
SingleStore Helios
SingleStore Helios® is a cloud database-as-a-service available on leading public clouds and delivers elastic scalability, high availability and exceptional price-performance for your applications, without the burden of managing your data infrastructure. SingleStore Helios scales storage independently of compute and includes Jupyter notebooks, data integration services and a compute service for running AI workloads — meaning developers, ML engineers and data engineers can quickly build awesome things together.
Faster JSON analytics
100-1500x
Query latency
milliseconds
Upserts per second
millions
Scalability
infinite
Build without limits
Designed for (and by) developers and architects, SingleStore supports the world’s most demanding, real-time applications.
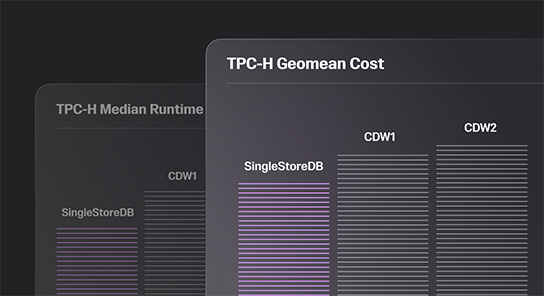
Low latency, high concurrency
Single-digit millisecond response times on large datasets across hundreds of concurrent users running complex queries
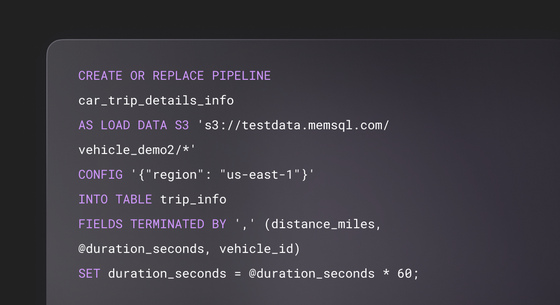
Fast ingestion
SingleStore Pipelines offer blazing fast data ingestion (with optional transforms) from multiple data sources such as Kafka, Amazon S3 and HDFS
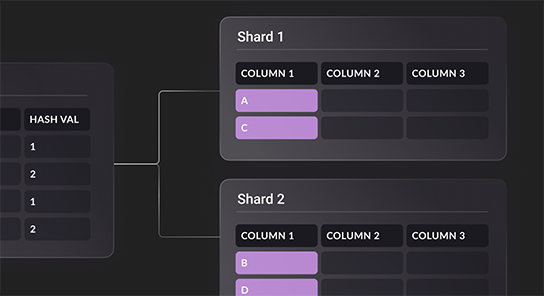
Horizontal scalability
Scale out architecture + separation of storage and compute for optimizing price-performance.
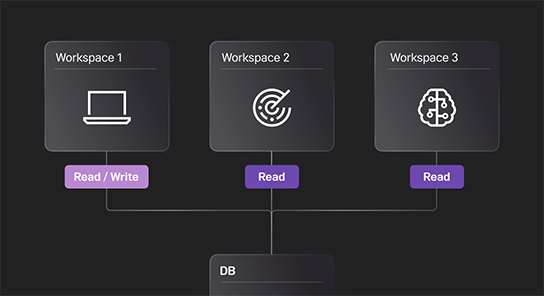
Workspaces
Workspaces allow you to scale compute independently while workloads run on shared data.
Build faster
Tap into the simplicity and programmability of MySQL and MongoDB® wire-protocol compatibility for structured, semi-structured and unstructured data.

SQL
Familiar, powerful SQL for writing and retrieving data. ACID compliant transactions
Multi-model
Relational, JSON/BSON documents, vector search, full-text search, time-series, geospatial, key-value
Unified table type
Unique Universal Storage (rowstore + columnstore) for high performance transactions and analytics
Collaboration
Leverage Notebooks for quickly developing, sharing and collaborating on SQL and Python projects
Vector + Full-text Search
Fast K-NN and ANN vector search with IVF, HNSW and PQ algorithms. Plus, full text-search for fuzzy or exact text matching
Best of SQL + NoSQL
Power 100-1,500x faster JSON analytics with SingleStore Kai™, an API for connecting to MongoDB® applications
Build for your enterprise
With security, high availability, disaster recovery and operational ease built in, SingleStore allows you to focus on creating value for your customers — without having to worry about operational aspects of your data platform.

