
Waiting sucks, as I’m sure you’d agree, and when it comes to analytics, the gravity of increasing data volumes has become a primary concern for both industry and IT professionals. In order to deal with the volume and velocity of disparate data types, organizations have had to take an “assembly line”-like approach that requires significant batch processing.
These factories are cobbled together using different software packages to ETL and transform data, which unfortunately creates systemic reporting delays. Real-time operational requirements cannot be serviced by processes built to support all time historical volumes.
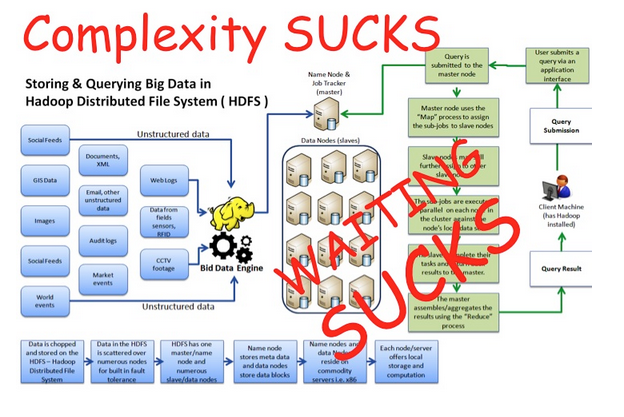
This “supply chain management” approach of data transforms and batch processing has become too unwieldy and, as can be seen below, requires complex architectures and programming languages to facilitate.
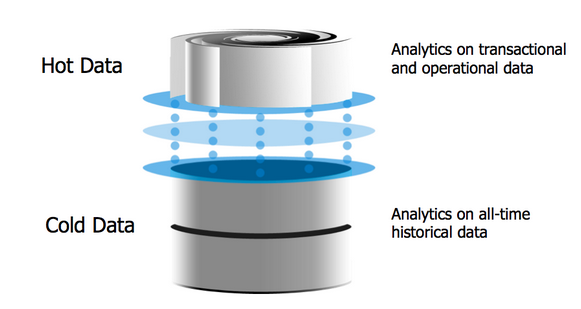
Instead of building another “old fashioned factory” by layering many systems on top of Hadoop, you can simplify and streamline your data processing by utilizing in-memory database technologies that are directly accessed via standard ANSI-SQL. Hot data resides in-memory while cold data resides in Hadoop or a columnar store. To address the complexity and volume of incoming disparate data, SingleStore now supports native JSON objects and standards based ODBC/JDBC/Hadoop connectors, allowing organizations to process both structured and semi-structured data together in a common database. Combined with commodity X86 scale-out architectures, the SingleStore in-memory solution provides the capabilities to service both today’s and tomorrow’s Big Data workloads economically.
Using the advertising sector as an example, ad-tech professionals are not just dealing with Big Data… these teams are faced with “ungodly” data volumes and velocities. Customers require the ability to ingest 500,000,000 events/hour while concurrently processing real-time analytical workloads in support of monetization and bidding engines. SingleStore has deployed several reference architectures of our scale-out in-memory database that can significantly help reduce the complexity of managing multi vendor solutions for real-time analytics or processing.
While the Hadoop ecosystem changes gradually with tweaks atop its foundation, evolution progresses with “punctuated equilibrium.” Think dinosaurs and mammals, for example. When it comes to database systems, in-memory technology is exactly the disruptive catalyst that takes a field by storm and can revolutionize your own business overnight. If you agree that waiting sucks, it’s time to join the real-time revolution with SingleStore.




