Apache Spark has made a name for itself as a powerful data processing engine for transforming large datasets in a swift, distributed manner. After using Spark to complete such transformations, you often want to store your data in a persistent and efficient format for long-term access. The common solution of storing data in HDFS solves the issue of persistence, but suffers efficiency issues as a result of the HDFS disk-based architecture. The SingleStore Spark Connector solves both of these issues by providing an easy to use Spark API for reading from, writing to, and performing distributed computations with SingleStore. Using the connector, we leverage the computational power of Spark in tandem with the speedy data ingest and durable storage benefits of SingleStore.
Spark Connector Architecture
The SingleStore Spark Connector empowers users to achieve real-time data ingestion by connecting Spark workers directly with SingleStore partitions. This allows Spark to read and write from SingleStore in parallel, improving write performance. Utilizing this architecture Spark reads from SingleStore, allowing data to be imported from your SingleStore tables into your Spark job at lightning fast speeds. Once read in, you make use of Spark’s built in Graph and Machine learning libraries to perform additional computations on data persisted in SingleStore.
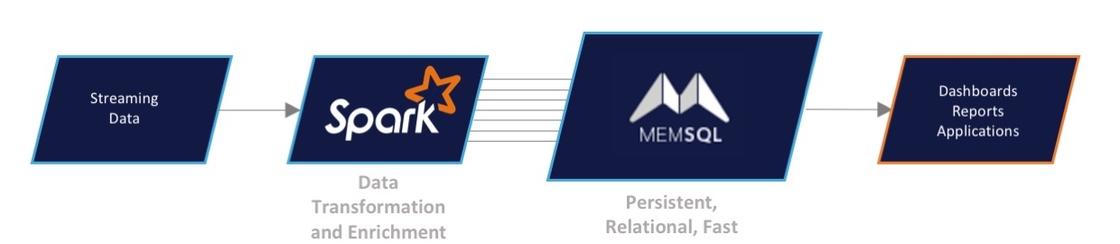
The SingleStore Spark Connector also supports “SQL Pushdown”, a feature that runs Spark SQL queries directly in SingleStore for more efficient calculations on large data sets. This translation is automatic, and requires no additional work or changes to existing Spark SQL commands.
As an example,ss.read.format("com.memsql.spark.connector").options(Map( "path" -> "db.table")).load().filter("id > 2")
will automatically be pushed down and run asSELECT * FROM db.table WHERE id > 2 in SingleStore.
API Basics
The SingleStore Spark connector is simple and lightweight, delivering powerful results with minimal effort. The API has three basic concepts:
SingleStoreContext.sql(sql_statement): A method for preparing SQL statements to be run in SingleStore.SingleStoreContext.sql(sql_statement).collect(): A method for executing these SQL statements in SingleStore.df.saveToSingleStore(): A method for persisting a Spark DataFrame to SingleStore.
To learn more about the SingleStore Spark connector, please see https://github.com/memsql/memsql-spark-connector
If you’d like to implement a similar spark connection in SingleStore feel free to setup a time: singlestore.com/demo
Get The SingleStore Spark Connector Guide
The 79 page guide covers how to design, build, and deploy Spark applications using the SingleStore Spark Connector. Inside, you will find code samples to help you get started and performance recommendations for your production-ready Apache Spark and SingleStore implementations.
Download Here