Security
For data at rest and in motion, provide authentication, authorization and accounting using tools like Okta, Ping and Azure AD, and audit logging

Compliance
Security and compliance certifications including ISO/IEC 27001, SOC 2 Type 2, Privacy Shield, CCPA, GDPR and HIPAA.
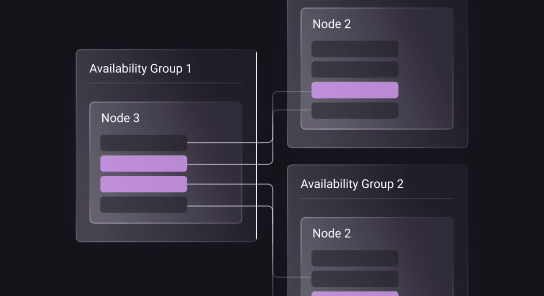
Availability
Ensure high availability for your mission-critical applications with SLA guarantees, the ability to recover databases to any point in time and multi-AZ failover
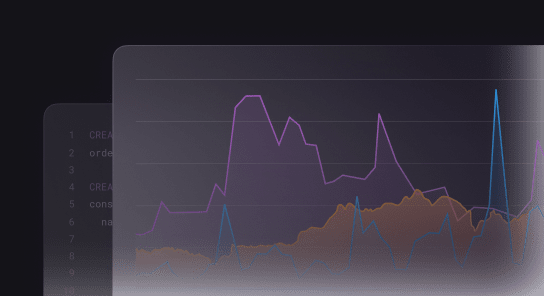
Manageability
