
In this case study, we describe how SingleStore powers wealth management dashboards – one of the most demanding financial services applications. SingleStore’s scalability and support for fast, SQL-based analytics, with high concurrency, mean that it’s well-suited to serve as the database behind these highly interactive tools.
Dashboards have become a hugely popular technique for monitoring and interacting with a range of disparate data. Like the dashboard in a car or an airplane, an effective dashboard consolidates data from many inputs into a consolidated, easy to understand display that responds instantly to both external conditions and user actions. SingleStore is widely used to power dashboards of many different kinds, including one of the most demanding: wealth management dashboards for families, individuals, and institutions.
Banks and other financial services companies work hard to meet the needs of these highly valuable customers. These users are highly desired as customers, and as such have high expectations and hold those who provide them services to a very high standard.
Data is the lifeblood of financial services companies. More than one bank has described themselves as “a technology company that happens to deal with money,” and many now employ more technology professionals than some large software companies. These financial institutions differentiate themselves on the basis of the breadth, depth, and speed of their information and trading support. So wealth management dashboards offer an important opportunity for these companies to provide the highest possible level of service and stand out from the competition.
The Wealth Management Opportunity
Technology allows wealth management divisions of financial services companies to offer a previously unheard-of level of high-touch, custom services to customers. Little more than a decade ago, much of the banking business was transacted by telephone and paper mail. Financial reporting, even for quite wealthy clients, was in the form of a quarterly statement, compiled and mailed several weeks after the close of a quarter.
The proliferation of digitized financial services has made the old way of doing things insufficient – and also offered an alternative. The financial options available to high net worth clients is almost unlimited, and the complexity of one well-off person’s or family’s portfolio may rival what was once considered normal for a medium-sized company.
Reporting and regulatory requirements have also exploded, especially since the financial crash of 2007-2009 – when the S&P 500, a broad and “safe” index of stocks, lost more than 50% of its value. Banks are responsible for everything they recommend to clients, as well as being held liable for some recommendations or warnings that they don’t offer. Some clients have successfully sued to recover a large portion of serious financial losses, if the financial institution(s) involved have made actionable mistakes or failures to disclose relevant information.
The size of both the opportunity, in terms of varied investment options, and the risk, from market losses, loss of customers, and legal and regulatory exposure, makes customers and those serving them both eager and anxious. Timely, accurate, and voluminous information helps both sides of this charged investment environment: providing accurate information to clients increases their opportunities for productive action and reduces the risk of misunderstandings and mistakes that can prove very expensive for all concerned.
Financial service providers combine “make” and “buy” approaches in delivering wealth management systems. At the “buy” end, companies like Private Wealth Systems deliver purpose-built wealth management systems. These can be provided to end clients directly or through white labeling under a financial institutions brand. The financial institution can endeavour to provide more or less added value on top of the third-party service.
At the “make” end, a financial services institution can create a service all its own – designing, architecting, building, and running it in-house. Such a service will have privileged access to a financial services company’s proprietary offerings, but must also provide information – if not trading capability – for externally controlled assets.
The Requirements and Technical Architecture of Portfolio Dashboard Platforms
Providing portfolio management opportunities to wealthy individuals occurs in two steps: the creation of a portfolio dashboard platform, and extending that platform to the individuals and families being served.
A portfolio dashboard solution can be thought of as a kind of command center for all the financial information flows available to anyone, anywhere in the world. A financial services company’s clients are likely, as a group, to be invested in nearly every possible kind of investment, in every country in the world. And their asset allocations are likely to shift continuously as they enact complex trading strategies to reduce risk and maximize reward.
So the platform itself must ingest all relevant financial data, with no lags or delays, and process it quickly. For instance, a customer may have purchased a financial services company’s index fund, made up of many individual investments. Calculations of the index’s current value and its risk exposures must be made accurately and instantly.
The platform must also serve its clients in multi-tenant fashion – the same software platform must support many customers at once, smoothly and efficiently, with no lags, delays, or barriers.
Traditional software architectures face many barriers in meeting demands of this kind. It’s become the norm, for example, for one system to bring data in – often in batch mode, imposing delays – and process it. An extract, transform, and load (ETL) process then “lifts and shifts” the data to a data warehouse system, which supports apps, business intelligence (BI) tools, and ad hoc queries. Note that the data warehouse is now separated from incoming data by a batch process and an ETL process – totalling many minutes, or even several hours, in a financial environment where competitive advantage is measured in fractions of a second.
