
Apache Kafka is widely used to transmit and store messages between applications. Kafka is fast and scalable, like SingleStore. SingleStore and Kafka work well together. You can find out more, and see a demo, in our recent webinar.
In the webinar, Senior Sales Engineer Neil Dahlke of SingleStore explains how Apache Kafka and SingleStore can be used together to help reduce latency. Latency has three main causes:
- Slow data loading – due to database single-node architectures and locking mechanisms, it can take many minutes – even hours – to load datasets into the system. Kafka and SingleStore both address this problem.
- Lengthy query execution – as data sets grow to millions and even billions of rows, queries take a lot of time to construct, optimize, and run. SingleStore executes queries quickly.
- Limited user access – single-node databases can only handle a small number of users at a time. SingleStore is distributed and has high concurrency, allowing many more active users and apps to run against your database.
The solutions to performance problems often involve expense, complexity, and workarounds:
- Scaling up. Adding more CPUs, adding more memory, adding caching tiers, buying specialized hardware racks, or paying for expensive add-on options to existing databases.
- NoSQL solutions. An object store can improve the problem of slow data loading, but at a big cost on the back (analytics) end: slow analytics, developer-intensive queries, and loss of compatibility with business intelligence tools.
These solutions can generate more problems – additional layers, components to manage, and tough trade-offs – all at additional cost.
SingleStore addresses all these problems. As the name implies, SingleStore was first introduced as an in-memory database. Today, it flexibly uses memory and disk for optimal performance. SingleStore is also referred to as a NewSQL database, or modern database, because it offers a familiar SQL interface along with distributed capabilities for fast ingest and high concurrency, and other desirable features.
SingleStore is fast for loading; fast for queries; and scales for access by large numbers of concurrent users. And that comes with a familiar interface: the secret sauce of SingleStore is that it offers distributed SQL for both transactions and analytics.

The ability of SingleStore to run combined operations quickly makes it perfect for what are called “translytical” applications, combining a steady diet of transactions with robust performance for always-on analytics against current, not stale, data. Put another way, SingleStore gives you HOAP: hybrid operational and analytical processing. (View our webinar on HOAP databases and data management.)
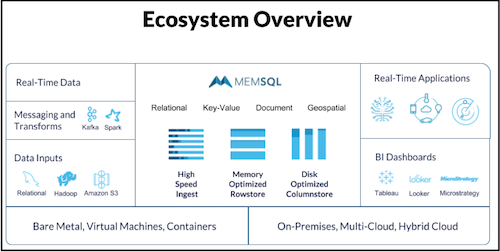
SingleStore plays nice with all the elements of your existing ecosystem: it runs on-premise on bare metal; is cloud native for public, private, and hybrid clouds; and runs well in virtual machines and containers. SingleStore takes in real-time data and data from messaging and transform components, such as Kafka (the topic of this webinar) or Spark. And it can take in data from other data stores, such as relational databases, HDFS, or Amazon S3.
You can then access your data from your own business intelligence dashboards, such as Looker, Microstrategy, and Tableau, and many other applications.
In the webinar, you’ll see a demo of a SingleStore data ingestion tool called CREATE PIPELINE. With a pipeline, you can do fast, reliable stream ingestion or batch loading. CREATE PIPELINE supports arbitrary transformations and works with any computer language, with the Go language and Python being popular with users.
SingleStore can work across multiple Kafka brokers. A second demo in the webinar shows SingleStore tied to Kafka inputs to do sentiment analysis on tweets in a basketball-related Twitter feed.
The webinar ends with a Q&A, covering topics such as the need for star schemas, the ability to ingest data from Oracle directly, and how to support high availability on AWS.
Webinar Recording and Slides
You can easily access the webinar recording and slides to learn more about SingleStore.
Free Trial
We also offer a free trial of SingleStore for 30 days. Download the free trial today.





