
AWS re:Invent, which ended yesterday, had an estimated 50,000-plus people in attendance. Since the first AWS re:Invent 6 years ago, Amazon has gone from an up-and-coming innovator in the IT software space to the 800-pound gorilla dominating enterprise software. Given their outsized role for our customers and partners, we thought we would share news and a few highlights from our time at the show.
Unsurprisingly, AWS spent a lot of time discussing the emerging fields of AI and machine learning. The main focus was on tooling for delivering advanced analytics easily. While most of the tooling is software, Amazon also announced hardware: a new processor, called Inferentia, that is promised to run AI applications with high performance and at low cost. This follows a similar move into AI processors by Google.

AWS had a lot to say about databases. They are continuing to take popular open source databases and package them as services, a worrying trend that already affected the creators of MongoDB and Elastic. Now, the creators of Kafka are the next victims, with the launch of AWS Managed Kafka as a public preview.
The history of AWS monetizing open source projects without contributing cash or code to the projects has some calling out the negative impact of AWS Managed Kafka and similar business tactics on these communities, and has many pushing for a change in the open source licensing model to protect the viability of these projects.
AWS usually supports trends fairly early in Gartner’s famous Hype Cycle, and blockchain is no exception. The Amazon Quantum Ledger Database is a new, managed blockchain database for distributed hyperledger applications.
The topic that got the most attention was about Amazon’s own infrastructure. Oracle CEO Larry Ellison has made much of the fact that Amazon has made heavy use of Oracle databases, and Amazon, in return, keeps promising to get completely off of any Oracle licenses. Amazon is promising to be mostly Oracle-free by year-end 2018 and completely so before 2020. This follows a larger trend we are seeing across the industry; as more and more enterprises and governments move to the cloud, they are taking the opportunity to replace aging data infrastructure with NewSQL databases like SingleStore, Amazon Aurora, and Google Spanner.
AWS also announced new databases and new database capabilities. Amazon Timestream is a timeseries database. (It’s possible to structure data flows so both time-stamped changes and updated records come out of it, but Timestream is about splitting those processes.) The new offering is serverless, which means that customers have little visibility into the operational basis for their costs.
There’s a new feature for Amazon’s premier relational database, Amazon Aurora Global Database, which promises replication across regions, in support of high availability and disaster recovery. And Amazon DynamoDB added transactional support and read/write capacity provisioning. Amazon knows that getting control of their customers data locks them into the AWS platform long-term, and these new features will allow the company to capture even more data workloads and storage.
The data announcements at AWS culminated in near-earth orbit. AWS Ground Station provides data download and processing support for any of the many thousands of satellites currently circling the planet.
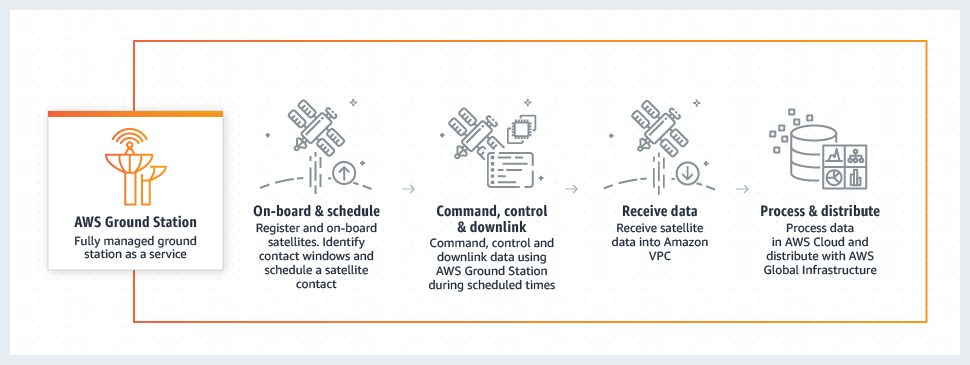
AWS Ground Station provides data services for satellites. (Image courtesy AWS.)
The SingleStore booth was very busy, with discussions mirroring the larger event topics of modernizing data infrastructure and the creation of new, more demanding, data-intensive applications. And Oracle was not the only database vendor that organizations are wary of.
We heard continued concerns expressed about the creeping costs and lock-in on Amazon’s closed ecosystem, where the lure of the ease of consumption of the services available comes with unexpected barbs and long-term risks. Gartner’s prediction that 90% of enterprises will adopt hybrid infrastructure management appears to be well corroborated by the attitudes of the mature IT organizations we have spoken with.
New SingleStore offerings, such as the new SingleStoreDB Self-Managed 6.7 release and the new free tier for SingleStore, attracted strong interest. For more on both, view our recent webinar on SingleStoreDB Self-Managed 6.7.





