Working with Geospatial Features
On this page
SingleStore supports geospatial queries.geospatial
covers a very broad range of features.
At a basic level, geospatial support requires three things: data types, topological functions, and measurement functions.
Geospatial Types
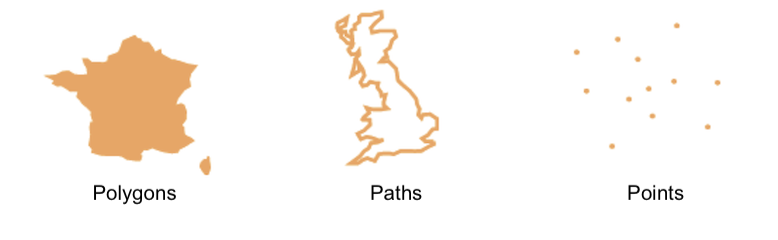
The three main geospatial object types are points, paths, and polygons.Well-Known Text
(WKT) syntax to describe them.
All geospatial functions can accept either a geospatial object or the equivalent WKT string as arguments.MULTIPOLYGON, GEOMETRY, CURVE, or other keywords.
Point
A POINT is a simple longitude / latitude pair.
"POINT(-74.044514 40.689244)"
Path or Linestring
A linestring or path object is an ordered list of points.
"LINESTRING(0 0, 0 1, 1 1)"
Polygon
A polygon is similar to a linestring, except that it is closed.
That is, it must have at least three unique points, and the first and last point-pairs must be equal:
"POLYGON((0 0, 0 1, 1 1, 0 0))"
When defining a polygon (or loop), the area inside the polygon's edges is the "smaller" portion of the globe.
You can also describe multiple shapes (or rings) inside a polygon object, i.
Each ring is represented as a set of points.
"POLYGON(Ring 0, Ring 1, ... Ring N)"
Note the parenthesis around pairs of numbers, which are separated by commas.
"POLYGON((0 0, 0 10, 10 10, 10 0, 0 0), (5 5, 6 5, 5 6, 5 5))"
In the above example, rings (0 0, 0 10, 10 10, 10 0, 0 0) and (5 5, 6 5, 5 6, 5 5) represent Ring 0 and Ring 1, respectively.
Edges
Edges in SingleStore are "spherical geodesics", i.
This can lead to unexpected results when looking for intersection, etc.
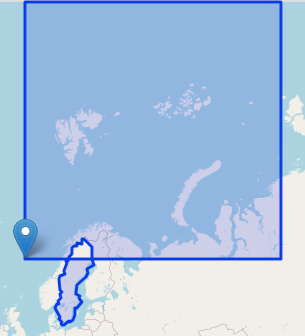
For example, in the two images below we have a polygon outlining the country of Sweden and a second polygon checking for intersection.
POLYGON ((-0.1 66.41326, 90.1 66.41326, 90.1 85.15113, -0.1 85.15113, -0.1 66.41326))
In the first image, the two polygons intersect.
In this next view, the polygons do not intersect.
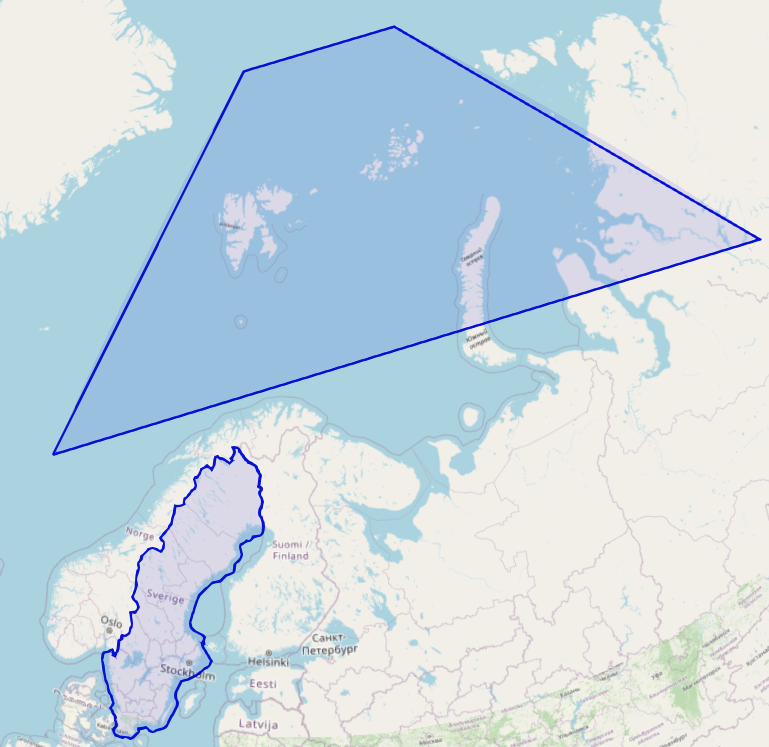
Because SingleStore uses geodesic edges, there would not be an intersection between the two polygons.
Creating a Geospatial Table
Geospatial objects are just another data type in SingleStore and can be used right alongside numbers, strings, and JSON.GeographyPoint type.Geography type.
