
How does a major technology services company equip itself to compete in the digital age – and provide services so outstanding that they can significantly advance the business prospects of their customers? All while reducing complexity, cutting costs, and tightening SLAs – in some cases, by 10x or more? For one such company, the solution is to deliver real-time, operational analytics with Kafka and SingleStore.
In this company, data flowed through several data stores, and from a relational, SQL database, into NoSQL data stores for batch query processing, and back into SQL for BI, apps, and ad hoc queries. Now, data flows in a straight line, through Kafka and into SingleStore. Airflow provides orchestration.
Before SingleStore: Custom Code, PostgreSQL, HDFS, Hive, Impala, and SQL Server
At this technology services company, analytics is absolutely crucial to the business. The company needs analytics insights to deliver services and run their business. And they use their platform to provide reports and data visualizations to their customers. (We’re leaving the company unidentified so they can speak more freely about their process and their technology decisions.)
The company’s original data processing platform was developed several years ago, and is still in use today – soon to be replaced by Kafka and SingleStore. Like so many companies at that time, they chose a NoSQL approach at the core of their analytics infrastructure.
Data flowed through the analytics core in steps:
- A custom workflow engine brings in data and schedules jobs. The engine was written in Python to maximize flexibility in collecting data and scheduling data pipelines.
- The data is normalized and stored in PostgreSQL, one of the leading relational databases.
- Data then moves into HBase, the data store for Hadoop – a NoSQL system that provides the ability to version data at an atomic (columnar) level.
- In the next step, data moves to Apache Hive, the data warehousing solution for Hadoop. Then new, updated Parquet tables are created on Cloudera’s version of the Apache Impala Hadoop-to-SQL query engine.
- Data then moves to SQL Server, another leading relational database, where it can be accessed by traditional, SQL-based business intelligence (BI) tools.
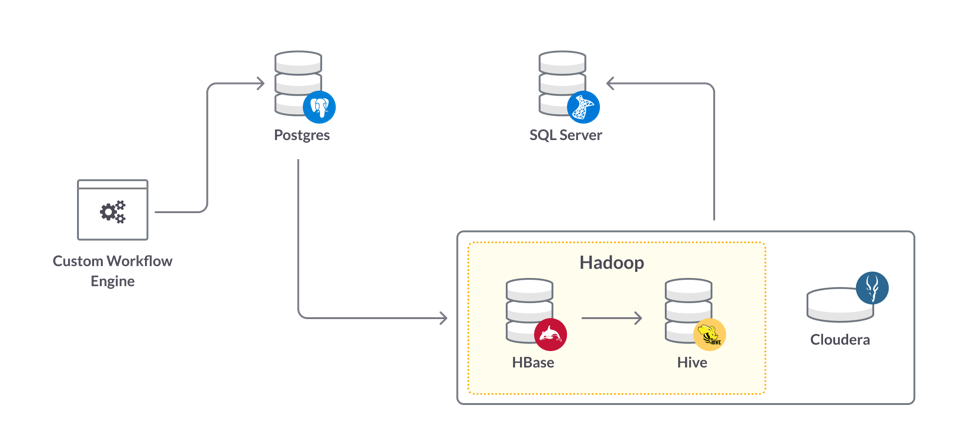
This system has worked well for batch-type analytics and other batch-oriented use cases, which is still most of what the company does with data. And, at different stages, data was available through either a traditional SQL interface, or through the ecosystem that has developed around Hadoop/HDFS (ie Impala).
Costs were reasonable, due to use of a combination of in-house, open source, and licensed software. And, because the data was in relational format, both before and after storage in HDFS, it was well-understood and orderly, compared to much of the data that is often stored in NoSQL systems.
However, the company is moving into real-time operational analytics, machine learning (ML), and AI. Looking at ML and AI highlighted many of the issues with the analytics processing core at the company:
- Stale data. Data is batch-processed several times as it moves through the system. At each step, analytics are being run on older and older data. Yet, as the prospect of implementing AI showed, it’s the newest data that’s often the most valuable.
- Loss of information. As data moves into a relational database (PostgreSQL), then into a NoSQL storage engine (HDFS), then into a cache-like query system (Cloudera Impala), and finally to another relational database (Microsoft SQL Server), the level of detail in the data that can be pulled through at each step is compromised.
- Clumsy processes. All of the steps together have considerable operational overhead, and specific steps have their own awkward aspects. For instance, Cloudera Impala works by taking in entire files of data from Hive and making them available for fast queries. Updating data means generating entire new files and sending them to Impala.
- Operational complexity. The company has had to develop and maintain considerable technical expertise dedicated just to keeping things going. This ties up people who could otherwise be building new solutions.
- Not future-ready. As the company found when it wanted to move to ML and AI, their complex infrastructure prevented the embrace of new technology.
Moving to Kafka and SingleStore
The previous architecture used by the technical services company had been blocking their path to the future. So they’re moving to a new, simpler architecture, featuring streaming data and processing through SingleStore, with support for ML and AI. The company will even be driving robotics processes. They will track and log changes to the data. This will allow them to have a sort of “time travel,” as they refer to it.
The company has described what they need in the new platform:
- Simplicity. Eliminate Hadoop to reduce complexity and delays. Eliminate Impala to cut out 40-50 minute waits to load big tables on updates.
- Data sources. Oracle, Salesforce, Sharepoint, SQL Server, Postres (100-plus sources).
- Concurrent processing. Scale from 20-25 concurrent jobs, maximum, to 200 or more.
