
This post originally appeared on the Myntra Engineering Blog.
Learn how Myntra gained real-time insights on rapidly growing data using their new processing and reporting framework.
Background
I got an opportunity to work extensively with big data and analytics in Myntra. Data Driven Intelligence is one of the core values at Myntra, so crunching and processing data and reporting meaningful insights for the company is of utmost importance.
Every day, millions of users visit Myntra on our app or website, generating billions of clickstream events. This makes it very important for the data platform team to scale to such a huge number of incoming events, ingest them in real time with minimal or no loss, and process the unstructured/semi-structured data to generate insights.
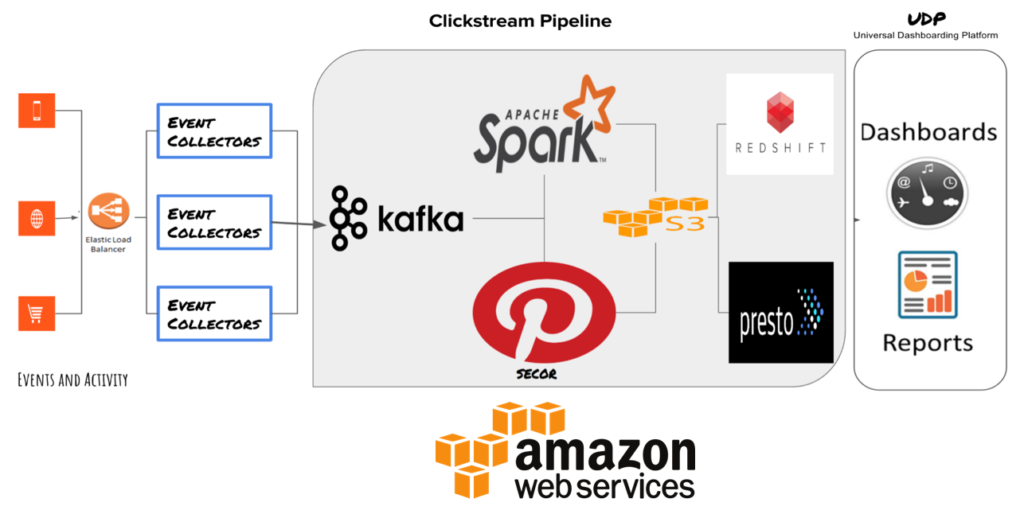
We use a varied set of technologies and in-house products to achieve the above, including Go, Kafka, Secor, Spark, Scala, Java, S3, Presto and Redshift.
Motivation
As more and more business decisions tend to be based on data and insights, batch and offline reporting from data was simply not enough. We required real-time user behavior analysis, real-time traffic, real-time notification performance, and other metrics to be available with minimal latency for business users to make decisions. We needed to ingest as well as filter/process data in real-time and also persist it in a write fast performant data store to do dashboarding and reporting on top of it.
Meterial is one such pipeline which does exactly this, and includes a feedback loop for other teams to take action from the data in real time.
Architecture
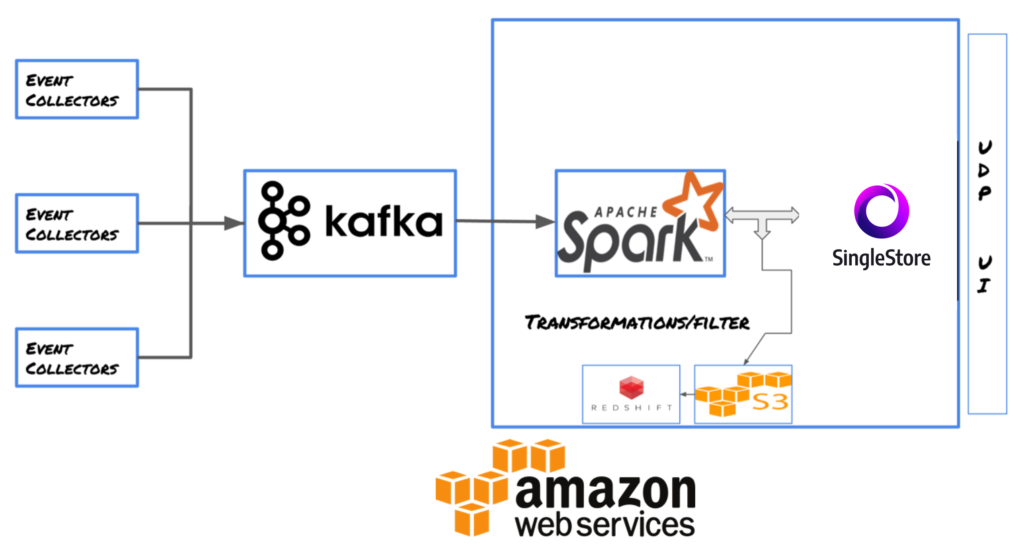
Meterial is powered by:
1. Apache Kafka
2. Data transformer, based on Apache Spark
3. SingleStore real-time database
4. UI built on React.js
Deep Dive
Our event collectors, written in golang ,sit behind Amazon ELB to receive events from our app/website. They add a timestamp to the incoming clickstream events and push them into Kafka.
