are analytical in nature (e.g. reporting queries), the number of results (in number of rows) is usually quite low. This means that most query operations will be applied on internal representation of columnstore data as vectors, which is very performant. One exception to this performance is when clients request a lot of columnstore data.
Optimizing Performance
Nikita was asked about performance optimization in SingleStore. This question touches on so many areas that Nikita gave an answer in which he organized some of SingleStore’s key performance optimizations into three separate buckets:
- In-memory query optimization – for queries against in-memory data, careful code generation is fundamental for amazing performance
- Network optimization — why and how SingleStore engineers are super careful about data serialization and deserialization across the cluster
- Compression and vectorization — how SingleStore has built a general purpose system for performing computations on encoded data.
Not much of this performance optimization, or other parts of SingleStore, are built with open source code. The vast majority of SingleStore’s code was written internally. SingleStore does everage a few open source libraries for some geospatial capabilities (S2 Geometry), columnstore compression, and query parsing/binding (from PostgreSQL source code).
Setting Up and Running SingleStore
Tobias asks Nikita about setting up SingleStore. Nikita replies: “Setting up and deploying is trivial. Once you commit to a certain size of the cluster, it’s basically a push-button experience, and then SingleStore will be running on that cluster.”
The main obstacle to implementing SingleStore is “understanding the distributed nature of the system.” However, “once you realize the value, then not only do we have passionate fans in the enterprise – they tend to get promoted too.”
One key innovation is SingleStore Pipelines. “If you have data coming from Kafka or you have data in S3 or HDFS, you can literally type one command, and this data is flowing into SingleStore in real-time with arbitrary scale.”
With the addition of Pipelines to Stored Procedures, you can add much more processing, running at high speed. With Pipelines, says Nikita, “We pulled in data ingest as a first-class citizen into the engine… We have customers that are moving data into SingleStore tables at multiple gigabytes a second.”
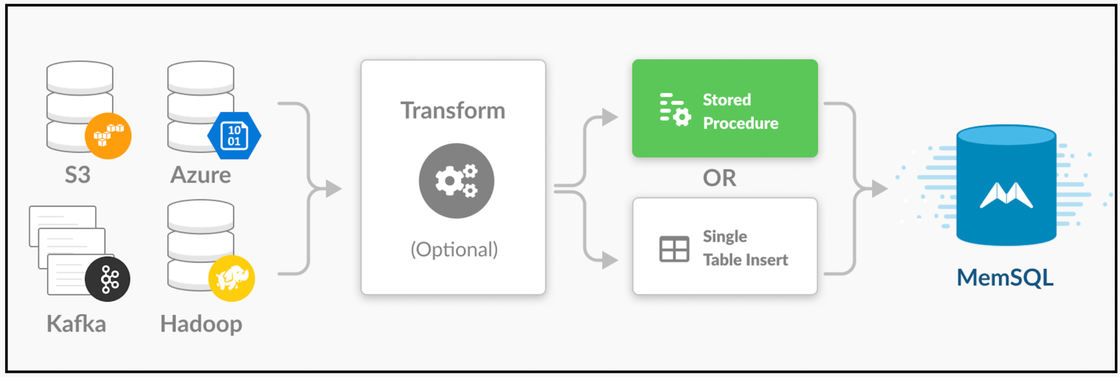
SingleStore is notable for combining scalability and a very high level of performance – which were, for a time, only available from NoSQL databases – with ANSI SQL support. “It gives the user the ability to have as much structure as the user needs and wants, but at the same time it doesn’t sacrifice performance.” The advantages include “compatibility with BI tools… you can easily craft visualizations, and it simplifies building apps as well.”
Typical Use Cases
Continuing the interview, Tobias asks Nikita about typical use cases for SingleStore. Nikita replies in detail: “At the very, very high level, we support general purpose database workloads that require scale. We give you unlimited storage and unlimited compute and in one product. We can scale your applications in an elegant way.”
Nikita cites real-time dashboards, Web 2.0 and mobile applications, portfolio analysis, portfolio management, and real-time financial reporting as some specific applications that need “to deliver a great user experience and lower latencies,” thus requiring nearly limitless compute capability – that is, a fully scalable system.
For data warehousing, with SingleStore, “you don’t need to extract your data and put it into the data warehouse; you do it on the data that sits in the database. So the advantage is really simplicity.” There are also “use cases by industry.” SingleStore started out being “most successful in financial services and media,” with “health care coming more and more into the platform.”
The Future of SingleStore
Finishing up the interview, Tobias presses Nikita on the need for SingleStore developers to choose row-store, in-memory tables vs. column-store, disk-based tables for different data. In the podcast, Nikita explains the trade-offs in detail, then goes further. “In the future, I believe databases will get to a place where there are no choices, you just create tables. You have a cloud service, you have a SQL API to it, and that SQL API has endless capacity. You pay for better latencies and better throughputs.”
Nikita continues, “On the way toward that vision, we’re investing in managed services and Kubernetes integration. We are constantly strengthening the engine itself, making it more elastic, making it more robust, having the ability to run on multiple data centers, and improving the developer experience.”
Also, “AI and ML workloads are rising exponentially, but they need to store data somewhere, and there is no clear choice for that just yet. That’s an exciting world, and we are absolutely going to be part of that.”
Tune In for More
While these highlights are intriguing, there’s much more depth and breadth in the full podcast episode. We encourage you to listen to the episode and subscribe to the Data Engineering Podcast, which is available on Downcast, Instacast, iTunes, Podgrasp, Spotify, and other platforms.





