
What makes SingleStore unique? Its ability to combine the scalability of NoSQL databases and the familiar structure, transaction capabilities, and SQL support of traditional relational databases. SingleStore does all this while offering high performance on ingest, fast query response, and high concurrency – support for many active users at the same time.
Because of its SQLs support, SingleStore is “plug and play” with existing database systems and with all the people and tools that are part of the SQL ecosystem. The combination of capabilities that are offered in SingleStore are not found together anywhere else.
In this blog post we show the underlying features of SingleStore that allow it to offer all of these capabilities at the same time. After you read this blog post, you will be able to assess SingleStore as a solution for your own database-related issues.
Introduction to SingleStore
SingleStore describes its database software as the No-Limits Database™ because it’s able to scale massively. SingleStore is a distributed data store that allows for no limits in terms of the number of concurrent queries you have on the environment. SingleStore can handle transactions and analytics, simultaneously, all in one system.
Ultimately what you get with SingleStore is a distributed datastore with relational SQL that gives you a lot of the efficiencies that distributed systems provide, all running on commodity standard hardware, as with NoSQL databases. But with SingleStore, you also get the SQL structure that so many organizations depend on.

The architecture of SingleStore has many similarities to existing NoSQL databases, while also having a relational database structure and SQL support, among other important differences:
- Scale-out architecture. True distributed processing across arbitrary numbers of servers, easily scaling CPU capacity, RAM, and disk storage.
- The ability to run on commodity hardware and in the cloud. For SingleStore, any machine or cloud instance that can run Linux can run SingleStore.
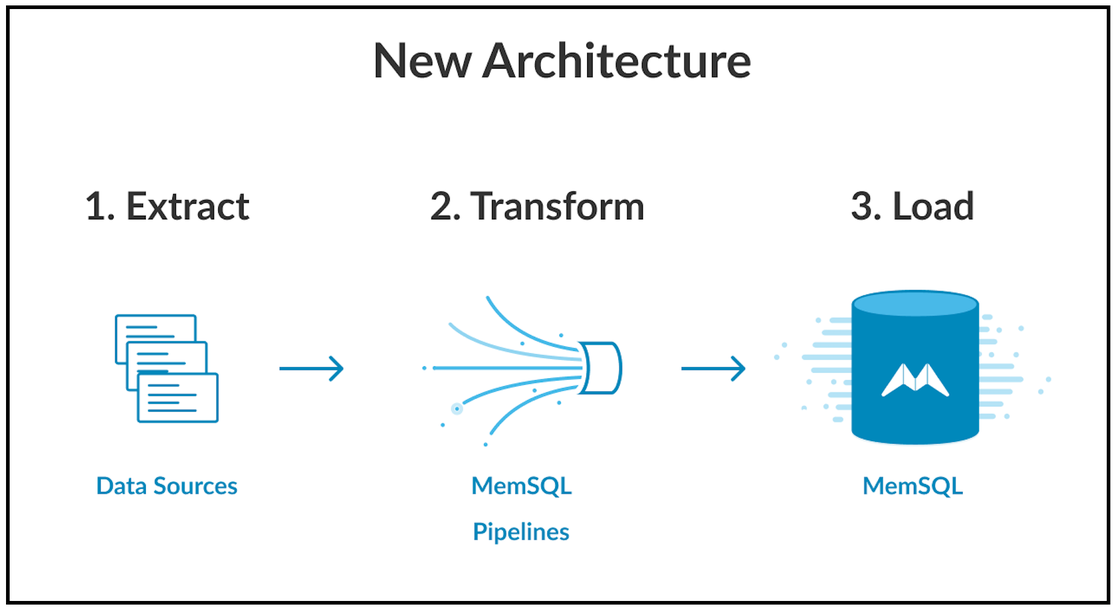
- High-speed ingest. For a typical NoSQL database, ingest is only in batch mode, whereas ingest with SingleStore can handle both batch and streaming data and in-line data transformations via SingleStore Pipelines.