From Kafka, the Meterial ingestion layer, based on Apache Spark streaming, ingests around 4 million events/minute, filters and transforms the incoming events based on a configuration file, and persists them to a SingleStore rowstore table every minute. SingleStore return results for queries spanning across millions of rows with sub-second latency.
Our in-house dashboarding and reporting framework (UDP: Universal Dashboarding Platform) has services which query SingleStore every minute and store the results in the UDP query cache, from where it is served to all the connected clients using socket-based connections.
Results are displayed in the form of graphs, charts, tables, and other numerous widgets supported by UDP. The same UDP APIs are also used by Slackbots to post data into Slack channels in real time, using Slack outgoing webhooks.
As all transactional data currently lies in Redshift, and reporting of commerce data with user data every 15 minutes is needed, Meterial also enables this ad-hoc analysis on data for our team of data analysts. Every fifteen minutes, data from SingleStore for that interval is dumped into S3, from where it is loaded to Redshift using our S3—Redshift extract, transform, and load (ETL) routines.
We selected Spark as our streaming engine because of its proven scale, powerful community support, expertise that we already had within the team, and easy scalability (with proper tuning).
To choose a real-time datastore for Meteriel, we did a proof of concept on multiple databases. We drilled down to SingleStore.
SingleStore is a high-performance, in-memory and disk-based database that combines the horizontal scalability of distributed systems with the familiarity of SQL.
We have seen SingleStore to support very high concurrent reads/writes very smoothly at our scale with proper tuning.
Currently we are exploring the SingleStore columnstore as the analytics database for our A/B test framework (Morpheus) and segmentation platform (Personify).
Sample UI Screenshots
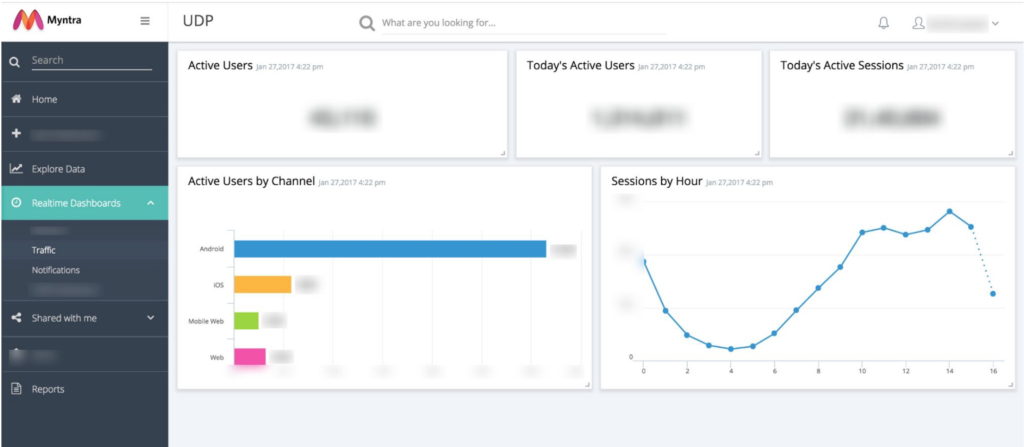
Traffic
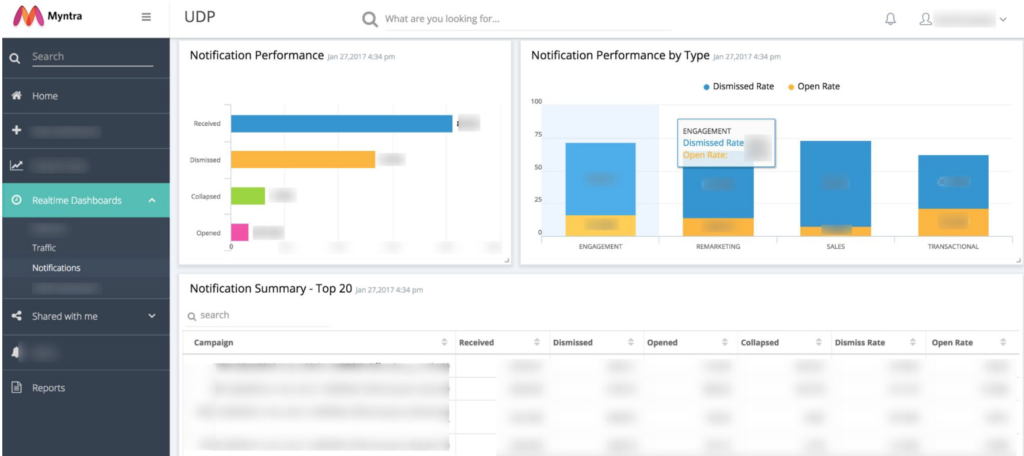
Notification
Future of Real-time Analytics at Myntra
Using real-time data with predictive analytics, machine learning, and artificial intelligence opens altogether new doors to understand user behavior, what paths and funnels leads to purchases, and more. Getting such information in real time can definitely help us boost results from our e-commerce, and take corrective actions as soon as possible, when something goes wrong. Given the importance of these results, we are constantly working on improving and enhancing Meteriel.





