
Organizations tend to be averse to database migrations — and for good reason: they often require extensive application and code changes.
The scariest part of migrating from a legacy database to a new solution might be the application downtime associated with migrating vast amounts of data in an efficient manner. At SingleStore, we specialize in highly streamlined migration efforts using a combo of in-house features and third-party tools.
For the purpose of this guide, we will be focusing on a large-scale migration from RDS MySQL to Singlestore Helios for a high-profile marketing attribution SaaS company. The company, which we will refer to as “MarTech” in this blog, had strict migration requirements due to the nature of the application. MarTech’s application is a 24/7 fully online, customer-facing marketing attribution tool designed to help companies increase sales and commercial success.
As a result of this highly OLTP based workload, they needed minimal application downtime of less than 24 hours to completely migrate over all data and cut over the application to use Singlestore Helios. We chose a weekend that was expected to have lower-than-normal app traffic, and MarTech infomed their customers that the app would be offline for 24 hours — meaning this entire process had to be completed in less than 24 hours. Specific details about MarTech data volumes:
- Number of databases: 4
- Number of tables in each database
- Primary DB: 301
- Secondary DB: 60
- Staging DB 1: 15
- Staging DB 2: 9
- Total data size: 8.5TB
Further metrics around MarTech’s workload:
- Ingestion rate: 6,000+ rows/s
- Concurrency: 1,500 transactions/s
- Query latency: <100ms
- End user experience: <4s dashboard refresh rate
The following migration methods were considered:
- Extract the data into flat files and load it using SingleStore LOAD
- Not an ideal option because of large data size
- Upload the data to object storage or file system (S3) and use SingleStore native pipelines
- All the tables have AUTO_INCREMENT columns, which means the pipeline can be only an aggregator pipeline. This limits the parallelization of the pipeline ingestion through distributed partitions
- Use mysqldump to unload the data and load it in SingleStoreDB
- Not an ideal option because of large data size
- SingleStore Replicate: Snapshot load using third-party CDC tool Arcion
- Arcion was finalized because we were able to migrate close to 1TB of data in an hour in a S-64 SingleStoreDB workspace
Arcion has two main products similar to SingleStoreDB: Arcion Self-Hosted and Arcion Cloud. Arcion Self-Hosted was selected for this migration because a snapshot license is attainable after working with SingleStore engineers. Here’s the high-level flow:
Preparatory Steps:
1. Create a workspace group in desired cloud and region.
2. Create a workspace of desired size. For MarTech, an S-8 workspace was deployed based on the data intensity of their workload.
3. Create four target databases in SingleStore DB Cloud. It is important to select a partition count suited for your workload. By default, SingleStore creates a database with an equal number of partitions as leaf vCPU. For instance, an S-8 has 64 leaf vCPU so a database created on an S-8 will have 64 partitions by default.
In cases where you need to support high concurrency, it is recommended to use lower partitions (i.e. a higher vCPU-to-partition ratio). If you have a high ingestion requirement, it is recommended to use higher partitions. In Martech’s case, we used 16 partitions on a S-8 (i.e. 4:1 vCPU-to-partiton ratio) to facilitate their high concurrency/low latency requirement.
CREATE DATABASE <database_name> partitions N4. Create required tables in each database. SingleStoreDB is MySQL wire compliant, meaning it can act as a drop-in replacement for MySQL with minimal to no-code change. However, SingleStoreDB is a distributed SQL database and has unique optimizations to further bolster performance based on the nature of the SQL queries. A few things were considered:
- Rowstore vs Universal Storage. This option depends on the size of the data and workload type. Rowstore tables are stored strictly in RAM and are performant for pure OLTP operations. Universal Storage tables are stored in a columnar format on Disk, are meant for hybrid OLTP + OLAP workloads and are heavily compressed. Since MarTech had over 8 TB’s of data, we used a combination of columnstore tables and rowstore tables to achieve the best performance.
- Data type comparison. Migrating from MySQL meant most of the data types were matching with SingleStoreDB. AUTO_INCREMENT columns were defined as INTEGER in MySQL and were converted to BIGINT in SingleStoreDB. Similarly, some other columns were converted to BIGINT from INT. After migrating tables containing AUTO_INCREMENT, it is important to run an AUTO_INCREMENT SYNC on all tables to ensure newly generated values do not collide with original values with MySQL:
AGGREGATOR SYNC AUTO_INCREMENT
<database_name>.<table_name>ALL;- Character sets and collations. SingleStoreDB contains default character sets of utf8 and collations of utf8_general_ci. MarTech had some tables using a different character set (latin1) and a few other collations (latin1_general_cs and latin1_swedish_ci). It’s important to convert to SingleStore supported collations — such as utf8_general_ci and utf8_bin — to ensure data compatibility.
