
This blog post shares the second part of our recent webinar, Singlestore Helios and SingleStoreDB Self-Managed 7.0 Overview. (Part 1 is here.) In this part, Rick delivers a deep dive into Singlestore Helios, the new, elastic, on-demand cloud service from SingleStore. He describes the features of Singlestore Helios in depth, and delivers a demo. In the last part, Rick describes highlights of the upcoming SingleStoreDB Self-Managed 7.0.
Singlestore Helios is our fully managed on-demand elastic version of SingleStore. Up to now, you could only download SingleStoreDB Self-Managed and run it yourself. Now, with Singlestore Helios, SingleStore will now take care of things like provisioning, deployment, upgrades, and management alerting, and all of that can be offloaded from you to the SingleStore team.

And you’re responsible for the logical management of the data. Meaning, creating your database, writing your queries, tuning your queries, creating your indexes, creating and granting permissions for users. So you handle all of the logical aspects that are more around what you need in order to build your application and you leave the management of the system to SingleStore, allowing you to be more free and move faster.
This gives you effortless deployment. You can spin up a cluster in just a couple of minutes, and you get elastic scale, able to grow and shrink the cluster as your requirements demand. You get a much superior total cost of ownership (TCO), particularly versus legacy databases. The cost of SingleStore, especially the cost per query in SingleStore, is far more efficient in terms of how you use its hardware. And the fact that it runs on commodity hardware makes it much more cost efficient than the databases you’ve typically been using.

And we’re multi-cloud and hybrid cloud. Meaning, you can run us, of course, on-premises using SingleStoreDB Self-Managed or you can run us in any cloud. Today we support AWS and GCP for Singlestore Helios, with Azure coming early next year. And of course, all of this leads to better agility for you. Making it faster and easier for you to build your applications and get up and running as quickly as possible, getting that superior scale and performance.
Now, how do we do it? It turns out that it was much easier than we expected, actually. When we started building Singlestore Helios, we looked around at different technologies that can help us do the orchestration of spinning up the cluster and all those deployments and upgrades and pieces. And we settled on using Kubernetes. Now, there was some trepidation around whether Kubernetes was ready for a stateful service like a distributed database, because it had been primarily used for non-stateful application level systems. But we found that there had been enough investment by the community that it worked quite well for us – and in fact, a couple of people, over about six months, were able to get the system up and running quite easily.