- Query types. Simple, complex, hierarchical (analytics), aggregates, time-series; ad hoc.
- Query speed. Cut ETL from 12 hours to 1 hour or less.
- SQL support. Most of the company’s engineers are strong SQL developers – but they need a scalable platform, not a traditional, single-process relational database.
- Business benefits. Take processing past thresholds that are currently being reached; reduce worker wait times (more jobs/day, more data/day, distributed container support).
What platform could do the job? As one of the project leads puts it, “We were awesomely pleased when we saw SingleStore. We can enter SQL queries and get the result in no time. This, we thought, can solve a lot of problems.”
The company quickly knew that Kafka would be the best way to ingest data streaming in at high volume. So, when they investigated SingleStore, they were especially happy to find the Kafka pipeline capability, including exactly-once updating, in line with Kafka. This helped them move Kafka to a larger role in their planning – from only being used to feed AI, to a streaming pipeline for all their analytics data.
The company is still in the design phase. Kafka and SingleStore have handled all the use cases they’ve thrown at the combination so far. They can replicate the same environment in the cloud and on-premises, then move workloads wherever it’s cost-effective and convenient.
The company can also mix and match rowstore and columnstore tables. For instance, data can flow into a rowstore table, where they will perform concurrent transformations on it. They then aggregate new and existing data in a columnstore table, eventually totaling petabytes of information.
Unlike most databases – such as with the Impala solution and Parquet files, in the current solution – SingleStore can update columnstore tables without having to re-build and re-load them. (This capability is enhanced in the upcoming SingleStoreDB Self-Managed 7.0, with faster seeks and, as a result, faster updates.)
This matches one of the company’s biggest use cases: support for lab queries. The labs need nearly infinite disk space for ongoing storage of data. They have columnstore tables with hundreds of columns, and their old solution had trouble pulling them through the Hive metastore. SingleStore gives them the ability to support thousands of discrete columns. Since SingleStore also has built-in support for JSON, as the project lead puts it, “there really are no limits.” They can then move selected data into rowstore tables for intensive processing and analysis.
The company stopped looking at alternatives after it found SingleStore. For instance, Citus for Postgres provides a distributed query engine, Citus, on top of a very mature database, PostgreSQL. “However,” says the project lead, “it has limitations, and requires a lot of up-front planning to make it work.”
Design and Implementation: Airflow, Kafka, and SingleStore, plus Spark
There are many databases that can do some of these things in a pilot project, with limited amounts of data – or, in particular, with limited numbers of users. But, as the project lead says, “The beauty of SingleStore is, if you get more users, you just add more nodes.”
The technical services company will use Airflow as a scheduler. Airflow sends commands to remote systems to send their data. Commands such as Create Pipeline get data flowing. Airflow sends the data to be ingested into a Kafka topic, then drops the connection to the remote system. Airflow doesn’t hold data itself; it’s simply there for orchestration.
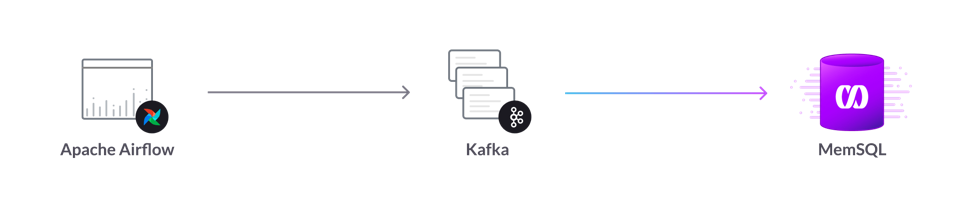
The company then uses a MySQL interface – SingleStore is MySQL wire protocol-compatible – to ingest the data into SingleStore. With the data in SingleStore, they have almost unlimited options. They can run Python code against database data, using SingleStore transforms and Pipelines to stored procedures.
“Our only cost,” says the team lead, “is team members’ time to develop it. This works for us, even in cases where we have a one-man design team. Data engineers leverage the framework that we’ve built, keeping costs low.”
The former analytics processing framework, complex as it was, included only open source code. “This is the first time we’ve introduced subscription-based licensing” into their analytics core, says the project lead. “We want to show the value. In the long run, it saves money.”
They will be exploring how best to use Spark with SingleStore – a solution many SingleStore users have pioneered. For instance, they are intrigued by the wind turbine use case that SingleStore co-CEO Nikita Shamgunov demonstrated at Spark Summit. This is a real, live use case for the company.
They currently have a high-performance cluster with petabytes of storage. They will be scaling up their solution with a combination of SingleStore and Spark, running against a huge dataset, kept up to date in real time.
“The core database, by itself, is the most valuable piece for us,” says the project lead. “And the native Kafka integration is awesome. Once we also get the integration with Spark optimized – we’ve got nothing else that compares to it, that we’ve looked at so far.
The company runs Docker containers for nearly everything they do and is building up use of Kubernetes. They have been pleased to learn that Singlestore Helios, SingleStore’s new, elastic cloud database, is also built on Kubernetes. It gives the project lead a sense of what they can do with SingleStore and Kubernetes, going forward. “That’s the point of containerization,” says the project lead. “Within a minute or two, you have a full cluster.”
“We’ve gone from a screen full of logos,” says the project lead, “in our old architecture, to three logos: Airflow, Kafka, and SingleStore. We only want to deal with one database.” And SingleStore will more than do the job.




