
Our new database-as-a-service offering, Singlestore Helios, was relatively easy to create – and will be easier to maintain – thanks to Kubernetes. The cloud-native container management software has been updated to more fully support stateful applications. This has made it particularly useful for creating and deploying Singlestore Helios, as we describe here.
From Cloud-Native to Cloud Service
SingleStore is a distributed, cloud-native SQL database that provides in-memory rowstore and on-disk columnstore to meet the needs of transactional and analytic workloads. SingleStore was designed to be run in the cloud from the start. More than half of our customers run SingleStore on major cloud providers, including Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure.
Even with the relative simplicity of deploying infrastructure in the cloud, more and more of our customers are looking for SingleStore to handle infrastructure monitoring, cluster configuration, management, maintenance, and support, freeing customers to focus on application development and accelerating their overall pace of innovation.
Singlestore Helios delivers such a “managed service” for the SingleStore database. Thanks to the power of Kubernetes and the advancements made in that community, we were able to build an enterprise database platform-as-a-service with a very small team in just six months, a fraction of the time it would have taken previously.
Making Singlestore Helios Portable
Many of the members of the SingleStore team have built SaaS offerings on other platforms, and one of the key things we’ve learned is that applications developed on one cloud platform are not inherently portable to another platform. If you want to be able to move workloads from one platform to another, you have to make careful design choices.
Each cloud provider builds unique features, services, and methods of operation into their offerings to reflect their own ideas as to what users need and to gain competitive advantage. These differences make it harder for customers to move resources – code, data, and operational infrastructure – from one cloud to another. This stickiness, which is often very strong indeed, benefits the cloud provider. Switching becomes expensive. Additionally, developers and operations people become expert on one platform, and have a steep learning curve if they want to move to another.
