
Digital advertising is a numbers game played out over billions of interactions. Advertisers and publishers build predictive models for buying and selling traffic, then apply those models over and over again. Even small changes to a model, changes that alter conversion rates by fractions of a percent, can have a profound impact on revenue over the course of a billion transactions.
Serving targeted ads requires a database of users segmented by interests and demographic information. Granular segmentation allows for more effective targeting. For example, you can choose more relevant ads if you have a list of users who like rock and roll, jazz, and classical music than if you just have a generic list of music fans.
Knowing the overlap between multiple user segments opens up new opportunities for targeting. For example, knowing that a user is both a fan of classical music and lives in the San Francisco Bay Area allows you to display an ad for tickets to the San Francisco Symphony. This ad will not be relevant to the vast majority of your audience, but may convert at a high rate for this particular “composite” segment. Similarly, you can offer LA Philharmonic tickets to classical fans in Southern California, Outside Lands tickets to rock and roll fans in the Bay Area, and so on.
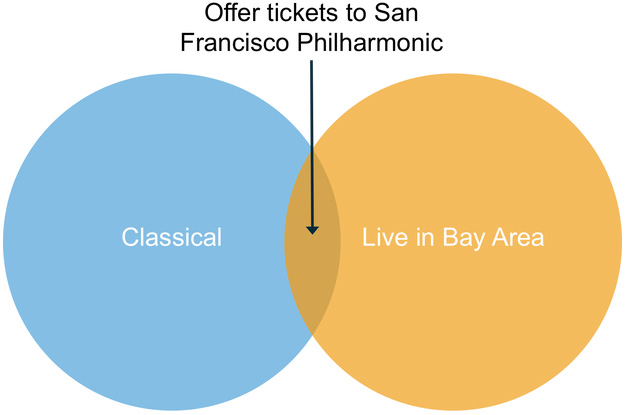
Until recently, technical challenges made overlap targeting difficult. Legacy OLTP databases, the original backend for ad exchanges, could not deliver the analytic query performance to do overlap analysis in real time. On the other hand, precomputing segment overlap requires storing inordinately many segment combinations (e.g. classical and SF, rock and SF, jazz and SF, … , classical and LA, rock and LA, …), and the amount of computation and storage grows even faster as you begin combining more segment types.
SingleStore enables a simpler approach by converging real-time data ingest and segment analysis in a single database. This post explains how to use SingleStore to build a system that computes audience segment overlap in real time.
Size and shape of the data
Suppose there are 2 billion users (all the users on the internet), and those users can be members of any number of 100 thousand defined categories, or “segments.” Clicks are recorded as triples: (user_id, segment_id, timestamp). We use the following DDL for the table definition:
CREATE TABLE user_groups
(
user_id BIGINT,
segment_id INT,
ts TIMESTAMP,
shard key(user_id),
key segment (segment_id) using clustered columnstore
)
Note that this data is not unique – different users and groups can occur multiple times.
Now suppose we collect around 100 billion records (clicks) every month. Computing unions and intersections over two or more segments in subsecond time, while constantly loading new data, was not feasible with legacy technology.
SingleStore offers a column store index to allow efficient storage and scanning for large tables. SingleStore column store tables persist to disk in a highly compressed format. Those 200 billion click records consume less than one TB of compressed data.
Data loading and maintaining the sort order
100 billion records a month works out to around 3 billion records a day. In order to deliver this level of ingest, SingleStore introduced an open source tool called SingleStore Loader that enables bulk data loading at high speeds from AWS, S3, HDFS or a local file system. As data is loaded, SingleStore sorts and merges the new data with existing data in the background. Instead of maintaining a perfect sort order, which is very expensive, SingleStore keeps the data set “almost sorted” as described in this documentation page. Maintaining some degree of sort order during data load is key to delivering sub-second query performance for unions and intersections.
Data loading is fully transactional and doesn’t disrupt concurrent queries. You don’t need to “vacuum” data like in a legacy data warehouse. SingleStore sorts data automatically and you can monitor progress using SHOW COLUMNAR MERGE STATUS command.
Finding and targeting composite segments
With all user data in a single table, SQL makes it easy to slice and dice to analyze the relationship between user segments.
The following query computes group union of segment 1 (s1) and segment 2 (s2):
SELECT
distinct segment_id
FROM
user_groups
WHERE
segment_id in (s1, s2)
There are a number of ways to compute segment intersections. While you may intuitively jump to writing the query as a self join, it can actually be written more simply with clever use of built-in functions. The following query computes the intersection of s1 and s2 (i.e. all users in both s1 AND s2):
SELECT
user_id,
(max(segment_id = s2) and max(segment_id = s1)) both_segments
FROM
user_groups
WHERE
segment_id IN(s1, s2)
GROUP BY
user_id
HAVING
both_segments = true
In this query, the expression (max(segment_id = s2) and max(segment_id = s1)) tests whether a given user, identified by user_id, falls under both segment s1 and segment s2. segment_id = s2 returns 1 (true) when segment_id matches s2 and 0 (false) otherwise. max(segment_id = s2) in the projection of the query returns 1 if any segment_id matches s2 and returns 0 otherwise. The expression as a whole is summarized as the variable both_segments, as in: “this user_id falls under both segments.”
With minor tweaks, you can use queries like this one to answer other segment overlap questions. For example, you can find all the users in s1 but not s2 using the following query:
SELECT
user_id,
(max(segment_id = s1) and min(segment_id != s2)) s1_only
FROM
user_groups
WHERE
segment_id IN(s1, s2)
GROUP BY
user_id
HAVING
s1_only = true
Similar to both_segments in the previous query, the expression (max(segment_id = s1) and min(segment_id != s2)) returns 1 (true) only if there is some user_id uid such that the table user_segments some record (uid, s1, …) but zero records matching (uid, s2, …).
Sub-second query performance
The SingleStore query optimizer understands that, since the dataset is sharded by user_id, it can push down the computation of distinct user_ids to each individual partition and then just sum up the results.
Further, each partition is sorted on segment_id, which allows SingleStore to skip over the majority of the data without having to actually read it. Only the parts of the table relevant to the query need to be decompressed and used. Due to this efficient scanning, each partition processes hundreds of thousands of records in parallel, which is why SingleStore can compute overlap queries in under a second.
Data retention
By its nature, ad targeting data becomes less relevant as it ages. Data retention is achieved by simply running a delete query.
DELETE
from
user_groups
where
ts < date_sub(now(), interval 2 month);
After the statement is issued, SingleStore compacts column segments in the background. Delete operations don’t disrupt the ongoing queries. This allows you to keep your ad platform online and running queries on fresh data 24 x 7.
Hardware footprint
The workload described can be achieved on just three nodes: one aggregator and two leaves, all of them Amazon cr3x.large instances. Due to the high compression of sorted lists of integers, 700GB of SSD per node is enough to store 200 billion data points.
Go deeper with your audience
Combining and intersecting user segments allows advertisers to better understand their audience using only pre-collected data. Conventional database technology limitations have complicated this type of analysis in the past. However, SingleStore makes computing composite segments simple in both concept and execution.
These techniques apply outside of digital advertising as well. Any business problem that requires analyzing potentially overlapping categories can benefit from this big data Venn diagram. With SingleStore, you can produce composite segments on live data using only SQL.
Want to build your own overlap targeting platform? Download SingleStore today.