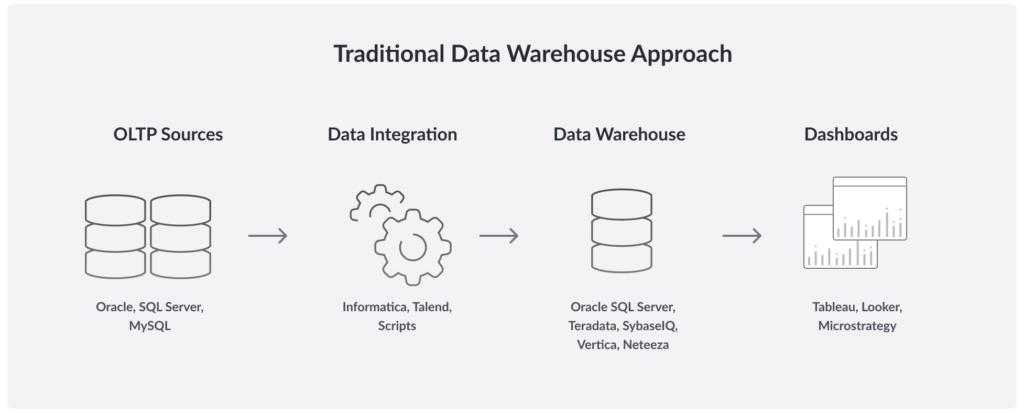
The Challenges of Operating Portfolio Dashboards Today
The goal of a system serving portfolio dashboards is to provide end-to-end real-time decisioning. Streaming data powers this capability, requiring data streams from a very wide range of reporting sources. The data is processed as it arrives and is immediately made available to users. Traditional systems are inherently unable to meet these requirements.
The technical requirements for a portfolio dashboard include:
- Fast, lock-free transactions. There can be no delays in, or barriers to, bringing incoming data into the system, while also ensuring precision and accuracy of the data.
- Fast, scalable data processing. Data may be normalized, calculated, merged, or combined to create output data streams.
- Fast query response. Specific queries – whether generated by an app, a BI tool, or an ad hoc user query – must be answered in tens of milliseconds. The number of queries that can be answered per second gates the performance of apps, BI tools, and analysts.
- High concurrency. Concurrency is a key requirement for any multi-tenant system. Given the market demands placed on portfolio dashboards, when markets shift, dramatically increased utilization of the dashboard occurs. Given the importance of the insights provided by the system during fast-changing market events, as many customers as reasonably possible must be supported, with no delays.
- SQL-compliant. Custom apps, BI tools, and ad hoc queries from savvy individuals nearly all use SQL as a lingua franca for communication across the boundaries of messaging systems and data stores. Non-SQL systems impose delays and heavy development burdens on app developers, BI tool providers, and end users.
Underlying all of these changes is a step change in the characteristics of the user base. First, the number of people who are wealthy has increased sharply. In addition, more and more of them are “digital natives” – people who either grew up in an always-online environment, or who have adapted rapidly to the new digital reality. These users expect constant access and constant interaction, whenever they feel the need for it. As a result, even the wealth management divisions of banks, where the number of clients numbers in the thousands, rather than the millions, are facing what IT providers used to refer to as “webscale” problems.
In addition, all of these requirements are only growing more stringent as new query profiles arrive, driven by predictive analytics, machine learning, and AI. These algorithms differentiate themselves, and their providers, by running more times per second against more streams of data, and providing results faster – further straining the platform.
The additional workload can push response times up for all users of a system, whether their own requirements are simple or demanding. And slow ingest or slow data processing can mean the difference between an actionable insight and watching an asset’s value crash, long seconds behind other market actors.
The Case of the Single Slow Query
In one telling incident, a high net worth individual became accustomed to the fast data updates and sub-second response times that were reliably provided by their wealth management dashboard. But then one query went awry. It took six seconds for the customer to get a response. Six… long… seconds.
The customer complained. His bank scrambled to find out what happened. They pinned down the problem, fixed it, and showed the customer how such a delay would never darken their day again.
But it wasn’t enough. A rival promised the customer uninterrupted access to their portfolio, with sub-second response times – 24 hours a day, seven days a week, forever. The customer changed banks.
The key to solving these problems is in a reliable high performance data architecture, followed by relentless tuning and quality control.
How To Improve Performance, Reduce Latency, and Eliminate Complexity with NewSQL
Wealth management systems are only one example – if a somewhat extreme one – of the increasing demands on messaging, data processing, and query responsiveness, as needed to support modern applications. For wealth management systems, the challenges involved are highlighted by the demands of the clients that consume these services, But versions of these challenges have arisen – and, in many cases, not been met – for years, across a wide variety of use cases.
One crucial underlying problem is that traditional relational database systems are mostly single-core. That is, their core process can only run on one machine at a time. So they can scale up – that is, they get faster if the single machine they run on is replaced by a more powerful one. But they can’t efficiently scale out; that is, they can’t quickly and cost-effectively use the power of multiple servers, yoked together, to deliver faster performance or support more concurrent users.