In response, many companies now follow a “multi-cloud” strategy, where they deploy their IT assets across 2 or more providers. By developing a cloud-agnostic offering, we sought to empower SingleStore customers to deploy their database on the infrastructure of their choice, so that it works the same way across clouds. With cloud provider-specific services like AWS Aurora, or Microsoft SQL Database on Azure, this easy portability disappears.
Achieving True Portability with Kubernetes
Kubernetes allows application containers to be run on multiple platforms, thus reducing the development cost needed to be infrastructure agnostic, and it’s proven at large scale – for example, Netflix serves 139 million customers from their Kubernetes-based platform. And, with Kubernetes 1.5, a new capability called StatefulSets was introduced. StatefulSets give devops staffers resources for dealing with stateful containers, including both ephemeral and persistent storage volumes.
When we began developing our managed service, we actually began by using the Google Kubernetes Engine (GKE). What we discovered was that while Amazon provides Elastic Kubernetes Service (EKS), and Microsoft provides Azure Kubernetes Service (AKS), each of these offerings runs different versions of Kubernetes.
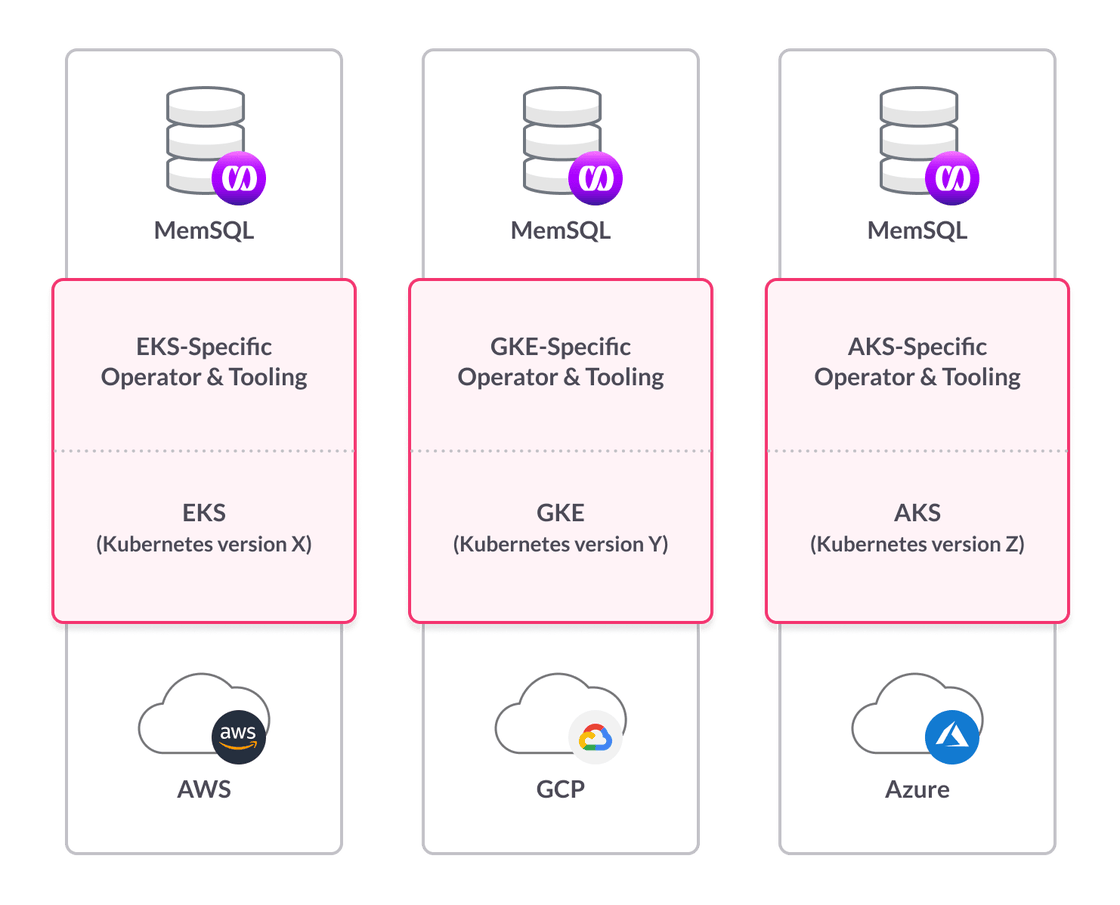
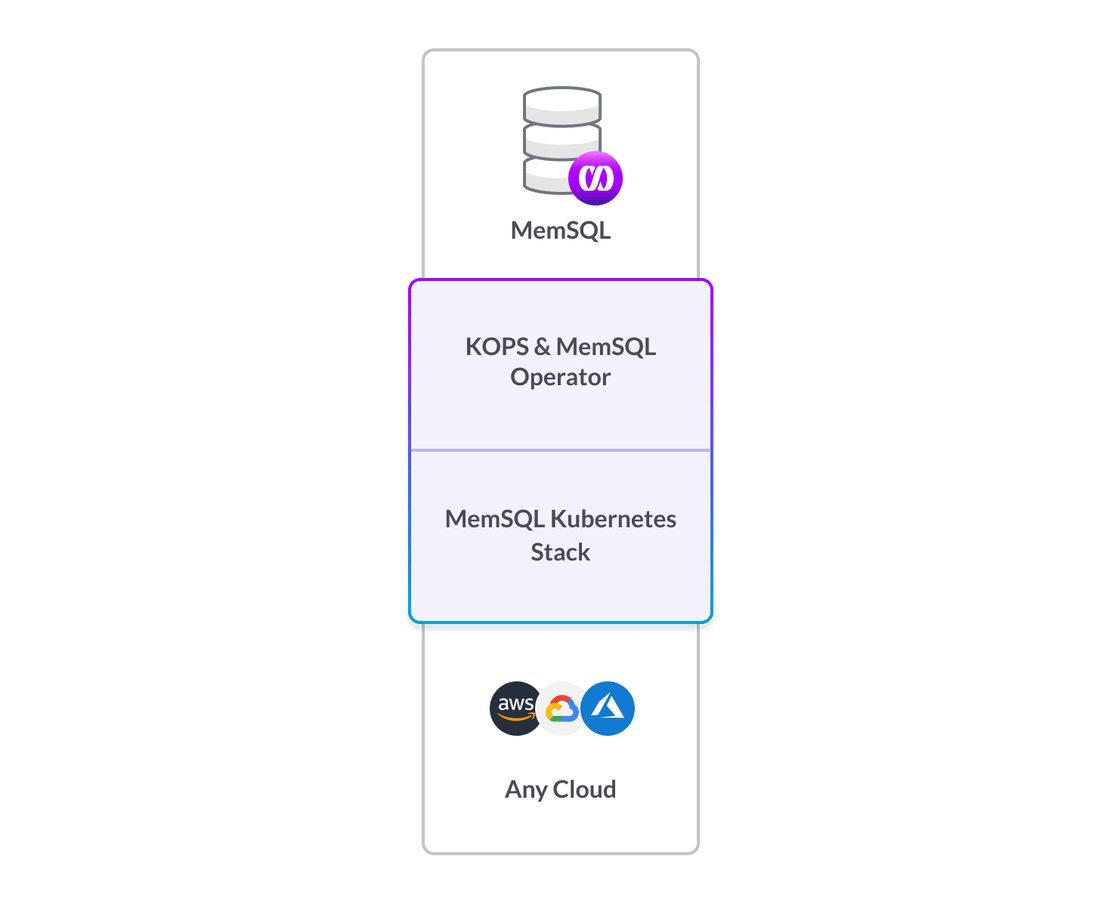
In some cases, the Kubernetes version on offer is significantly outdated. Also, each is implemented in such a way as to make it hard to migrate applications and services between them. Providing true platform portability was incredibly important to us, so we made the decision not to use EKS, GKE, or AKS. Instead, we chose to deploy our own Kubernetes stack on each of the cloud platforms.
We needed a way to repeatedly deploy infrastructure on each of the clouds in each of the regions we wanted to support. There are currently 16 AWS regions, 15 GCP regions, and 54 (!) Azure regions. That’s an unreasonable amount of infrastructure to manually deploy. Enter Kubernetes Operations (KOPS).
KOPS is an open-source tool for creating, destroying, upgrading, and maintaining Kubernetes clusters. KOPS provides a way for kubernetes and kubectl to interact with our Docker containers. By using KOPS we are able to programmatically deploy Kubernetes clusters to each of the regions we want to support, and then tie the deployments into our back-end infrastructure to create SingleStore clusters.
