
If you’ve ever had a web application freeze while it was calculating something, chances are that performing that computation in a JavaScript Web Worker would help. In this blog post, SingleStore’s David Gomes explains how to use JavaScript Web Workers, together with React and Redux, to create fully-client side web applications.
Introduction
In this article, we’re going to explore how we leverage Web Workers, together with React & Redux, to build a fully client-side web application here at SingleStore. My goal with this article is to highlight a specific use case of Web Workers, as well as detail how we were able to build on top of the relatively low-level Web Workers API to make our code more organized and easier to iterate on.
Web Workers are one of the most underrated features of JavaScript. Despite having been around for 10 years, they’re relatively unknown, and are not used very often in web applications. Most desktop GUI applications take advantage of multithreading to make sure their UIs are responsive while the application does other background work. Historically, web applications haven’t been able to apply the same strategy, but that’s where Web Workers come in.
As an example, if you’re building a CodePen-like application and want to parse the code in the editor, and add syntax highlighting to it, a Web Worker is a great idea, since you can perform the work in parallel, without incurring the large network cost of sending the entire code to a web server.
So, what is a Web Worker? A Web Worker is a feature of JavaScript that enables parallel execution of code in the browser. In other words, it allows for the execution of JavaScript in the background. The main use case of Web Workers is performing expensive computations in the browser without blocking the main thread, where the DOM is rendered. If you’ve ever had a web application freeze while it was calculating something, chances are that performing that computation in a Web Worker would help.
In this blog post, we’re going to dive into our usage of Web Workers in a specific application. That application is SingleStore Studio, a visual user interface that allows our customers to easily monitor, debug, and manage their SingleStore clusters. (There are also use cases for business intelligence tools. Studio, because it’s so tightly integrated with SingleStore, is better able to give you SingleStore-specific and schema and monitoring information.)
SingleStore Studio is implemented as a fully client-side web application that runs in the browser. It connects to SingleStore and runs queries on behalf of the user in order to show all kinds of information about the state of the cluster. Additionally, this tool also allows users to run arbitrary queries against their cluster via an embedded SQL development environment.
Integrating React & Redux with Web Workers
The frontend of SingleStore Studio is implemented using React for the view layer and Redux for the application state layer. The “backend” of the application runs in the browser inside a Web Worker. This allows us to perform all the expensive work of connecting to SingleStore, running queries, and parsing the results in the background. This is convenient, since the queries Studio runs against SingleStore may return millions of rows. As such, we want to parse and clean up the outputs from these queries without blocking the main thread.
So far, all of this sounds wonderful. However, there’s one issue that I haven’t mentioned yet. How should the main thread and the Web Worker communicate?
Historically, the Web Worker API offered a shared memory protocol for coordination between the main thread and worker threads. Unfortunately, due to the Spectre Vulnerability, most browsers disabled the API. Because of this, SingleStore Studio leverages the transfer protocol to communicate. This is what the transfer protocol API looks like:
main-thread.js
expensiveComputationWorker.postMessage({ n: 8 });
expensiveComputationWorker.onmessage = (msg) => {
console.log("received message from my web worker", msg);
};worker-thread.js
onmessage = (msg) => {
console.log("received message from main thread", msg);
postMessage(getNthPrime(msg.n));
};Since the backend of our application runs inside the Web Worker, this API is too low level for our application. We need something more high level, which allows our components to easily request the data that they need from the backend.
The first thing that comes to mind is GraphQL, a query language that allows clients to declaratively state which pieces of data they need from an agreed-upon schema. So, we gave it a spin and built a GraphQL server that lives inside the Web Worker. Then, we built resolvers for each piece of data that our client could possibly need, so our components could simply tell a GraphQL client (we used Apollo) what they needed.
After a while, this approach became cumbersome, since we now had two type systems that we had to keep in sync:
- TypeScript [1]
- The GraphQL Type System
Having to write all type definitions twice slowed us down significantly [2]. Moreover, we were not taking advantage of the GraphQL query language at all. Most of the pages in our application request all the information about all the records of a given record type (e.g., all the databases in the cluster, all the nodes in the cluster, etc.). For this type of query, GraphQL is not very helpful, since we’re not taking advantage of the powerful query language at all. It makes our architecture more complex without giving us any real benefits. I actually gave a talk just about this entire experiment at React Fest last year.
