
More and more, SingleStore is used to help add streaming characteristics to existing systems, and to build new systems that feature streaming data from end to end. Our new ebook excerpt from O’Reilly introduces the basics of streaming systems. You can then read on – in the full ebook and here on the SingleStore blog – to learn about how you can make streaming part of all your projects, existing and new.
Streaming has been largely defined by three technologies – one that’s old, one that’s newer, and one that’s out-and-out new. Streaming Systems covers the waterfront thoroughly.
Originally, Tyler Akidau, one of the book’s authors, wrote two very popular blog posts: Streaming 101: The World Beyond Batch, and Streaming 102, both on the O’Reilly site. The popularity of the blog posts led to the popular O’Reilly book, Streaming Systems: The What, Where, When, and How of Large-Scale Data Processing.
In the excerpt that we offer here, you will see a solid definition of streaming and how it works with different kinds of data. The authors address the role of streaming in the entire data processing lifecycle with admirable thoroughness.
They also describe the major concerns you’ll face when working with streaming data. One of these is the difference between the order in which data is received and the order in which processing on it is completed. Reducing such disparities as much as possible is a major topic in streaming systems.
In both the excerpt, and the full ebook, the authors also tackle three key streaming technologies that continue to play key roles in the evolution of SingleStore: Apache Kafka, Apache Spark, and – perhaps surprisingly, in this context – SQL.
Apache Kafka and Streaming
Apache Kafka saw its 1.0 version introduced by Confluent in late 2017. (See Apache Kafka 1.0 Introduced Exactly Once at The New Stack.) SingleStore works extremely well with Kafka. Both Kafka and SingleStore are unusual in supporting exactly-once updates, a key feature that not only adds valuable capabilities, but affects how you think about data movement within your organization.
It’s very easy to connect Kafka streams to SingleStore Pipelines for rapid ingest. And SingleStore’s Pipelines to stored procedures feature lets you handle complex transformations without interfering with the streaming process.
Apache Spark and Streaming
Apache Spark is an older streaming solution, initially released in 2014. (One of the key components included in the 1.0 release was Spark SQL, for ingesting structured data into Spark.) Spark was first developed to address concerns with Google’s MapReduce data processing approach. While widely used, Spark is perhaps as well known today for its machine learning and AI capabilities as for its core streaming functionality.
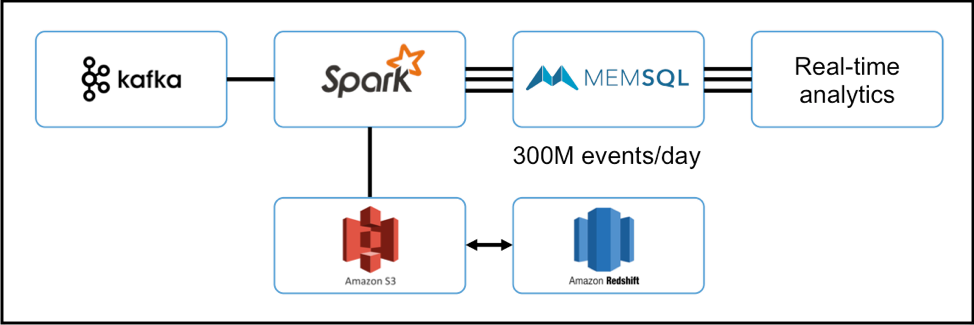
SingleStore first introduced the SingleStore Spark Connector in 2015, then included full Spark support in SingleStore Pipelines and Pipelines to stored procedures. Today, Spark and SingleStore work very well together. SingleStore customer Teespring used Kafka and Spark together for machine learning implementations.
SQL and Streaming
Ironically, one of the foundational data technologies, SQL, plays a big role in Streaming Systems, and in the future of streaming. SQL is all over the full book’s Table of Contents:
- Streaming SQL is Chapter 8 of the full ebook. In this chapter, the authors discuss how to use SQL robustly in a streaming environment.
- Streaming Joins is Chapter 9. Joins are foundational to analytics, and optimizing them has been the topic of decades of work in the SQL community. Yet joins are often neglected in the NoSQL movement that is most closely associated with streaming. Streaming Systems shows how to use joins in a streaming environment.
SingleStore is, of course, a leading database in the NewSQL movement. NewSQL databases combine the best of traditional relational databases – transactions, structured data, and SQL support – with the best of NoSQL: scalability, speed, and flexibility.
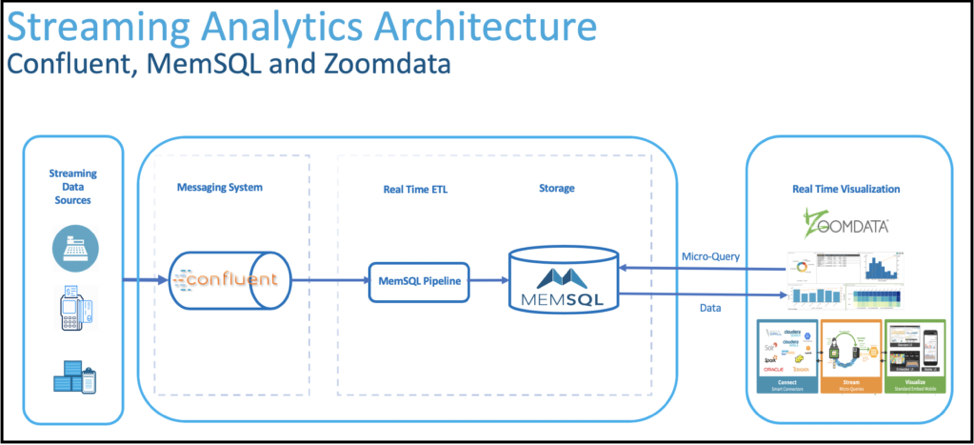
Saeed Barghi of SingleStore partner Zoomdata shows Kafka and SingleStore used together for business intelligence.
Next Steps to Streaming
We recommend that you download and read our book excerpt from Streaming Systems today. If you find it especially valuable, consider getting the full ebook from O’Reilly.
If you wish to move to implementation, you can start with SingleStore today for free. Or, contact us to speak with a technical professional who can describe how SingleStore can help you achieve your goals.