- Flexible data formats. SingleStore supports structured, relational data that fully supports SQL queries, as well as semi-structured data such as JSON, AVRO, text, and spatial data; NoSQL databases can also handle unstructured data.
- Tiered storage. Most NoSQL databases are disk-first, with some support for in-memory operations. SingleStore includes both and allows you to flexibly manage memory vs. disk usage.
SingleStore, Feature by Feature
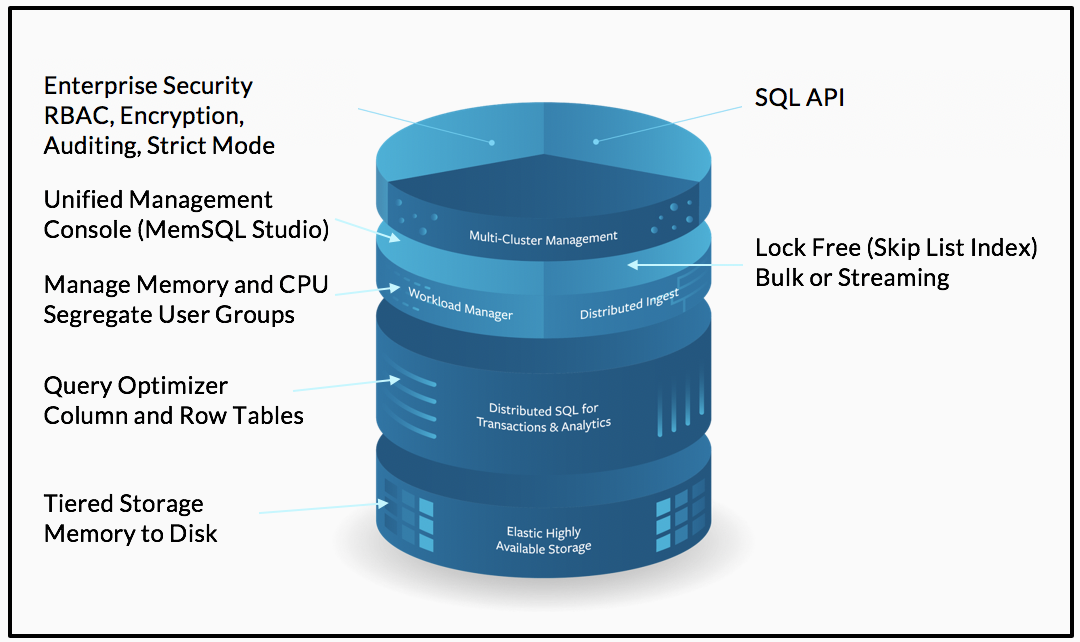
SingleStore’s unique architecture allows it to offer a combination of capabilities that isn’t available elsewhere. Here’s a quick summary:
- Tiered storage across memory and disk. Each uses a separate table type.
- A query optimizer that works across table types.
- A memory and CPU manager with the ability to segregate user groups.
- Distributed ingest which is lock-free across reads and writes, for bulk and streaming ingest, using a skiplist index.
- A management console with a GUI (SingleStore Studio) and command-line tools.
- Multi-cluster management.
- Enterprise security with RBAC, encryption, auditing, and strict mode to isolate data from administrators.
- A SQL API.
Following are highlights of these capabilities.
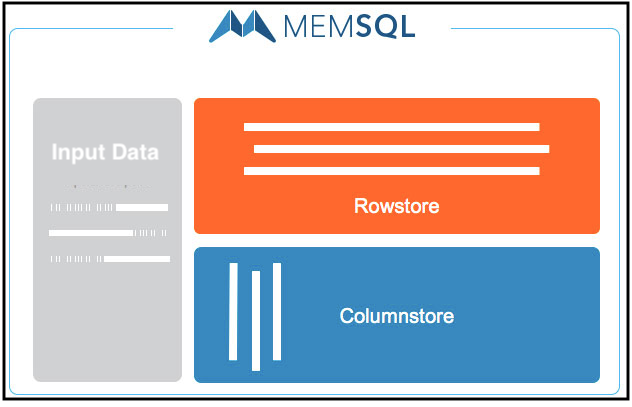
Tiered Storage, Memory to Disk
SingleStore takes advantage of tiered storage, which means it can spill data to memory and/or to disk. So you can have the choice of taking advantage of SingleStore’s memory-optimized rowstore tables for very fast, efficient query processing or ingestion.