Kubernetes has capabilities like auto-healing if there’s a node failure. So if the node fails in the system, it automatically spins up a VM, brings it into the cluster, attaches to the cluster and gets it up and running. It allows us to do auto-scaling, easily growing the cluster as needed, and things like rolling upgrades to make sure that we can upgrade the software without having any impact on the end user.
We use containers to actually pin your compute, so your cores and memory are dedicated to you via containers running on the host machines and we use block storage in the background. So, for example, on AWS, we use the elastic block store for the storage, which then we can easily detach and attach to the containers as needed.
When it comes to things like the instance type and the node configuration, all that’s handled by SingleStore. We look at your workload and pick the optimal configuration that works best for you and you don’t have to worry about it. It’s all transparent. As well as delivering high availability (HA) transparently. So we always keep two copies of the data within the cluster. If there’s any problem with a node or if there’s any failures, it will automatically failover to the other copy, and then either fix the node or grow a new one, so that you get back to having two copies safely. And all this happens without any interruption, invisible to the user.
And of course, security is top of mind for many people as they come to cloud, and there are all these typical security options enabled by default. So you get encryption on the wire and on disk, and we support the authentication mechanisms that people expect. And full support for a role-based access control as well.
But enough talk; let me show you how it works. So this is our customer portal. When you signup for an account, this is what you’ll see. You click on this Clusters link on the left-hand outside, and from here you can create a cluster. So I’m going to say, Create cluster. I’m going to give it a name, Demo2. I can choose a cluster type. In this case, I’m going to choose development but this helps you keep track, which clusters are staging your production development systems. We support four regions today with more coming in the near future. So GCP Virginia, AWS Virginia, AWS Oregon and GCP Mumbai.
(For the demo, see the recorded webinar, Singlestore Helios and SingleStoreDB Self-Managed 7.0 Overview. For an animation, see our Singlestore Helios page. Example screenshots are shown here. To try SingleStore Studio, including the built-in demo described here, download SingleStore for free. – Ed)
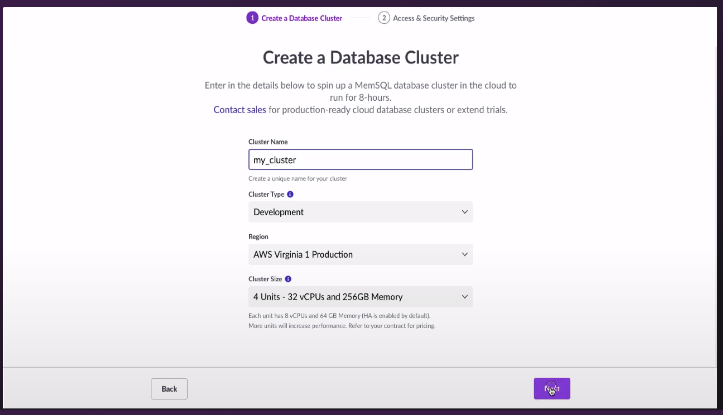
I’m going to choose AWS Virginia. I can choose the number of units. So I can choose four units. Unit is the amount of capacity that you specify for the size of the cluster. And again, whatever you choose, you can always change it later. But I’m going to choose a four-unit cluster, which gives me 32 vCPUs, 256 gigs of RAM, and 4 terabytes across the cluster total. Click Next. I put in my password, and then you can specify, within this an IP range, in order to lock the system down, so it’s only accessible by the machines you want to be accessible to. In my case, I’m just going to allow access from anywhere, because this is a demo. Then it’s Create cluster.
So really, with just a handful of clicks, and a few minutes work, I’ve now spun up a four-node cluster within SingleStore. Now, it’ll take a handful of minutes to spin up, so while we’re waiting for that to spin up, I’ve got another cluster over here that I’m going to use to show you a little bit more about what it looks like. So what you’ll see is the cluster properties. So this information is the region and the size and the information about when it was created and what version I’m on. I can change the password over here, or edit the IP addresses that can connect to it. And then I’m given the endpoints here, that let me connect in order to run commands from your application.
Now, you can either use obviously a SQL driver, a MySQL or ADB driver, to connect from your application, or you can also use Studio. And Studio is our tool for monitoring and managing SingleStore. So I’m going to click this link here to load data with SingleStore studio, and put in my password. Now, I’m in Studio, which gives me overall dashboard that tells me the number of nodes that I have, gives me some information about database usage and gives me a number of options here on the left.
One of the things we introduced recently was a tutorial to help people understand how to make use of SingleStore. So I’m going to walk you through the first couple steps to that tutorial. Let’s say the first thing I want to do is I want to run the tutorial and I’m going to load some sample data. So I click this link here to load sample data. I’m going to load the sample stock data set and so the first thing you have to do before you load a new data, of course, is you have to create a database, which means you have to come up with the schema, what are the tables I want, what are the columns I want.
And so I’m going to click paste queries here and this jumps me down to the SQL editor, which allows me to create and edit queries and run them and what we see is it’s creating a database called Trades and it creates a table called Trade with a number of different columns here. The first one being a columnstore table, and another table called Company that’s a rowstore table. So I’m just going to run that. If we go over to the databases link here, you can see that there’s a new database called Trades, and it’s got two tables. One that’s a rowstore and one a columnstore.
Now, you’ll notice these tables are empty that’s because we haven’t put any data in them. So the next thing we’re going to do is we’re going to load some data. I’m going to paste the load data thing. Now, what this is doing is using that feature I mentioned earlier, SingleStore Pipelines. And the Pipelines feature, what it does is it lets you create an object in the system that will load data from some source location. As I mentioned, it supports both Kafka as well as Linux file systems, and the cloud vendor blob storage. In this case, we’re using AWS, so we’re going to load the data from S3. And it’s as simple as saying Create Pipeline, give it a name, load data from S3, and then you give it a bucket and then a bit of configuration and away you go.
So now the data started loading and of course, if you want to see the pipeline in action, you can click the pipeline’s UI down here. You can see that the pipeline is already finished. So now if I go back to the databases and to this Trades database and I refresh my screen, you can see that there have been over 3,000 rows now loaded into the company table. And so if I want to, in fact, I can go down here and I can see that there are, in fact, 3,288 rows loaded in the table. If I want to get some idea of what they are, I can do a simple query that gets me the first 10 rows of the table. And I can investigate and kind of see what the data is from here.
Now I’m going to stop here, even though there’s a lot more to this tutorial, just in the interest of time. But you’ll see at the end, you can actually run this tutorial yourself and actually go through all the way. We’ll generate more data and actually have you run queries over millions of rows to show you the power of SingleStore, but this gives you an idea of how easy and simply you can now get up and running with loading data and getting the value of SingleStore as quickly as possible.
So next let’s talk about pricing. So how much does it cost? The way we do pricing, it’s very similar to Amazon. If you’re familiar with Amazon or any of the big cloud vendors, we have two billing models. We have both an on-demand model, where you pay for what you use on an hour-to-hour basis, and then that hourly usage is added up and billed to you monthly. So basically the number of units is the way you buy capacity. A unit is 8 vCPU and 64 gigs of RAM and one terabyte of storage. You specify how many units you want per cluster that you spin up. We add up all those units, times the price per unit, and then that’s your bill at the end of the month.

Now if you’re running clusters 24/7 and you know you’re not going to be spinning them up and down, then you can get a discount by paying upfront for the usage for either a one-year or a three-year term. You see the pricing here for Reserved as well. And you can mix the reserved and on-demand pricing – again, similar to what you can do with the existing cloud vendors. Keep in mind please that this pricing is actually the North Virginia pricing and that pricing does vary by region and by cloud provider. And if you want more details on the pricing for other regions or the cloud providers, you can contact our Sales team.
And last, let’s finish up with how does SingleStore compare with the other players in the market. So if you look at the other operational database players, one, you can see the SingleStore as a modern highly available architecture compared to the legacy architectures from some of the other players out there. SingleStore does very well. It’s really top in its class when it comes to performance, both how fast we bring data in, how fast you run queries, and the kind of concurrency you can scale. Doing much better than NoSQL systems like MongoDB or single-box systems like Amazon Aurora.

And even Oracle Cloud systems, where they have scalable systems, but the price-performance ratio is not very good, where it costs a lot to get the scale you need. And particularly, in analytical query performance, SingleStore shines and really shows up better than any of the other competitors, particularly the single-box systems like Amazon Aurora, that will tap out once it hits the largest box size you can get. But of course, the fact that we can deploy both on-prem and in the cloud, and on any cloud that you want, gives you the flexibility that almost none of the legacy players have.
It’s certainly not the big cloud providers like Amazon who will only run their stuff in Amazon and you can’t run it anywhere else. And then, as people move into the higher level of maturity, AI and ML integrations are a key important feature, and SingleStore shines there as well. So that finishes up the discussion around Singlestore Helios.