It’s easy to optimize the performance of your databases with built-in observability, elastic scalability and API-powered database operations.
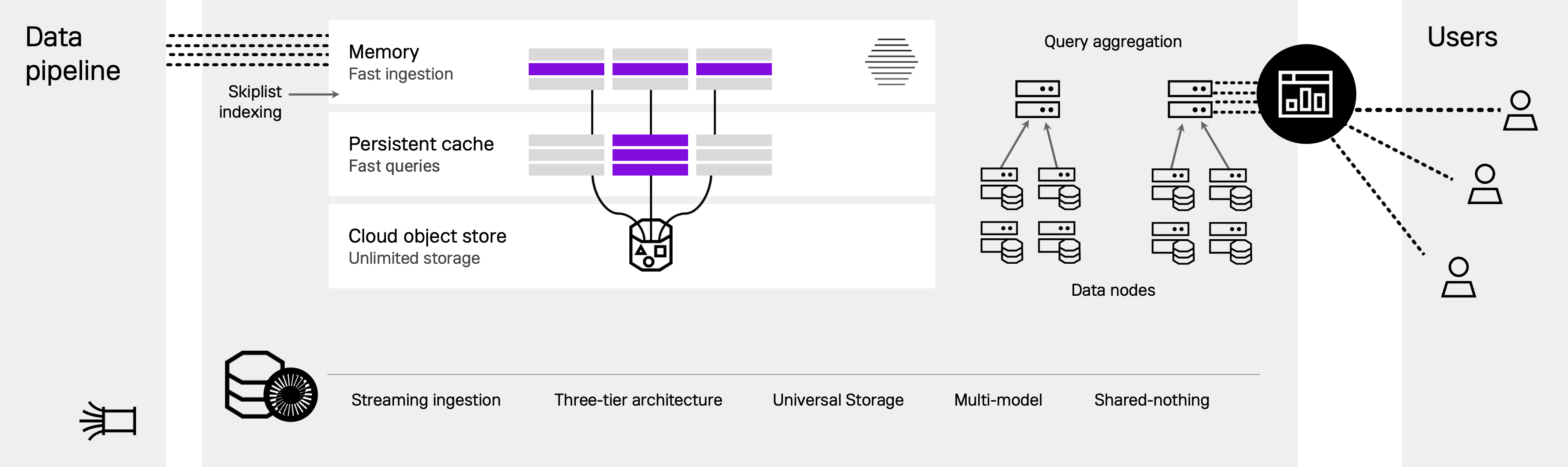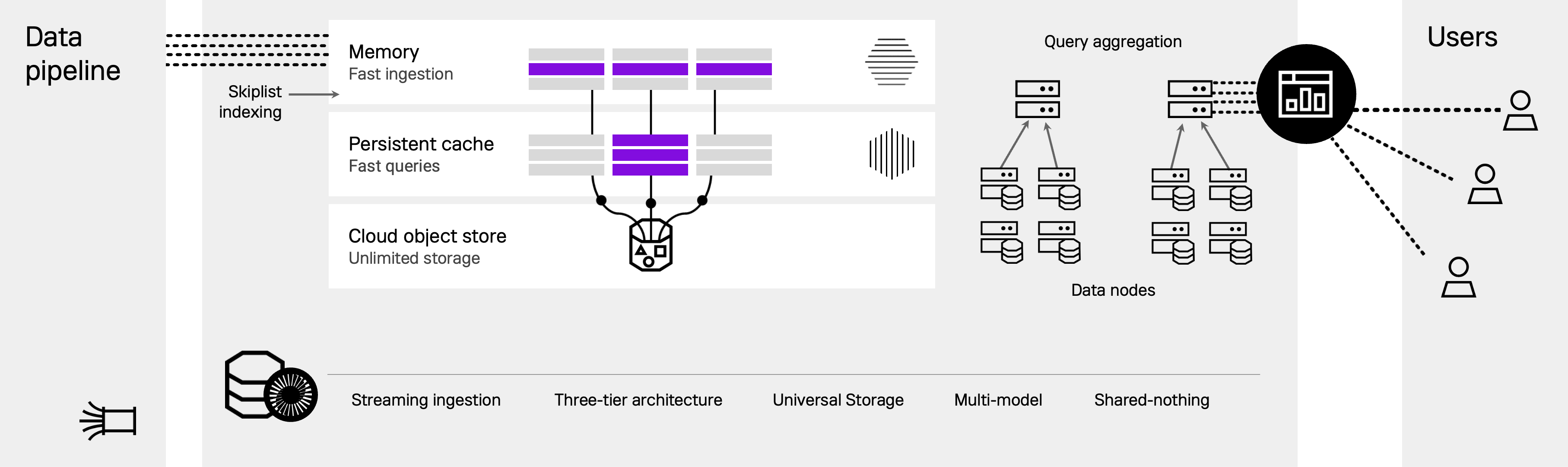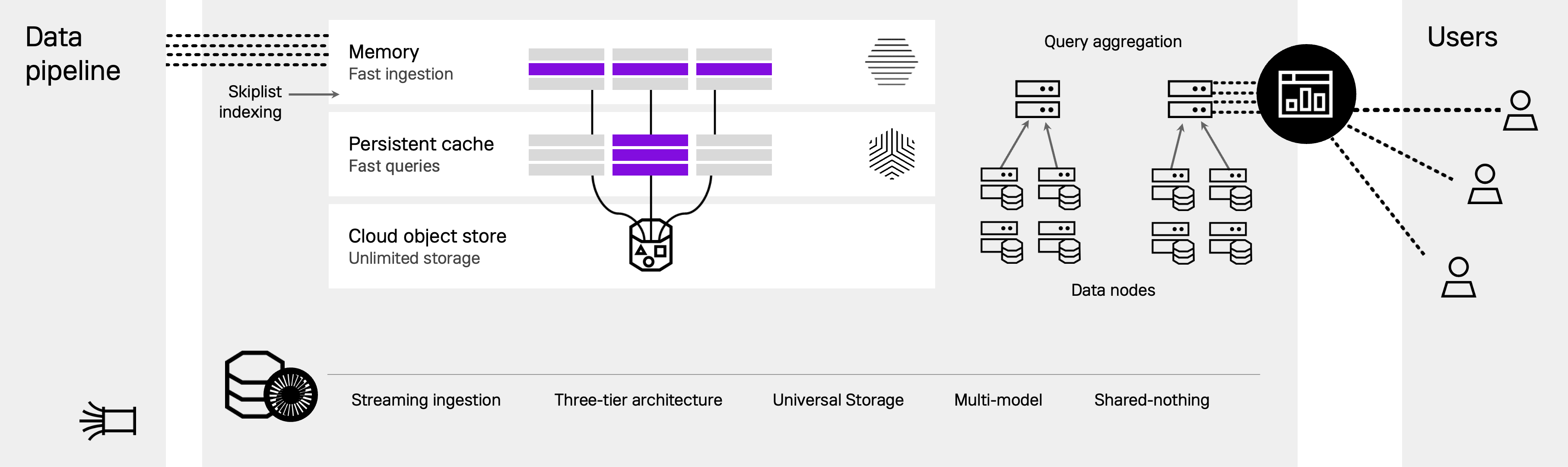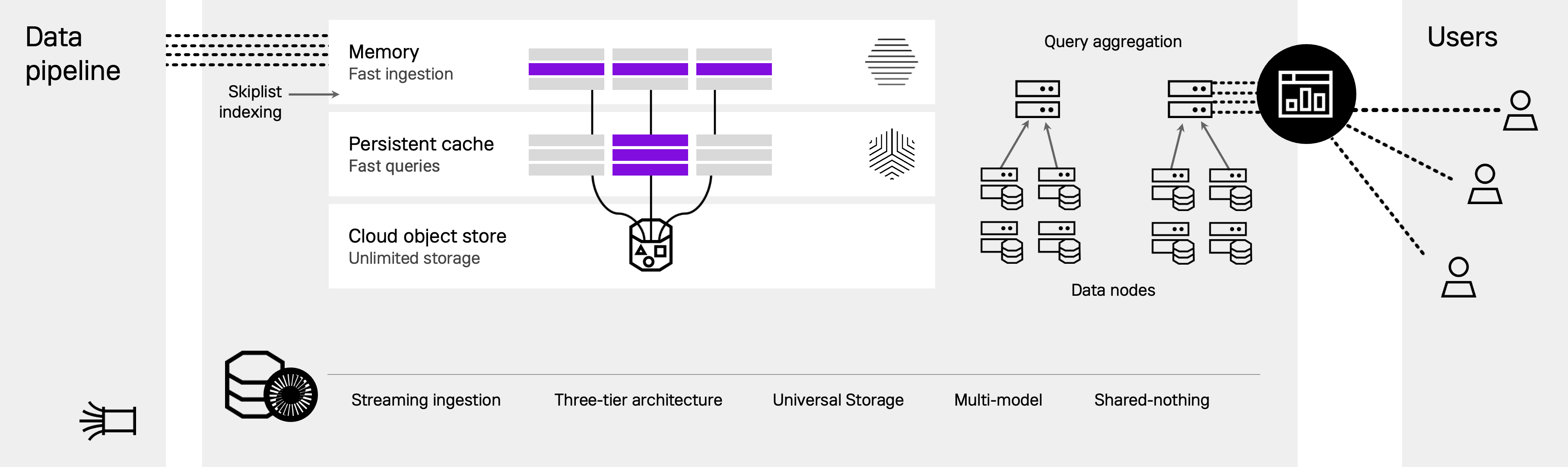
Data ingestion
Stream or bulk load data from a variety of sources. Ingested data is loaded into memory as rowstore tables.
Bottomless storage
While data is persisted to local disk, it can also spill over to object storage, allowing separation of compute and storage.
Shared-nothing
Aggregator and leaf nodes can be added for horizontal scaling and fault tolerance.
We are now all in on SingleStore Helios, which has allowed us to drop Redis, DynamoDB and MySQL, saving us an absolute fortune in monthly costs while dramatically improving performance.
Jack Ellis
Co-Founder, Fathom Analytics















Unveiling SingleStore Pro Max, the Real-Time Data Platform for Apps, Analytics and AI

Introducing SingleStore Free Shared Tier

The Ultimate Guide to the Vector Database Landscape: 2024 and Beyond