However, SingleStore also runs queries on disk, using columnstore tables. For both table types, everything is distributed – so SingleStore is highly elastic, and allows for scale-out processing of that data.
Query Optimizer across Rowstore and Columnstore Tables
SingleStore has a SQL query optimizer that runs on the two different table types, row-based and column-based. This gives you the ability to do transactional processing, analytic processing, or both at the same time, using the best table structure for each workload.
Workload Management for CPU and RAM
On top of the query optimizer, SingleStore has a memory and CPU management governor. Part of that is a workload manager. It allows you to identify how to segment processes or users so that ultimately your query processing can prevent outages.
If you’re going to run out of memory, for example, SingleStore can help ensure that that doesn’t happen. Or you can segment users so that you can have one class of user or application get a certain amount of resources. It’s a very sophisticated workload manager that lets you get the best out of the system.
Distributed Ingest, Bulk or Streaming, Lock-free
SingleStore offers a lock-free architecture. This is based on the skiplist index, which does a very efficient job of doing transactions and updates without necessarily locking or blocking other reads and/or writes. That allows SingleStore to deliver bulk and/or streaming ingestion.
So transactional support on SingleStore is similar to any NoSQL system, in that both SingleStore and a NoSQL system can do continuous loading. The difference is that SingleStore is ACID compliant. SingleStore carries every transaction all the way to the disk, so there’s no risk of data loss. SingleStore has a classic logging mechanism, so we can do HA configurations and replication of transactions to other nodes or clusters to ensure availability.
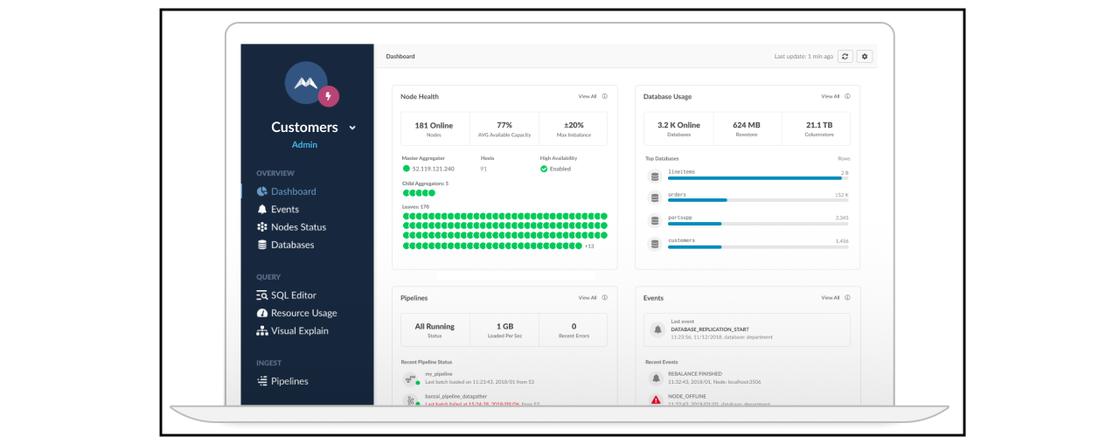
Multi-Cluster Management
We have a full management console called SingleStore Studio. It’s a GUI-based environment. We also have command-line utilities that gives you functions that can deploy, manage, repartition, rebalance nodes, all sort of built into the system.
The Studio product and command-line tools make it very easy to identify exactly where bottlenecks are. You can do things like query planning analysis, where you can inspect where query bottlenecks might be and troubleshoot those. All through a built-in, web-based monitoring environment.
