
SingleStore product marketing leader Mike Boyarski led the webinar, describing how SingleStore is well-positioned to power operational analytics. Operational analytics is the ongoing use of live and historical data to drive decision-making by both people and programs, including predictive analytics, machine learning, and AI. To do operational analytics you need to quickly ingest, analyze, and act on both incoming and existing data – all of which is in the wheelhouse of SingleStore. To view the webinar, click here.
Traditionally, companies have their most important operational data stuck in silos. They can’t access it quickly or easily, and they can’t meet service level agreements (SLAs) for data delivery and data access.
To solve these problems, businesses that need to move fast use SingleStore. This includes half of the top 19 banks, two of the top three telcos, tech leaders – from Akamai to Uber – and many others.

Why Operational Analytics is Vital
The demands that organizations make on their data are growing. Data volume and complexity are rising; business expectations are growing, and analytics are evolving to keep pace. Whereas reports and occasional queries from experts were once considered enough, today, businesses want to use real-time data to power predictive analytics, machine learning, and AI.
Today’s systems either struggle to keep up, or don’t even try. Their responsiveness from event to insight may not meet SLAs – and often, the SLAs themselves are not enough to keep pace with new competitors. Costs and complexity continue to increase, and demands for access – from people with SQL queries, from SQL-compatible business intelligence (BI) programs, from management dashboards, and from programs that power predictive analytics, machine learning, and AI, are all rising. These requirements are now table stakes for organizations to be competitive, as digital native companies win more and more slices of the economic pie.
In order to power analytics, organizations need to ingest, analyze, and act on blended real-time and historical data. SingleStore’s capabilities make it capable of meeting this challenge, where legacy databases fall short.
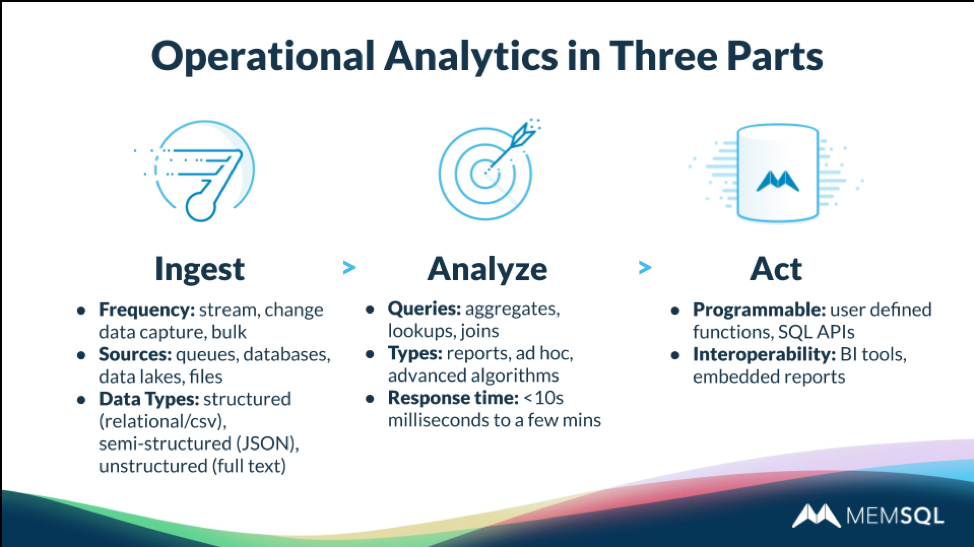
A New Architecture – with SingleStore at the Core
SingleStore has the relational database capabilities needed to handle structured data for both transactions and analytics, the scalability to grow to meet demand for ingest, analysis, concurrency, and action, and the flexibility to handle semi-structured JSON data and full-text search for unstructured data. SingleStore also runs on-premises and in multiple clouds, in containers and virtual machines, and with a new Kubernetes Operator for open source or Red Hat Open Shift Kubernetes distributions, making for a truly cloud-native option that lives where you need it to.
SingleStore can ingest from a wide range of sources, including change data capture (CDC), at very high rates of speed; works with relational data, key-value data, JSON semi-structured data, geospatial data, and time series data.
