This blog post shares the initial section of our recent webinar, Singlestore Helios and SingleStoreDB Self-Managed 7.0 Overview. In this first part, Rick draws the big picture as to the need for a new approach to data processing, and shows how SingleStore fits the bill. In the second and third parts, Rick introduces Singlestore Helios, the new, elastic, on-demand cloud service from SingleStore, and describes highlights of the upcoming SingleStoreDB Self-Managed 7.0.
Singlestore Helios is brand new, and SingleStoreDB Self-Managed 7.0 is the best version of our product we’ve done yet. It’s a great opportunity to be able to talk about it. I’m first going to give a SingleStore overview, describing what we built and why we built it. Describes the problems that businesses, especially large, successful business, face in meeting today’s demands, given their outdated infrastructure. Then we’ll go into the details around our launch of Singlestore Helios, our managed service, and describe the new features coming in SingleStoreDB Self-Managed 7.0. And we’ll finish up with some questions at the end.
Today’s Successful Businesses – Old and New – Use Operational Data at Scale
If you look at the most successful businesses across industries, there’s one thing that they all have in common, and that’s that they’re powered by live, operational data. They take advantage of the operational data they have to greatly enhance the customer experience and the opportunities and the way they run their business. This includes everything from Uber using the information they have about how people are calling cars to deploy more drivers when they’re needed, to figuring out how to price it, to financial companies like Goldman Sachs who are trying to figure out how to deliver the optimal experiences around portfolio analytics, online banking risk models, and such, to media companies that are delivering streaming media, and need to be able to keep track of exactly what the quality level is at any time, so they can guarantee that people are getting the best experience possible. Truly, across companies in pretty much every industry, data is the key to their success and to the differentiation that they have, becoming the best in their business.
This isn’t something that just those companies wanted. It’s something that every company wants. But, it’s hard. And it’s hard because the requirements are much higher and more complex than they’ve ever been. So data volumes are rising, which means the amount of data you have to store and manage and work on is increasing at frightening speeds. And then the complexity around that data – both because of the variety of data sources, where the data is coming from, the formats that you have to process, and the demands on what you have to deal with that, are all rising as well.
On top of that, consumers of the data have higher expectations than ever. This is true in the consumer side, where you think about things like people using the airline apps to know whether their flight is delayed or not. They expect instant notifications. Or banking applications – 15 years ago, or maybe even 10 years ago, your way of getting updates was a paper statement you got in the mail once a month. And now, if you swipe your credit card and don’t instantly see it on your app, you’re unhappy with the bank and feel like they’re failing. So expectations have risen, but not just across consumer; this also applies to enterprises as well.

The users within the enterprise expect to see the data that they need in real time. They make decisions day-to-day. It’s not just a couple analysts in the back room who have access to the data. Everyone wants access to data, and they expect it to be up-to-date and easy to understand. And so the expectations from the users have been growing tremendously as well.
And lastly, we’ve already moved from a historical view of the world, from where we’re looking back in time to try to understand what happened, to looking at what’s happening currently, what’s happening in real time. That’s not where people want to stop. They want to move on from there to even get to predictive. What’s going to happen in the future? And how can I take advantage of that? Already, today, the app that shows you a movie to rent, a book to buy, or when the car you’re booking is likely to appear, is using predictive analytics.
For internal use, people want to know about pricing opportunities, what deals are likely to be successful, what inventory will be needed where? Then, they can pro-actively move it around. The final step is to take humans off of the front line. The system can start ordering new supplies, moving inventory, and so on, automatically, then tell the humans what it’s done.
So every enterprise is on this journey, moving through that maturity cycle, and they’re all trying to get to the end as fast as possible. But they’re all struggling to keep up. The data infrastructure that we use today, that worked well enough against the previous requirements, from the last couple of decades are not keeping up with these demands, these new requirements. You’re trying to get a tighter time to insight, you’re trying to drive that time from between when data’s born to when you can get insight or take action on it, you’re trying to drive that down to zero. And the infrastructure is your bottleneck, and it’s not allowing you to do that. It’s taking minutes or hours or sometimes even days to move the data through the system, and get it to the end, when it’s too late, and you’re unable to meet the SLA that you’re trying to hit.
On top of that, with the rise of the size of the volume of data and the complexity of the data, also comes rising costs. As you try to scale the systems that you have, that weren’t designed for that level of scale – they either hit a bottleneck, or they just hit a ceiling. The cake can get bigger, so you need the system to grow, but the costs of growing to that size are so astronomical, they’re not practical.
And last, as you expose your data to, say, all of your employees versus just the incremental list, you’re moving from tens of people to hundreds, thousands, or even tens of thousands – depending on the size of your organization – all trying to get access to that data. And then they extrapolate even further as you expose it out to your customers or your partners in ways you haven’t tried to do before. The number of simultaneous users – that is, concurrency demands – just grows by orders of magnitude. And again, the data infrastructure of the past wasn’t designed to deal with that level of concurrency and still maintain the SLAs that you’re trying to hit.