Enterprise Security with RBAC, Encryption, Auditing, and Strict Mode
SingleStore is very stringent in its support for security. As a company, we have a number of financial services and public sector customers that require the highest levels of security. So SingleStore security includes role-based access control (RBAC), encryption, and support for auditing.
We have another component, called “strict mode”, which imposes a separation of concerns model. So your administrators cannot have visibility to data, but they can help administer the environment.
SQL API and Queries
Lastly, what you get with SingleStore is a SQL API. Other distributed databases, forthrightly called NoSQL databases, lack this essential component. (As well as several of the other features listed above.) The SingleStore database is relational SQL through and through.
SingleStore’s table structures are all in relational format. That is ultimately what gives you that easy to work with data set that a lot of data analysts and folks in the business community enjoy.
The SingleStore Ecosystem
This is a summary of the SingleStore ecosystem in terms of the type of ingestion mechanisms that SingleStore supports, notably including Kafka and Spark streaming.
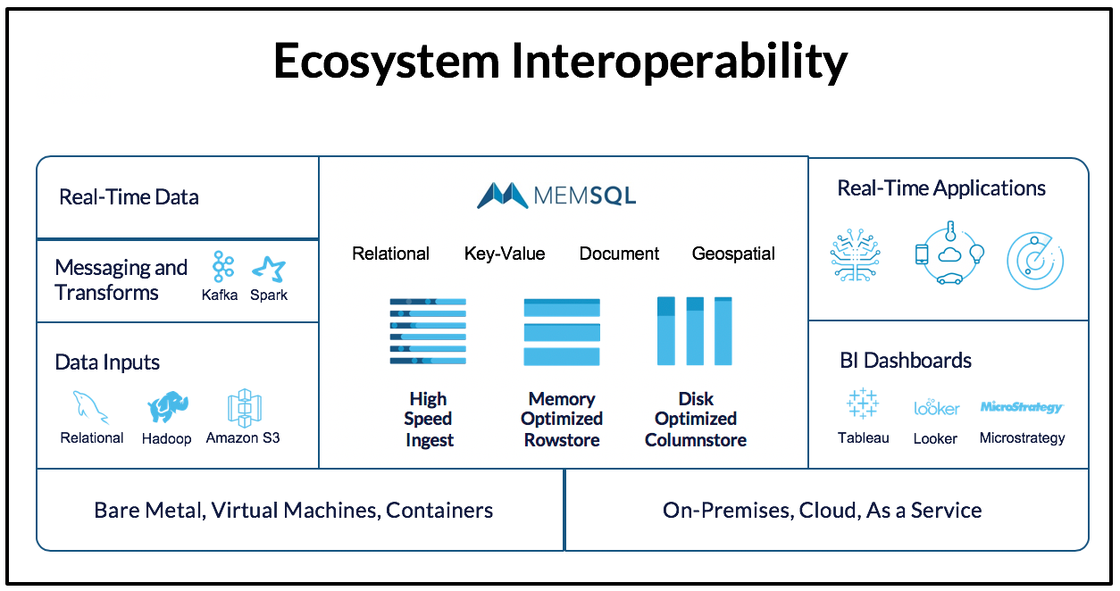
SingleStore supports an HDFS Pipeline connector. We have SingleStore Pipelines that allow you to essentially ingest data as data lands in the source system. Pipelines to Stored Procedures give Pipelines even more power. So the notion of continuous loading from a relational database, a Hadoop cluster, an Amazon S3 database or other sources is supported by SingleStore’s architecture.
In the diagram, you can see that we have the two different table types, rowstore and columnstore. Lastly, you can connect a number of off-the-shelf business intelligence (BI) tools, such as Tableau or Looker, to build your dashboards and reports.
SingleStore runs on any Linux-based system, whether that’s on-premises or AWS, Azure, or Google’s cloud service. You can run anywhere that there’s a Linux-based environment.
Conclusion
You can see a version of this blog post as a presentation within the recent webinar, Hadoop Acceleration Strategies for Broader Use and Simplicity, led by Mike Boyarski. To learn more, click here to view the webinar and download the slides.