Important
It is possible to store POINTs in the Geography type, but is not recommended.GeographyPoint type was designed specifically for point data, and is highly optimized for memory efficiency and speed.
In this example, we’ll create a table of neighborhoods.centroid
field is the point that is roughly in the middle of the borders of the neighborhood.shape
field is the polygon describing those borders.
CREATE ROWSTORE TABLE neighborhoods (id INT UNSIGNED NOT NULL PRIMARY KEY,name VARCHAR(64) NOT NULL,population INT UNSIGNED NOT NULL,shape GEOGRAPHY NOT NULL,centroid GEOGRAPHYPOINT NOT NULL,index (shape) WITH (resolution = 8),index (centroid));INSERT INTO neighborhoods VALUES(1, "Hamilton", 12346, "POLYGON((1 1,2 1,2 2, 1 2, 1 1))","POINT(1.5 1.5)"),(2, "Probability Bay", 263951, "POLYGON((5 1,6 1,6 2,5 2,5 1))", "POINT(5.5 1.5)"),(3, "Decentralized Park", 29265, "POLYGON((5 5,6 5,6 6,5 6,5 5))", "POINT(5.5 5.5)"),(4, "Axiom Township", 845696, "POLYGON((1 5,2 5,2 6,1 6,1 5))", "POINT(1.5 5.5)"),(5, "Elegant Island ", 987654, "POLYGON((3 3,4 3,4 4,3 4,3 3))", "POINT(3.5 3.5)");
Querying Geospatial Data
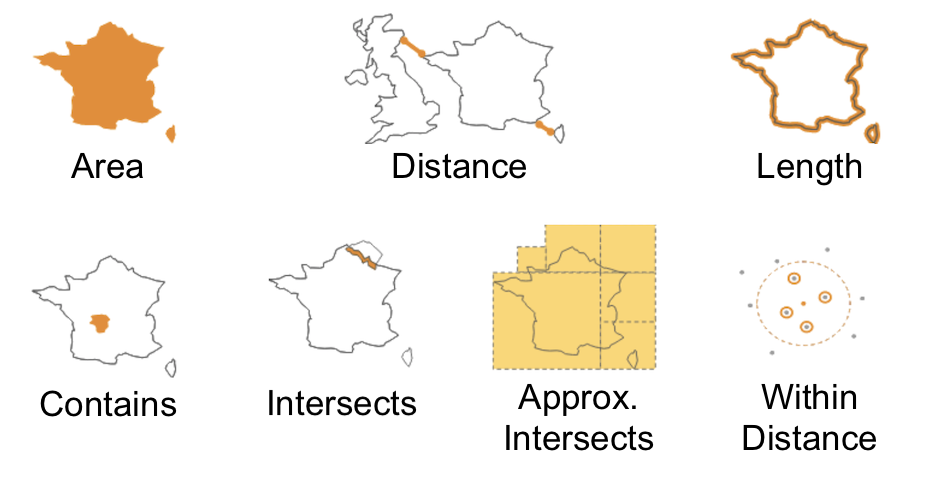
SingleStore provides a SQL function for each of these types of queries:
-
Area (GEOGRAPHY_
AREA) -
Distance (GEOGRAPHY_
DISTANCE) -
Length (GEOGRAPHY_
LENGTH) -
Contains (GEOGRAPHY_
CONTAINS) -
Intersects (GEOGRAPHY_
INTERSECTS) -
Approx.
Intersects (APPROX_ GEOGRAPHY_ INTERSECTS) -
Within Distance (GEOGRAPHY_
WITHIN_ DISTANCE)
You can run queries over the neighborhood data to see how they relate to each other spatially.
SELECT b.name AS town,ROUND(GEOGRAPHY_DISTANCE(a.centroid, b.centroid), 0) AS distance_from_center,ROUND(GEOGRAPHY_DISTANCE(a.shape, b.shape), 0) AS distance_from_borderFROM neighborhoods a, neighborhoods bWHERE a.id = 2ORDER BY 2;
+--------------------+----------------------+----------------------+
| town | distance_from_center | distance_from_border |
+--------------------+----------------------+----------------------+
| Probability Bay | 0 | 0 |
| Elegant Island | 314174 | 157090 |
| Hamilton | 444379 | 333195 |
| Decentralized Park | 444531 | 333399 |
| Axiom Township | 628012 | 471030 |
+--------------------+----------------------+----------------------+
5 rows in set (0.00 sec)Important
Distance is calculated using the standard metric for distance on a sphere.
You can also find out where you are with GEOGRAPHY_:
SELECT id, name FROM neighborhoods WHEREGEOGRAPHY_INTERSECTS("POINT(2 1)", shape);
+----+----------+
| id | name |
+----+----------+
| 1 | Hamilton |
+----+----------+
1 row in set (0.00 sec)Spatial Joins
Geospatial objects are first-class data types in SingleStore, which means that you can use spatial relationships to join tables.