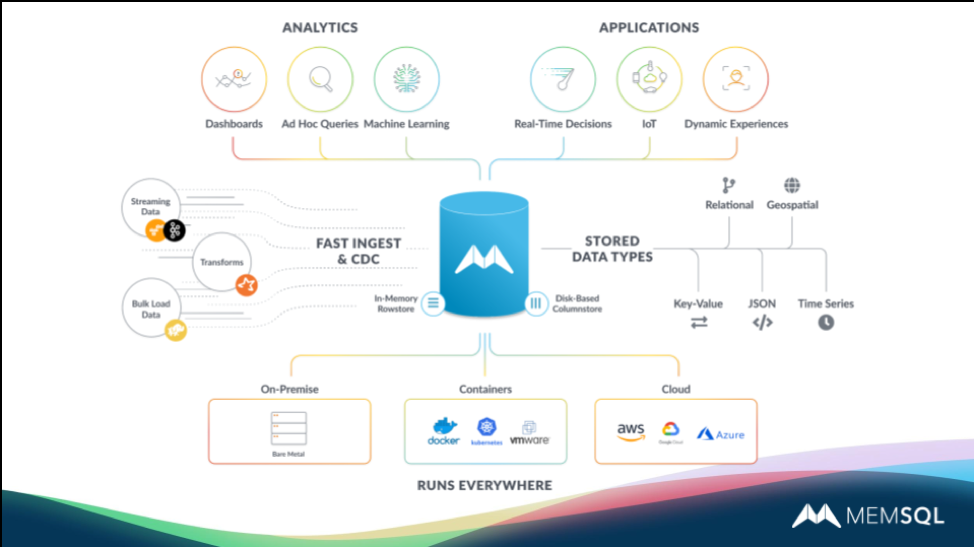
SingleStore handles data from systems of engagement (SOEs), such as social media, internet of things (IoT) data, and mobile phone data, including the full range of supported formats,with excellent performance. On the other side of the data store, analytics demands include lookups, aggregates, ad hoc queries, machine learning (ML), and artificial intelligence (AI). This wide range of demands, including many more users wanting direct query access, drives a strong need for increased concurrency.
SingleStore can live right at the core of a modern data infrastructure, handling both transactions and analytics. You can augment existing systems or replace them at each stage of your infrastructure.
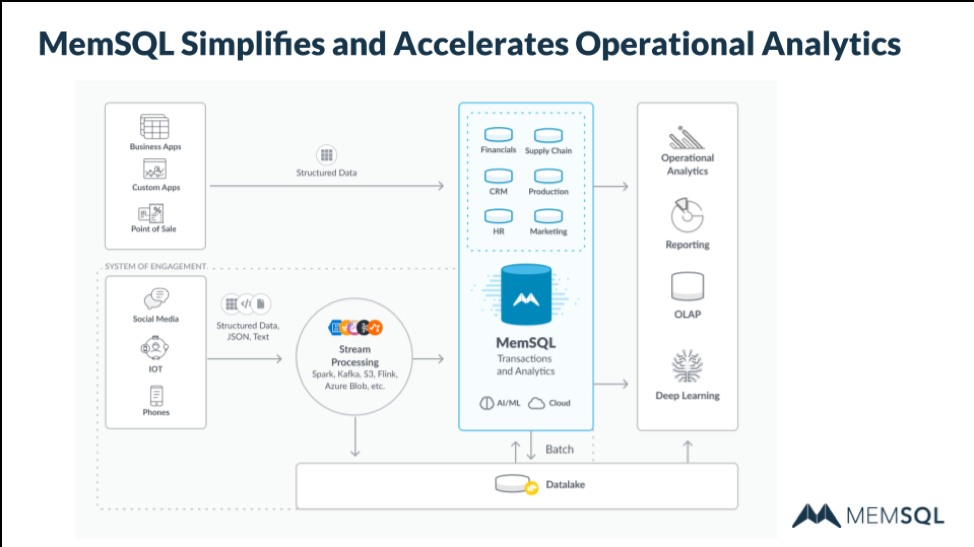
SingleStore Meets Operational Requirements
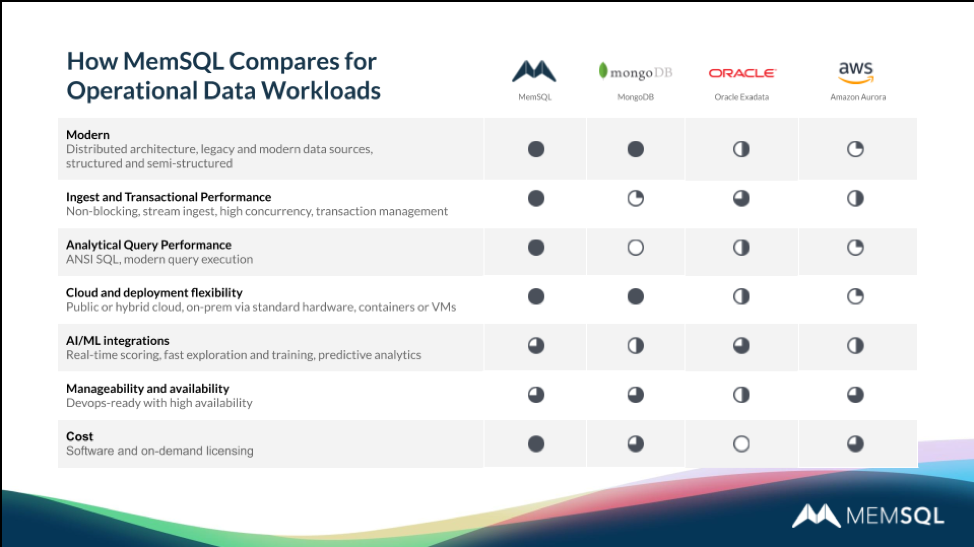
Companies from Comcast and Uber find SingleStore vital to meeting their operational analytics requirements. SingleStore excels vs. competitors in meeting the needs of operational data workloads. The leading operational analytics competitors include:
- MongoDB. Mongo is fully modern in its structure, and flexible in its deployment options. But performance for ingest, transactions, and analytics fall far behind SingleStore, and even lag other competitors.
- Oracle Exadata. Oracle’s Exadata database machine is legacy, rather than modern; inflexible; hard to manage and keep available; and very expensive.
- Amazon Aurora. Aurora is not modern, making it hard to match SingleStore or competitors in key areas of performance and flexibility.
Q&A
Mike took questions from the audience, including:
Q. How do you write custom code to apply to ingested data?