How SingleStore Solves Operational Problems
All these new demands, and these trends in the industry, have created new requirements that didn’t exist before. That’s why we built SingleStore. It’s a cloud native operational database built for speed and scale. “Cloud-native” meaning it’s distributed and easy to scale on existing hardware. It’s a relational database, meaning it supports a relational model and a standard SQL interface, but with a modern architecture under the covers, to deliver the speed and the scale requirements that your new, modern applications need.
SingleStore supports the workload we call operational analytics, where you’re doing primarily an analytics workload, or it’s aggregations and group-bys, table scans of large sets of data, and all where you need to meet an SLA. The database has to be resilient and available and durable in a way that the existing data warehouse technologies are not. And, when the intersection of those requirements is where the existing architecture is failing, SingleStore does things an order of magnitude better.
An example is portfolio analytics, where bank customers want to look at their portfolios and have up-to-date market data in real time. They’re able to quickly drill in and understand how their portfolio is performing, and do what-if analysis to see how it would shift if they make a change. And they want to be able to do that even when the market’s busy, and hundreds or thousands of users all connect at the same time. The system scales smoothly, meeting its SLAs at every step, to deliver what customers need. And predictive analytics is just one of many applications that SingleStore is used for.
As an organization moves through the maturity curve, starting to do more predictive ML and AI, where you need a highly scalable system that’s familiar and easy to use, but still delivers on the speed and scale of the type of mathematical operations you need to support an ML model. SingleStore supports that very well.
What’s driving people to consider new architectures – more so now than any time before – is the move to cloud and the need to replace the legacy architectures. Often, the legacy architecture is dependent on custom hardware, particularly if you’re using an appliance-based technology. And as we move to cloud, there’s a realization you just can’t take that architecture, let alone that appliance, to the cloud.
And so data architects and enterprises are being forced to rethink, “Hey, how should I make this work in the cloud?” And therefore, they’re open to looking at newer, more modern architectures, which is opening up opportunities for technologies like SingleStore to replace the legacy systems. But you don’t have to believe me. You can look at who our customers are. We have half of the top 10 banks in North America who are using us, like I said, for analytics fraud, real-time fraud analysis, and risk analytics. We have telcos who are using us for doing things like managing the amount of data coming in, as they move from 3G to 5G, with the size and complexity of the data growing tremendously, and the existing systems can’t keep up.

Large media companies like Comcast, Hulu, Pandora are using us to track and evaluate the quality of their streaming media to make sure that their customers are having the best experience. (SSIMWAVE, which specializes in this, is using SingleStore to power not only internal workloads, but customer-facing workloads as well. – Ed.) And really, right across pretty much all industries, we find this pattern showing up more and more, as customers are trying to meet the requirements in these new model workloads, and they need an infrastructure that can support the speed and scale, in order for them to realize and meet their requirements.
So how does SingleStore fit into your architecture? You can think of it as an operational database that supports both analytics and custom applications. So – whether you’re doing dashboards or ad hoc queries, and running third-party BI tools like Tableau or Looker, or building custom dashboards or custom applications to do real-time decisioning or Internet of Things (IOT), SingleStore sits as the database, or the data storage layer, underneath any of those applications or tools.
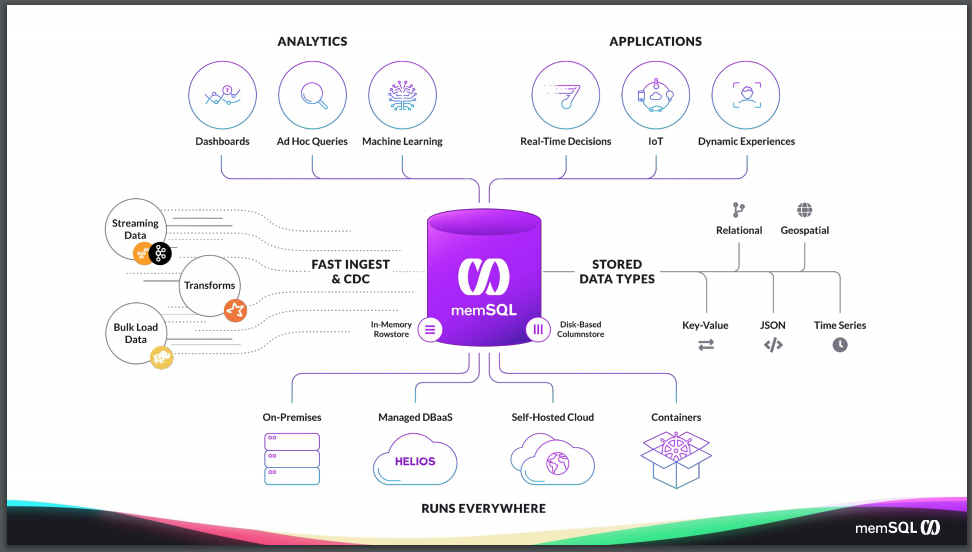
And when you need to bring data in via native connectivity, things like Kafka, as well as NoSQL back-end storage systems like HDFS, and any of the cloud blob storage like S3 or Azure blob or Google blob storage, as well as being able to bring data in easily from relational database systems such as Oracle or SQL Server or MySQL or PostgreSQL. And programmatic systems like Spark – there’s a native connector to bring data in from Spark.