Create the table:
CREATE ROWSTORE TABLE geo_businesses (id INT UNSIGNED NOT NULL PRIMARY KEY,name VARCHAR(64) NOT NULL,revenue INT UNSIGNED NOT NULL,location GEOGRAPHYPOINT NOT NULL,INDEX (location));INSERT INTO geo_businesses VALUES(1,"Touring Machines Bike Repair", 10000, "POINT(1.25 1.25)"),(2,"Manhattan Boat Club", 20000, "POINT(5.75 5.25)"),(3,"The Philospher's Diner", 12345, "POINT(1.25 5.25)"),(4,"Push & Pop Cafe", 23456, "POINT(3.25 3.75)"),(5,"Lil Mac's Subs", 76543, "POINT(5.75 5.75)"),(6,"Touring Machines Bike Repair", 21012, "POINT(5.25 1.75)"),(7,"Random Slice Pizza", 11111, "POINT(1.75 1.75)");
Find businesses contained within a specific neighborhood:
SELECT b.id, b.name FROM geo_businesses b, neighborhoods nWHERE n.name="Elegant Island" ANDGEOGRAPHY_CONTAINS(n.shape, b.location);
+----+-----------------+
| id | name |
+----+-----------------+
| 4 | Push & Pop Cafe |
+----+-----------------+SELECT b.id, b.name FROM geo_businesses b, neighborhoods nWHERE n.name="Hamilton" ANDGEOGRAPHY_CONTAINS(n.shape, b.location)ORDER BY 1;
+----+------------------------------+
| id | name |
+----+------------------------------+
| 1 | Touring Machines Bike Repair |
| 7 | Random Slice Pizza |
+----+------------------------------+These functions and many more are documented in Geospatial Functions.
Geospatial Model
SingleStore uses a spherical model similar to that used in Google Earth.
Columnstore Geospatial
In SingleStore, geospatial data and functions are supported in columnstore (i.GeographyPoint type is supported but the Geography type is not.
CREATE TABLE neighborhoods_colstore(id INT UNSIGNED NOT NULL,name VARCHAR(64) NOT NULL,population INT UNSIGNED NOT NULL,shape TEXT NOT NULL,centroid GEOGRAPHYPOINT NOT NULL,sort key (name), shard key (id));INSERT INTO neighborhoods_colstore VALUES(1, "Hamilton", 12346, "POLYGON((1 1,2 1,2 2, 1 2, 1 1))","POINT(1.5 1.5)"),(2, "Probability Bay", 263951, "POLYGON((5 1,6 1,6 2,5 2,5 1))", "POINT(5.5 1.5)"),(3, "Decentralized Park", 29265, "POLYGON((5 5,6 5,6 6,5 6,5 5))", "POINT(5.5 5.5)"),(4, "Axiom Township", 845696, "POLYGON((1 5,2 5,2 6,1 6,1 5))", "POINT(1.5 5.5)"),(5, "Elegant Island ", 987654, "POLYGON((3 3,4 3,4 4,3 4,3 3))", "POINT(3.5 3.5)");
SELECT id, name FROM neighborhoods_colstore WHEREGEOGRAPHY_INTERSECTS("POINT(2 1 )", shape);
+----+----------+
| id | name |
+----+----------+
| 1 | Hamilton |
+----+----------+Special Spatial Tuning Parameters
Spatial indices on Geography columns may be given an optional RESOLUTION parameter.
Important
These tuning parameters should only be adjusted if you have a measurable need for more performance and have worked through the tradeoffs between ingest, computational load, and memory consumption.
For example, it may be useful to compare the percentage difference in the number of rows returned by GEOGRAPHY_This difference is the
false positive" rate of the index for a given resolution.
You can also change the resolution of polygons passed into geospatial functions at query time.shape
column is unchanged, but the POLYGON in the second argument is broken into 16 parts.
SELECT *FROM neighborhoods WITH (index = shape, resolution = 16)WHERE geography_intersects(shape,"POLYGON(...)");
Using GeoJSON Data
SingleStore does not have native GeoJSON support.GEOGRAPHYPOINT type.
For example, given a set of GeoJSON points like this:
{"type": "Feature","geometry": {"type": "Point","coordinates": [123.456, 78.901]},"properties": {"id": 123456,"name": "Probability Bay Naval Observatory"}}
You can construct a table like this:
CREATE ROWSTORE TABLE geostuff (id AS dataz::properties::%id persisted BIGINT unsigned,name AS dataz::properties::$name persisted VARCHAR(128),location AS geography_point(dataz::geometry::coordinates::%`0`,dataz::geometry::coordinates::%`1`) persisted geographypoint,dataz JSON NOT NULL,index (location));
And then insert the JSON string:
INSERT INTO geostuff (dataz) VALUES('{"type": "Feature", "geometry":{"type": "Point","coordinates": [123.456, 78.901]},"properties": {"id": 123456, "name": "Probability Bay Naval Observatory" }}');
And query:
SELECT id, name, location FROM geostuff;
+--------+-----------------------------------+---------------------------------+
| id | name | location |
+--------+-----------------------------------+---------------------------------+
| 123456 | Probability Bay Naval Observatory | POINT(123.45600012 78.90100000) |
+--------+-----------------------------------+---------------------------------+Last modified: April 11, 2024