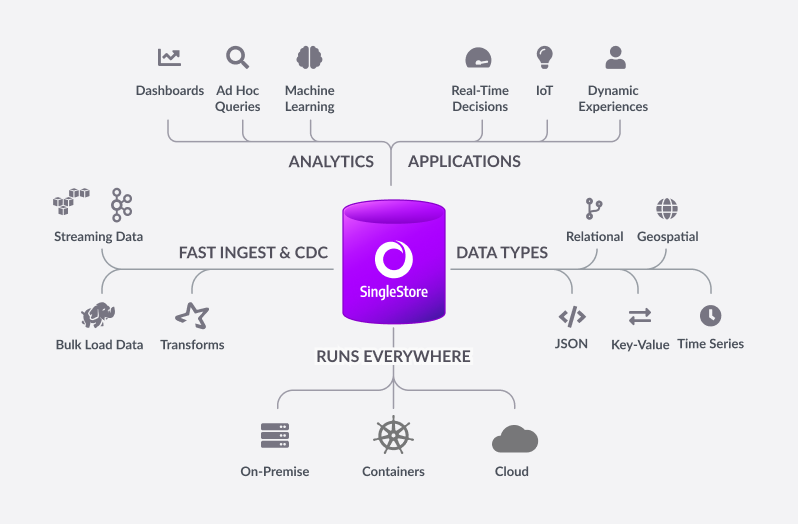
SingleStore is a distributed, relational database that handles both transactions and real-time analytics at scale. It is accessible through standard SQL drivers and supports ANSI SQL syntax including joins, filters, and analytical capabilities (e.g. aggregates, group by, and windowing functions).
SingleStore scales horizontally on cloud instances or industry-standard hardware, providing high throughput across a wide range of platforms. The SingleStore database maintains broad compatibility with common technologies in the modern data processing ecosystem (e.g. orchestration platforms, developer IDEs, and BI tools), so you can easily integrate it in your existing environment. It features an in-memory rowstore and an on-disk columnstore to handle both highly concurrent operational and analytical workloads. SingleStore also features a data ingestion technology called SingleStore Pipelines that streams large amounts of data at high throughput into the database with exactly-once semantics.