A. You can create stored procedures to use all kinds of code as part of the SingleStore Pipelines feature, Pipelines to stored procedures.
Q. Are you an in-memory database?
A. SingleStore started out as an in-memory database, using rowstore only. We’ve now added a robust columnstore capability that is used by many of our customers. Though columnstore is disk-based, many customers have been pleasantly surprised by its performance and functionality.
Q. Do you support time series data?
A. SingleStore has strong support for many time series capabilities. However, SingleStore does not have all of the functionality of a specialized time series database out of the box. We are doing work internally on this, and a number of SingleStore customers are using us for time series data today. Please contact us to find out how we handle time series workloads.
Q. Can SingleStore be deployed on AWS, GCP, and Azure?
A. Yes! We have customers on each of these platforms. Also, SingleStore’s Kubernetes Operator makes it easy to manage SingleStore on these platforms, as well as on-premises.
Q. Has SingleStore been used to replace Exadata? What about Oracle’s version of SQL?
A. Yes, a number of well-known customers have made this move. We give you all the performance you need on a modern infrastructure, at a much lower TCO – often 3x or less than Oracle. For Oracle’s PLSQL, we have a migration path and partners to help move up to thousands of stored procedures to SingleStore’s own language. (Which includes many PLSQL-friendly features.)
Conclusion
To learn more about SingleStore and how it can help you deliver operational analytics, view the recorded webinar. You can also get started with SingleStore for free today.