- Keys/Indexes — SHARD, SORT, PRIMARY, UNIQUE, Secondary Indexes. Shard keys determine the distribution of data across database partitions and should be selected based on common query patterns. Sort keys (only applicable on Universal Storage tables) determine how data is sorted within partitions and should be selected based on common query patterns. SingleStoreDB supports primary and unique keys. An important consideration is that columns contained in the shard key but be a subset of the primary key. Secondary hash indexes (Universal Storage) and skiplist indexes (rowstore) extraneous to shard, sort and primary/unique keys can also be created for common conditions in queries.
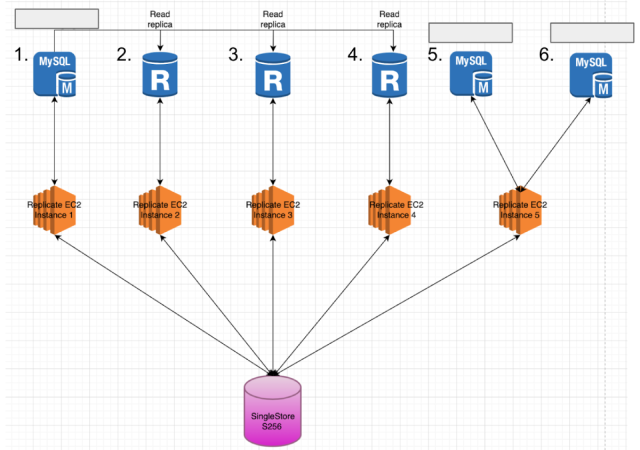
And now for the most important part of the entire operation — the actual data migration! In RDS MySQL, MarTech had six total RDS instances with the following breakdown:
- Contains Primary DB and Staging DB 2
- Read replica instance
- Read replica Instance
- Read replica instance
- Contains Secondary DB
- Contains Staging DB 1
We provisioned five AWS EC2 instances to run the replicate tool (Arcion) in parallel. Each EC2 instance will be mapped to a single MySQL RDS instance, with the last EC2 instance mapping to two EC2 instances
- Instance type: c6in.8xlarge (32 vCPU, 64 GB RAM, 50 Gbps network bandwidth)
- Storage per instance: 512 GB GP3 , 3000 IOPS and 500 MB/s disk bandwidth
- Software needed:
- JDK 8, either from a JRE or JDK installation
- MySQL Command Line
- Replicate package (available by contacting sales or solutions engineers)
- Access needed : EC2 instances should be able to connect to their corresponding RDS instances via port 3306.
To reduce the overall migration time, we decided to run five similar sized replicate instances in parallel and scale up the SingleStoreDB cluster to S-256. We decided on S-256 because it had 32 leaf nodes, and the 16 partitions in the original database would be equally distributed across leaf nodes. With an S-256, we also have enough CPU to handle four-to-five replicate instances in parallel.
After turning off the user traffic to RDS instances, run a script to get the max AUTO_INCREMENT values for all large tables and create the extractor configuration file. This will help Arcion split the migration jobs into multiple parallel jobs and reduce the total migration time.
Transfer the Primary DB extractor file and Staging DB 2 extractor file to all four EC2 instances that will replicate from Primary DB and Staging DB 2. Similarly, transfer the Secondary DB extractor file and Staging DB 1 extractor file to the EC2 instances that will replicate from Secondary DB and Staging DB 1. Each EC2 instance will run the replicate for a group of tables.
After all the tables are successfully migrated, compare the following two things on all tables:
1. Row counts between the following three components. All three should match:
- RDS MySQL
- Replicate SnapShot summary report
- Singlestore Helios
2. Max(AUTO_INCREMENT columns)
- RDS MySQL
- Singlestore Helios
After validation of data:
Scale down the SingleStoreDB cluster from S-256 to the original S-8
- Run a script to sync up the auto_increment value for the tables in all the databases. This will ensure that any newly created value will not collide with the existing values
- Drop all the tables in all four databases that were created by replicate
Although MarTech specified a maximum 24-hour downtime window, we were able to complete the entire end-to-end process in less than nine hours. After migrating to SingleStore, MarTech was able to achieve a staggering 95,000% performance improvement in their single query execution compared to RDS MySQL— yes, this is a real stat!
They were also able to register a 15x total performance improvement at the peak application concurrency of 1,500 users — a considerable improvement for a workload that consistently had processes timing out due to long-running and hanging queries. All of these benefits also came at a total cost of ownership (TCO) savings of over 50%, a critical stat for a scaling organization putting forward heavy capital into scaling the product and their customer base.
If you or your team need migration guidance from RDS MySQL or any other database, schedule some time with an engineer here to chat more about your use case and learn how SingleStore can best help you.
Chat with a SingleStore engineer today.