No matter how you’re bringing the data in or how it’s coming into the system, SingleStore can easily connect to it. And internally, SingleStore can store any kind of data type, whether it’s relational standard data in tables, geospatial data, JSON data, you can have a native column of type JSON, so you can easily store JSON information but also project out properties and index them so you can have fast query access to that data. And SingleStore does very well with time series data, also.
And all of this can be run on the infrastructure that works best for your business, whether it’s you running your software on-premises, either bare-metal or on VMs, or whether you want to self-host, or manage the software in the cloud, or you can run it using Kubernetes on-premises. And lastly, if you don’t want to run it yourself, you can use Singlestore Helios. We will manage the underlying infrastructure for you, and you can focus on just building up your database.
Now, there are a lot of different database companies out there, all claiming to be the thing you need. So what makes SingleStore unique? What makes us different than all the other players out there? So one is that we are built from the beginning as a distributed cloud-native architecture. It’s a shared-nothing distributed system that can run on industry-standard hardware. When you install SingleStore, and if you need more capacity, you simply add more nodes to the system. You can do that as an online operation and grow the cluster as large as you need it, or shrink it down if you don’t need the capacity.
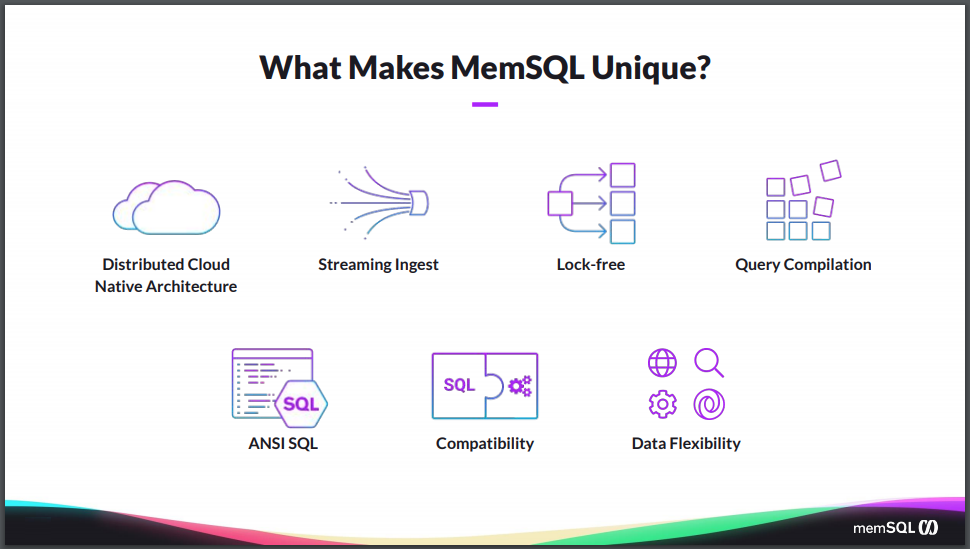
Streaming ingest has been a key focus for the company from day one, with our Pipelines feature in particular, that allows you to bring data in from other parallel systems like Kafka or the blob storage technologies in the cloud. So you can massively bring it in, in parallel, with exactly-once semantics.
But underneath the covers, the thing that makes SingleStore truly unique is the architecture. Most legacy databases were built on a data structure called the B-tree. B-trees were built around getting data off spinning disks efficiently and very fast. But the world has moved on, and technology has moved on, and spinning disks are no longer the standard mechanism. There’s no reason to stay tied down to that data structure.
So SingleStore, because it was focused more on newer hardware, and places where memory is much more accessible, uses a data structure called a skip list. And skip lists are much more efficient, especially if you want to build them lock-free, so they don’t have the same locking semantics. Whereas, B-trees are a lot more prone to locking.
That’s the underlying mechanism that makes it possible for SingleStore to stream data on ingest. It will continue to let you run queries at the same time. This gives SingleStore the scale and the concurrency and the ability to get the performance that you need. Coupled with innovations like query compilation that make our queries run faster. And making use of SIMD instructions within the processor to do vectorization and a host of other innovations at the query compilation space. These are what give us our speed advantage.
And we couple that with an interface that’s familiar, and it’s compatible with what your people already know how to use. It’s ANSI SQL compliant. We support pretty much all the standard SQL functions capabilities in the ANSI SQL standard and even further, we’re wire-level protocol compatible with MySQL. So the existing ecosystem of tools, whether it’s BI tools or ETL tools or programmatic tools, all work with SingleStore right out of the box.
And, as I mentioned, SingleStore supports all the different data sources that you might want to use, giving you the flexibility to store the data in whatever format and shape that make the most sense for your application. It’s the combination of these that make SingleStore so powerful to use across your different applications and use cases.