Today we launched SingleStoreDB Self-Managed 5.5 featuring SingleStore Pipelines, a new way to achieve maximum performance for real-time data ingestion at scale. This implementation enables exactly-once semantics when streaming from message brokers such as Apache Kafka.
An end-to-end real-time analytics data platform requires real-time analytical queries and real-time ingestion. However, it is rare to find a data platform that satisfies both of these requirements. With the launch of SingleStore Pipelines as a native feature of our database, we now deliver an end-to-end solution from real-time ingest to analytics.
Real-Time Analytical Queries and Data Ingestion
Let’s define real-time analytical queries and real-time data ingestion separately.
A data platform that supports real-time analytical queries quickly returns results for sophisticated analytical queries, which are usually written in SQL with lots of complex JOINs. Execution of real-time analytical queries differentiates SingleStore from competitors. In the past year, Gartner Research recognized SingleStore as the number one operational data warehouse, as well as awarded Visionary placements to the company Operational Database and Data Warehouse Magic Quadrants.
A data platform that supports real-time ingestion can instantly store streaming data from sources like web traffic, sensors on machines, or edge devices. SingleStore Pipelines ingests data at scale in three steps. First, performantly pulling from data sources – Extract. Second, mapping and enriching the data – Transform. Finally, loading the data into SingleStore – Load. This all occurs within one database, or pipeline. The transactional nature of Pipelines sets it apart from other solutions. Streaming data is atomically committed in SingleStore, and exactly-once semantics are ensured by storing metadata about each pipeline in the database.
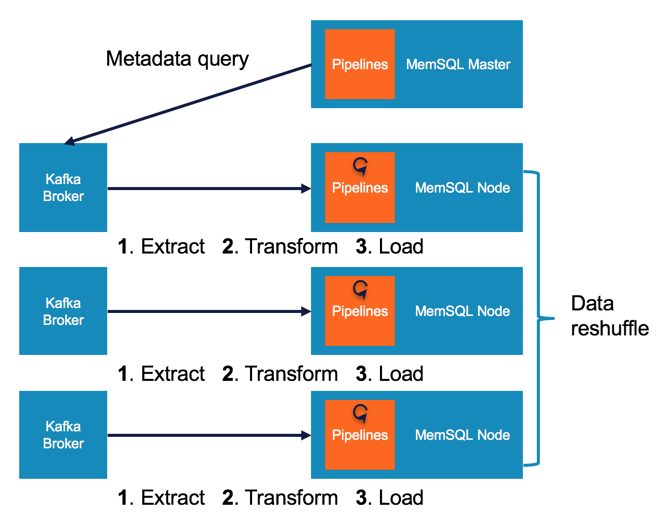
At the crux of SingleStore Pipelines is a new, unique database object to SingleStore – a PIPELINE, or a top-level database element similar to a TABLE, INDEX or VIEW. Let’s explore the different properties of SingleStore Pipelines.
Pipelines allow extraction from data sources (e.g. Apache Kafka) using a robust, database-native mechanism.
The system that pulls data from data sources IS the SingleStore Database. Other solutions that claim to pull streaming data typically leverage separate “middleware” solutions to extract data. That not only decreases performance, it also requires additional provisioning and management.
SingleStore ensures true exactly-once semantics for Kafka messages.
SingleStore stores and manages Kafka offsets within the SingleStore Database. The latest loaded Kafka offsets are stored in SingleStore; only when a Kafka message is reliably extracted, transformed, and loaded in SingleStore are the offsets incremented. In the event of any error, such as Kafka connectivity, improper transforms, or malformed data, SingleStore always ensures that each Kafka message is processed exactly once.
Data enrichment and transformation in Pipelines can be implemented using any programming language.
SingleStore Pipelines introduces the concept of a “transform” specified as part of the Pipeline DDL. Transforms are user-defined scripts that enrich and map external data for loading into SingleStore, written in any programming language for familiarity and flexibility.
Data loading into SingleStore happens efficiently and in parallel between SingleStore data partitions and Kafka brokers.
SingleStore is a distributed system, and SingleStore Pipelines was implemented with this attribute in mind. Pipelines loads data between distributed systems and streams data in parallel from individual Kafka brokers directly into SingleStore data partitions. Moreover, SingleStore performs distributed data loading optimizations such as lessening the total number of threads used, sharing data buffers, and minimizing intra-cluster connections.
Learn more about SingleStore Pipelines in our technical documentation.
Try SingleStore Pipelines Today
Build your own pipeline today: Download SingleStoreDB Self-Managed 5.5