Creating a Kubernetes Operator
In the past, SingleStore was managed using a stateful ops tool that ran individual clients on each of the SingleStore nodes. This type of architecture is problematic when the master and client get out of sync, or if the client processes crash, or if they fail to communicate with the SingleStore engine.
In light of this, last year we built a new set of stateless tools that interact directly with SingleStore via an engine interface called memsqlctl. Because the memsqlctl interface is built into the engine, users don’t have to worry about the version getting out of sync, or about the client thinking it’s in a different state than the engine expects.
SingleStorectl seemed like the perfect way to manage SingleStore nodes in a Kubernetes cluster, but we needed a way for Kubernetes to communicate with memsqlctl directly.
In order to allow Kubernetes to manage SingleStore operations, such as adding nodes or rebalancing the cluster, we created a Kubernetes Operator. In Kubernetes, an Operator is a process that allows Kubernetes to interface with Custom Resources like SingleStore. Both the ability and the need to create Operators was introduced, along with StatefulSets, in Kubernetes 1.5, as mentioned above.
Custom Resources for the Kubernetes Operator
We began by creating a Custom Resource Definition (CRD) – a pre-defined structure, for use by Kubernetes Operators – for memsql. Our CRD looks like this:
memsql-cluster-crd.yaml
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: memsqlclusters.singlestore.com
spec:
group: singlestore.com
names:
kind: SingleStoreCluster
listKind: SingleStoreClusterList
plural: memsqlclusters
singular: memsqlcluster
shortNames:
- memsql
scope: Namespaced
version: v1alpha1
subresources:
status:{} additionalPrinterColumns:
- name: Aggregators
type: integer
description: Number of SingleStore Aggregators
JSONPath: .spec.aggregatorSpec.count
- name: Leaves
type: integer
description: Number of SingleStore Leaves (per availability group)
JSONPath: .spec.leafSpec.count
- name: Redundancy Level
type: integer
description: Redundancy level of SingleStore Cluster
JSONPath: .spec.redundancyLevel
- name: Age
type: date
JSONPath: .metadata.creationTimestamp
Then we create a Custom Resource (CR) from that CRD.