So, once we decided to drop GraphQL, we explored other options. This is the flow that we wanted – and ended up achieving:
- View Layer asks for data using some custom API
- Worker computes data
- Redux is populated with data
- View is subscribed to Redux updates and eventually displays data
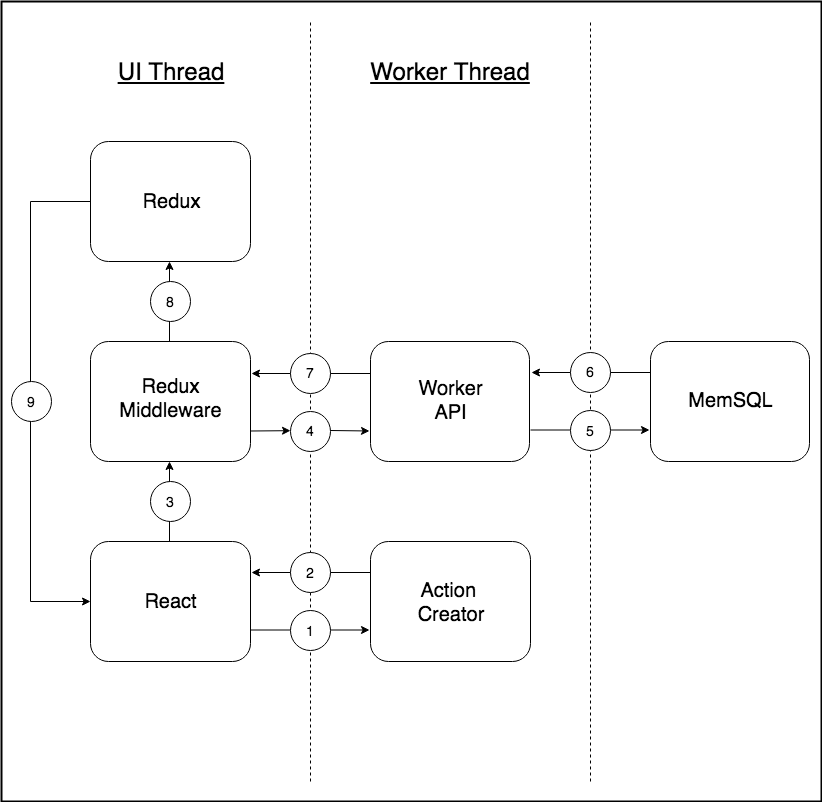
This general pattern is very standard for React+Redux applications. The interesting bit here is how to populate the Redux state (which lives on the main thread) from the worker thread. Here’s what we came up with. First, the view layer:
page-databases.tsx
import { queryDatabases } from "worker/api/schema";
class DatabasesPage {
componentDidMount() {
this.props.dispatch(queryDatabases());
}
}We can see that it’s very easy for this React component to ask for the data it needs by dispatching a Redux action. But how does it work? How is the worker thread notified of this action, and how is the Redux state populated? We implemented this using Redux middleware. (If you are not familiar with Redux middleware, I recommend the official documentation.)
We created middleware in Redux that listens to all the dispatched actions. Whenever it finds that a “worker action” was dispatched, it passes it to the web worker. A “worker action” is a specific type of Redux action object that the Redux reducers don’t listen to; instead, a “worker action” represents a specific API call on the worker thread.
The middleware looks for a specific object structure to distinguish “worker actions” from regular Redux actions. So, our Redux middleware calls the worker thread (using a custom postMessage wrapper) and the worker thread then parses the “worker action” object to figure out which API call it should run.
worker/api/schema.tsx
export const queryStructure = makeActionCreator({
name: "queryStructure",
handle: (ctx: HandlerContext): Observable => {
...
}
};The exported function from “worker/api/schema.tsx” generates a “worker action,” which the “page-databases.tsx” file dispatches. However, the function that the middleware will cause to run on the worker is the handle() function, which performs the actual work of connecting to SingleStore and returning the list of databases.
Since the actual API call returns an Observable of plain Redux actions, each such action will be sent back to the main thread, where our middleware will dispatch them, allowing the reducers to listen to them. This completes the cycle that I mentioned earlier: (main thread → worker thread → Redux (main thread)).
Observables as the output of API endpoints are extremely powerful, since they allow an API endpoint to emit multiple times. This makes the following patterns (and others) trivial:
- Emit the output of a query in batches, for a smoother experience
- Emit loading and finished (success, error) states individually, so that the Redux store contains the current state for a request (which will be shown in the view)
One final thing to note is that all of our communication between the worker thread and the main thread is JSONified. We do this so that we can easily serialize and deserialize class instances using JSON revivers. If you’re curious about the performance consequences of this, you can check out this article. (It’s equivalent to the performance of native postMessage, which uses the structured clone algorithm.)
Conclusion
Web Workers are very powerful and their simple API allows one to easily build an abstraction layer on top of them. In our case, we figured out how to integrate React, Redux, and Web Workers in a way that works very well for us. We’ve found that this framework allows us to iterate quickly while achieving our main goal of running the heavy computation work without blocking the UI. If you are interested in an open source version of this solution, please reach out to us at david@singlestore.com.
The SingleStore database is renowned for its performance, so it only makes sense that our UIs follow suit. For this reason, our frontend engineering team leverages the best web framework technologies to ensure our customers are guaranteed a stellar experience. If you are an Application Engineer with a similar passion for quality, we are hiring in Portugal and San Francisco.
[1]: SingleStore Studio is written using TypeScript.
[2]: There are some type definition generators that can help with this process. However, we found that this didn’t work well for us (we were using Flow at the time).
Thanks to Brian Chen and Carl Sverre for editing help.





