
This webinar describes the benefits and risks of moving operational databases to the cloud. It’s the first webinar in a three part series focused on migrating operational databases to the cloud. Migrating to cloud based operational data infrastructure unlocks a number of key benefits, but it’s also not without risk or complexity. The first session uncovers the motivations and benefits of moving operational data to the cloud and describe the unique challenges of migrating operational databases to the cloud. (Visit here to view all three webinars and download slides.)
About This Webinar Series
Today starts the first in a series of three webinars:
- In this webinar we’ll discuss in broad strokes, migration strategy, cloud migration, and how those strategies are influenced by larger IT transformation or digital transformation strategy.
- In our next webinar, we’ll go into the next level of details in terms of database migration best practices, where we’ll cover processes and techniques of database migration across any sort of database, really.
- In the final webinar, we’ll get specific to the technical nuts and bolts of how we do this in migrating to Singlestore Helios, which is SingleStore’s database as a service.
In this webinar, we’ll cover the journey to the cloud, a little bit about the current state of enterprise IT landscapes, and some of the challenges and business considerations that go into making a plan, making an assessment, and choosing what kind of workloads to support.
Next we’ll get into the different types of data migrations that are typically performed. And some of the questions you need to start asking if you’re at the beginning of this kind of journey. And finally, we’ll get into some specific types of workloads along the way.
Any sort of change to a functioning system can invoke fear and dread, especially when it comes to operational databases, which of course process the critical transactions for the business. After all, they’re the lifeblood of the business. And so, we’ll start to peel the onion and break that down a little bit.
If you’re just starting your journey to the cloud, you’ve probably done some experimentation, and you’ve spun up some databases of different types in some of the popular cloud vendors. And these cloud providers give guidelines oriented towards the databases and database services that they support. There’s often case studies which relate to transformations or migrations from Web 2.0 companies, companies like Netflix, who famously have moved all of their infrastructure to AWS years ago.
But in the enterprise space, there’s a different starting point. That starting point is many years, perhaps decades of lots of different heterogeneous technologies. In regards to databases themselves, a variety of different databases and versions over the years. Some that are mainframe-resident, some from the client-server era, older versions of Oracle and Microsoft SQL, IBM DB2, et cetera.
And these databases perform various workloads and may have many application dependencies on them. So, unlike those web 2.0 companies, most enterprises have to start with a really sober inventory analysis to look at what their applications are. They have to look at that application portfolio, understand the interconnections and dependencies among the systems.In the last 10 to 15 years especially, we see the uptake of new varieties of data stores, particularly NoSQL data stores such as Cassandra or key-value stores or in-memory data grids, streaming systems, and the like.
Note. See here for SingleStore’s very widely read take on NoSQL.
Introduction
In companies that have just been started in the last 15, 20 years, you could completely run that business without your own data center. And in that case, your starting point often is a SaaS application for payroll, human resources, et cetera. In addition to new custom apps that you will build, and of course, those will be on some infrastructure or platform as a service (PaaS) provider.
So some of this is intentional, and that large enterprises may want to hedge their bet across different providers. And that’s consistent with a traditional IT strategy in the pre-cloud era, where I might have an IBM Unix machine, and then an HP Unix machine, or more recently Red Hat, Linux, and Windows and applications.

But these days, it’s seen as the new platform where I want that choice is cloud platforms. Other parts of this are unintentional, like I said, with the lines of business, just adopting SaaS applications. And what you see here on the right, in the bar chart is that the hybrid cloud is growing. And to dig into that a little bit, to see just how much hybrid cloud has grown just from the year prior and 2018, it’s quite dramatic in the uptake of hybrid, and that speaks to the challenge that enterprise IT has, in that legacy systems don’t go away overnight.