memsql-cluster.yaml
apiVersion: singlestore.com/v1alpha1
kind: SingleStoreCluster
metadata:
name: memsql-cluster
spec:
license: "memsql_license"
releaseID: 722ce44d-6f95-4855-b093-9802a9ae7cc9
redundancyLevel: 1
aggregatorSpec:
count: 3
height: 0.5
storageGB: 256
storageClass: standard
leafSpec:
count: 1
height: 1
storageGB: 1024
storageClass: standard
The beta SingleStore Operator running in Kubernetes understands that the memsql-cluster.yaml specifies the attributes of a SingleStore cluster, and it creates nodes based on the releaseid and aggregator and leaf node specs listed in the custom resource.
Benefits of Kubernetes and Singlestore Helios Infrastructure
Our original goal was to get SingleStore running in containers managed by Kubernetes for portability and ease of management. It turns out that there are a number of other benefits that we can take advantage of by building on the Kubernetes architecture.
Online Upgrades
The SingleStore architecture is composed of master aggregators, child aggregators, and leaf nodes that run in highly-available pairs. Each of our nodes is running in a container, and we have created independent availability groups for the nodes. This means that when we want to perform an upgrade of SingleStore, we can simply launch containers with the updated memsql process. By replacing the leaf containers one availability group at a time, then the child aggregators, and then the master aggregator, we can perform an online upgrade of the entire cluster, with no downtime for data manipulation language (DML) operations.
Declarative Configuration
Kubernetes uses a declarative configuration to specify cluster resources. This means that it monitors the configuration yaml files and, if the contents of the files change, Kubernetes automatically re-configures the cluster to match. So cluster configuration can be changed at any time; and, because Kubernetes and the SingleStore Operator understand how to handle SingleStore operations, the cluster configuration can change seamlessly, initiated by nothing more than a configuration file update.
Recovering from Failure
Kubernetes is designed to monitor all the containers currently running and, if a host fails or disappears, Kubernetes creates a replacement node from the appropriate container image automatically. Because SingleStore is a distributed and fault-tolerant database, this means that not only is the database workload unaffected by the failure; Kubernetes resolves the issue automatically, the database recovers the replaced node, and no user input is required.
This capability works well in the cloud, because you can easily add nodes on an as-needed basis – only paying for what you’re using, while you’re using it. So Kubernetes’ ability to scale, and to support auto-scaling, only works well in the cloud, or in a cloud-like on-premises environment.
Scalability – Scale Up/Scale Down
By the same mechanism used to replace failed instances, Kubernetes can add new instances to, or remove instances from, a cluster, in order to handle scale-up and scale-down operators. The Operator is also designed to trigger rebalances, meaning that the database information is automatically redistributed within the system when the cluster grows or shrinks.
In this initial release of Singlestore Helios, the customer requests increases or decreases in the cluster size from SingleStore, which is much more convenient than making the changes themselves. Internally, this changes a state file that causes the Operator to implement the change. In the future, the Operator gives us a growth path to add a frequently requested feature: auto-resizing of clusters as capacity requirements change.
Parting Thoughts
Using Kubernetes allowed us to accomplish a tremendous amount with a small team, in a few months of work. We didn’t have to write a lot of new code – and don’t have a ton of code to maintain – because we can leverage so much of the Kubernetes infrastructure. Our code will also benefit from improvements made to that infrastructure over time.
Integrating SingleStore with Kubernetes allowed us to build a truly cloud-agnostic deployment platform for the SingleStore database, but it also provided a platform for us to provide new features and increased flexibility over traditional deployment architectures. Because of the declarative nature of Kubernetes, and because we built a custom SingleStore Operator for Kubernetes, we can make it easier to create repeatable and proven processes for all types of SingleStore operations. As a result, we were able to build this with just a couple of experienced people over a period of roughly six months.
Now that we have a flexible and scalable architecture and infrastructure, we can continue to build capabilities on top of the platform. We are already considering features such as region-to-region disaster recovery, expanded operational simplicity – with cluster-level APIs for creating, terminating, or resizing clusters – and building out our customer portal with telemetry and data management tools to let our customers better leverage their data.
This is just the beginning..