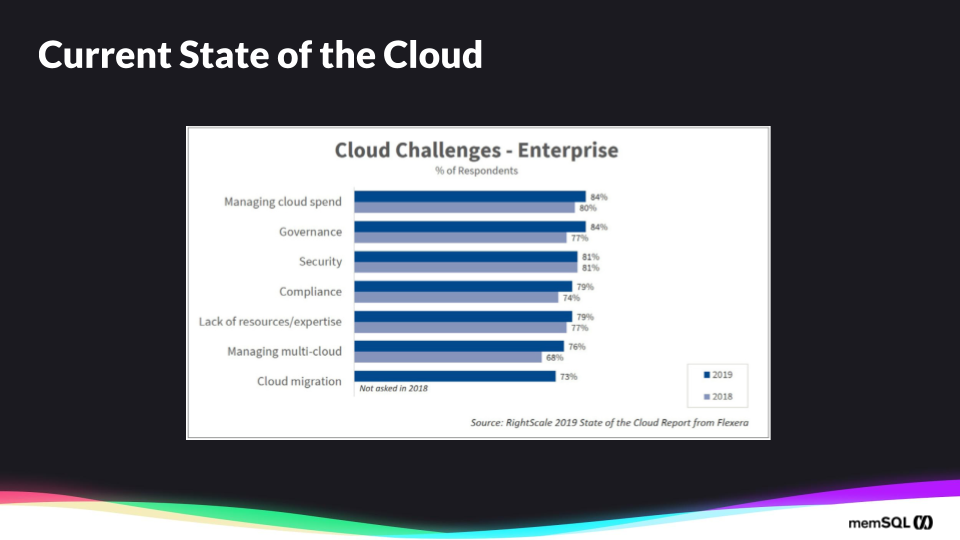
It’s not surprising that cloud spend is the first thing that sort of bites businesses. And it does have an advantage for experimentation with new applications, new go to markets, especially customer facing applications.
Because it’s so easily scalable, you may not be able to predict how popular the mobile app may be, for instance, or your API, or your real-time visualization dashboard. So putting it in an elastic environment makes sense. But the cost may explode pretty quickly as other applications get there too.

And with governance and security, I think those are obvious in that when you’re across a multi-cloud environment, you’ve got to either duplicate or integrate those security domains to ensure that you have the right control over your data and your users. There are regulatory things to be concerned about in terms of the privacy of the data, depending on the business, traffic protection of data in the U.S. and California, or in Europe with the general data protection regulation (GDPR).
We’re now at a point in the adoption of cloud, that it’s not just sort of SaaS applications and ancillary supporting services around them, but it’s also the core data itself, like the databases service, in particular relational databases. And this might be a surprise given the popularity of NoSQL in recent years, you’ll see that NoSQL databases service are growing, but to lesser extent than relational. And what’s happening across relational data warehousing or OLTP, traditional OLAP, and NoSQL databases, is that there’s been a proliferation of all of these different types. But the power of relational still is what is most useful in many applications.
Gartner’s view of this is that just in the next two years that 75% of all databases will be deployed or migrated to a cloud platform. So that’s a lot of growth. That number doesn’t necessarily mean the retirement of existing databases. I think it speaks to the growth of new databases going in the cloud, because launching those new systems is so convenient and so easy, and – for the right kinds of workload – affordable.
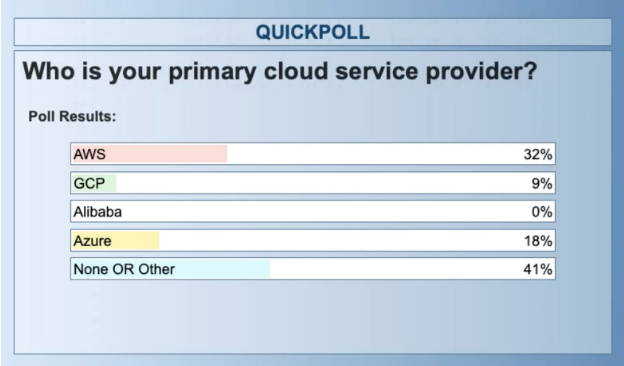
So at this point, let’s pause and let’s have a question to the audience. So, who is your primary cloud service provider? You see the popular ones listed there. You may have more than one cloud service provider. But what’s your predominant or standard one is what we’re asking here. And we’ll wait for a few moments while responses come in.
Okay, this result matches what we’ve seen from other industry reports in terms of the popularity of AWS and then second Azure. Given the time and the market, this isn’t such a surprise. In a year from now, we might see a very different mix with what’s happening with the adoption, uptake of Google and Azure in the different services. So let’s move on.
So what are the challenges of database migrations? Within enterprise IT, the first thing that needs to be done is to understand what that application dependency is.
And when it comes to a database, you need to understand particularly how the application is using the database. And so just some examples of those dependency points to look for, what are the data types that are going to be used there? Are there bar codes, integers? What’s the distribution of those stored procedures?
Although there’s a common language on families of databases, often there are nuances to how what’s available in a stored procedure in terms of processing, so the migration of stored procedures takes some effort. Most traditional SQL databases will provide user-defined functions where a user can extend functions.
And then the query language itself in terms of the data manipulation language (DML) for queries, create, update, delete, et cetera. And in terms of the definition of objects in the database, the Data Definition Language (DDL) concerning how tables are created, for instance, and the definition of triggers and stored procedures and constraints.
There’s also a hardware dependency to look at for depending on the age of the application, that software might be tied to your particular processor or machine type. And the application itself may only be available on that platform combination.
In my own experience, I’ve seen this many times in airlines where the systems for gate and boarding, systems for check in, systems for ground operations, they were written decades ago provided typically by an industry specific technology provider, and they suited the business processes of that airline for many years.
But as the airline is looking to do more customer experience interactions and collect data about the customer’s experience from existing touch points like the check-in touch point, the kiosk, the mobile app, but they want to enhance this data. And they want to bring operational data, typically a lot of these operational data systems in logistics and create providers and airlines and other types of operations manufacturing, they don’t lend themselves well to do this.
So migrating these applications can be more difficult. Often it’s going to be Agra modernization where you’re just moving off of that platform. Initially, you would integrate with these, and you may store the data that you event out in your targets, new database in the cloud. And finally, there is often a management mismatch of the application. In other words, the configuration of that application as database doesn’t quite fit the infrastructure model of the cloud model that you’re migrating to.
The assets aren’t easily divided parametrized and put into your DevOps process and your CI/CD pipeline. Often it’s not easy to containerize. So these are some of the challenges that make it more difficult in enterprise IT context to migrate the applications which of course drag along the databases for these applications.
Charlie Feld, a visionary in the area of IT transformation, has his Twelve Timeless Principles:
- No Blind Spot
- Outcomes: Business, Architecture, Productivity
- Zoom Out
- Progressive Elaboration & Decomposition
- Systems Thinking
- The WHO is Where All the Leverage Is
- 30 Game Changers
- Functional Excellence is Table Stakes
- Think Capabilities
- Architecture Matters
- Constant Modernization
- Beachhead First, Then Accelerate
So let’s talk about the phases of migration. So we’ll go into this more in the second webinar, where we talk about best practices, but I’ll summarize them here.

Assessing applications and workloads for cloud readiness allows organizations to:
- Determine what applications and data can – and cannot – be readily moved to a cloud environment
- What delivery models (public, private, or hybrid) can be supported
- Which applications you do not want to move to cloud
You’ve got to classify these different workloads. So you can look at them in terms of what’s more amenable to the move? How many concurrent users do I expect? Where are they geographically distributed? Can I replicate data across more easily in the cloud to provide that service or without interrupting that service?

Do I have new applications and transactions coming online? Perhaps there are more, there are new sensors in IoT, sensors that I need to now bring that data to these applications. So you need to categorize these workloads in terms of the data size, the data frequency, the shape and structure of the data, and look at what kind of compute resources you’re going to need, because it’s going to be a little bit different. Of course, this will require some testing by workload.
So at this point, I’d like to pause and ask Alicia have another polling question. So what types of workloads have you migrated to the cloud so far? Given the statistics we see from the surveys, most likely, most of you have done some sort of migration or you’re aware of one in your business and what you’ve done. And you might be embarking on new types of applications in terms of streaming IoT.
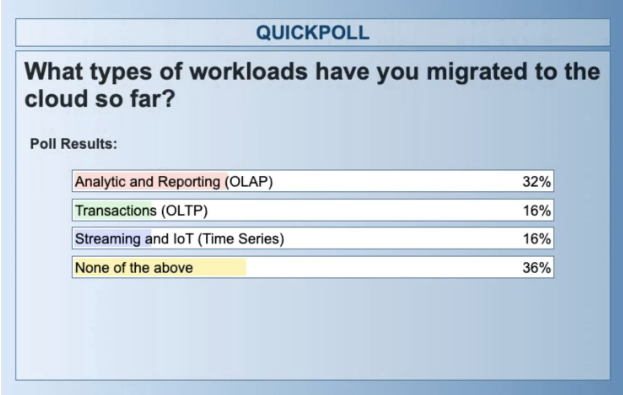
So roughly a third have not been involved in migration so far. And another third, it’s been analytics and reporting. That result on analytic and reporting, I think is insightful, because when you think about the risks and rewards of migrating workloads, the offline historical reporting infrastructure is the least risky.
If you have a business scenario where you’re providing weekly operational reports on revenue or customer churn or marketing effectiveness, and those reports don’t get reviewed perhaps until Monday morning, then you can do the weekly reporting generation over the weekend. If it takes two hours or 10 hours to process the data, it’s not such a big deal. Nobody’s going to look at it until Monday.
So there’s a broader array of sort of fallbacks and safety measures. And it’s less time-critical. Those are sort of the easier ones. So 16% of you reported that transactional or operational databases you’re aware of, or you’ve been involved in moving this to the cloud. And that is really what’s happening right now, that we find at SingleStore as well, is that the first wave was this wave of analytical applications, and now recently, you see more of the operational transactions, which is the core part of the business.
Here are criteria to choose the right workloads for data migration:
- Complexity of the application
- Impact to the business
- Transactional and application dependencies
- Benefits of ending support for legacy applications
- Presence or absence of sensitive data content
- Likelihood of taking advantage of the cloud’s elasticity
What are the most suitable candidates for cloud migration? Here are a few keys:
- Applications and databases which already need to be modernized, enhanced, or improved to support new requirements or increased demands
- Consider apps having highly variable throughput
- Apps used by a broad base of consumers, where you do not know how many users will connect and when
- Apps that require rapid scaling of resources
- Development, testing and prototyping of application changes

Q&A and Conclusion
How do I migrate from Oracle to SingleStore?
Well, we’ve done this for several customers. And we have a white paper available online that goes into quite a lot of detail on how to approach that, and have a plan for an Oracle to SingleStore migration.
What makes SingleStore good for time series?
That’s a whole subject in itself. We’ve got webinars and blog articles available on that. But essentially, I’ll give a few of them here and that SingleStore allows you to first of all ingest that data without blocking for writes; you can do that in parallel often. So if you’re reading from Kafka, for instance, which itself is deployed with multiple brokers and multiple partitions, SingleStore is a distributed database, and you can ingest that time series data in real time and in parallel. So that’s the first point is ingestion.
Secondly, we provide time series-specific functions to query that data that allows it for easy convenience, so it’s not necessary to go to a separate, distinct, unique database. Again, SingleStore is a unified converged database that handles relational, analytical, key-value, document, time series, geospatial all in one place. And so it’s suitable to the new cloud native era, where you’re going to have these different data types and access patterns.
What is the difference between SingleStore and Amazon Aurora?
Yeah, so that question is probably coming because when you’re migrating to a cloud database, typically you’re looking at one of the major cloud providers, AWS or Google Cloud Platform or Microsoft Azure. And each of these providers provides various types of databases.
Amazon Aurora is a database built on Postgres, and there’s a version also for MySQL, or at least compatibility in that way that allows you to do that. So it’s worth a look. But what you’ll find when you’re doing sort of high-performance application is that the system architecture of Aurora itself is the biggest Achilles’ heel there, which is it’s composed of the single-node databases of MySQL or Postgres, depending on the edition you’ve chosen, and it’s basically sharding that across multiple instances and providing a shard and middleware layer above that.
And that has inefficiencies. It’s going to utilize more cloud resources. And in the beginning that might – at small volumes, that might not manifest into a problem. But when you’re doing this at scale across many applications, and on a bigger basis, those compute resources really add up in terms of the cost.
So SingleStore is a much more efficient way, because it was written from the ground up, it’s not built out of some other single-node, traditional SQL database like Aurora. SingleStore’s built from the storage layer all the way up to take advantage of current cloud hardware as well as modern hardware in terms of AVX2 instruction sets and SIMD and, if that’s available, non volatile memory.
Secondly, I’d say that Aurora differs in a major way and that it’s oriented to just the transactions, OLTP type processing. Whereas SingleStore does that, but not just that it also has a rowstore with a columnstore, which is what our traditional analytical database like Amazon Redshift has. So, in a way, you could say that with Amazon, you would need two databases to do what SingleStore can do with a single database.
We invite you to learn more about SingleStore at singlestore.com or get started with your trial of Singlestore Helios.