NewSQL is a new class of databases that combines the scalability of NoSQL with the schema and SQL support of traditional databases. This kind of software is hard to create, and the category is still maturing. Some of the leading NewSQL offerings are limited to a specific cloud provider, for instance. SingleStore is the leading database of its kind: a platform-independent, fully scalable, relational solution that fully supports schema and ANSI SQL.
Caching as a Limited Solution
Wealth management dashboards are one of the most intense examples of a problem that has plagued the database world ever since relational databases standardized around SQL in the 1970s and 1980s. These databases were relational, and fast for small and medium-sized data loads. But they were not horizontally scalable; at the core, performance was restricted by the capabilities of the most robust single server that can be brought to bear on the problem.
The companies that offered these database systems were largely unable to work past them. (Oracle’s RAC offering is a brave, but expensive and fragile, attempt to do so.) What the industry tried to offer, instead of a scalable solution, is in-memory caches. RAC is an example of a database provider offering a caching-based solution. Numerous third parties also offered caches to bolt onto existing, single-core database solutions.
Unfortunately, such caches bring with them several problems:
- Unexpectedly slow performance. The increasing demands of users lead to increasing numbers of cache misses. A cache miss is more expensive than a direct read from disk, with no cache at all. It doesn’t take too many cache misses to render a cache counterproductive.
- Response delays. Even the suspicion of a cache becoming stale leads to the cache being dumped and reloaded. This process causes a delay for all processing, again in excess of the time required for a direct read.
- SQL breakage. SQL queries that produce an optimized response from a disk-based system, or an even faster response from an entirely in-memory system, produce long waits or even fail when some of the answer is in the cache and some isn’t.
- Incorrect results. Caching creators face a tough trade-off between allowing a relatively small number of potentially incorrect results and frequently jettisoning cache contents in favor of a cache reload. It’s all too easy for these design choices, or unanticipated conditions, to lead to some number of incorrect results.
The answer to these problems is a system – and, in particular, a query processor – built from the ground up to make smart decisions about in-memory, on-disk, and cached data. Legacy database providers have not made the investments required for this kind of holistic solution. It’s been left to new relational database providers, described by the label NewSQL, to find new ways to offer a relational database that supports SQL and works flexibly with disk and memory.
Modernizing Wealth Management Dashboards with Kafka and SingleStore
A wealth management dashboard must incorporate many streams of data – structured data such as account records, time series data such as stock market updates, and unstructured data such as video feeds. And new feeds may need to be added at any time.
These requirements militate for a standardized messaging interface within the data architecture, and Kafka can provide this.
Kafka is now widely used as a messaging queue within data architectures, and it integrates well with SingleStore. SingleStore then interacts with a standardized input source, simplifying system design and reducing operational burdens.
Among the desirable attributes of Kafka that work well with SingleStore:
- Streaming data support. Kafka can be used in either asynchronous (batch) or synchronous (streaming) mode to accommodate stock position data, news, and valuable research data. SingleStore’s high performance supports both options well.
- Distributed. Like SingleStore, Kafka is distributed, so it’s scalable. As a result, Kafka can handle scale and bursts of data without incurring costly offline re-sharding or shuffling.
- Persistent. Kafka is resilient against data loss, with the ability to copy data into one or more stores before successful receipt of the data is acknowledged. SingleStore is also fully persistent, even for rowstore tables, making the “chain of custody” for data much easier to manage.
- Publish-subscribe model. Kafka can accommodate a wide range of data inputs (publishers) and data consumers (subscribers). SingleStore then sees a simplified range of inputs, as they’re mostly or entirely coming in through Kafka, and has a robust ability to support analytics outputs, due to its native support for SQL.
- Exactly-once semantics. Kafka can be used to guarantee that data is accepted into a Kafka pipeline once and only once, eliminating duplicates or incomplete data. SingleStore works with Kafka to help provide end to end exactly-once guarantees.
- “Source of truth.” Kafka’s attributes make it a good candidate as a source of truth for incoming data that may then be divided among other processes and data stores. SingleStore can ingest most, or all, of the data streams distributed in Kafka.
The wealth management use case is a good fit for SingleStore’s Pipelines feature. Data feeds from Kafka – or AWS S3, Hadoop/HDFS, and other sources – can be ingested with a simple Create Pipeline command. Ingest is scalable, distributed, and can be fed directly into a memory optimized rowstore, a disk optimized columnstore, or both at the same time, to deliver dramatic results in the millions of events per second.
The code to create a pipeline is quite simple. In this example, from a recent Kafka and SingleStore webinar, a pipeline is created to load tweets from Twitter into a table:
CREATE PIPELINE twitter_pipeline AS
LOAD DATA KAFKA “public-kafka.memcompute.com:9092/tweets-json”
INTO TABLE tweets
WITH TRANSFORM (‘/path/to/executable’, ‘arg1’, ‘arg2’)
(id, tweet);
START PIPELINE twitter_pipeline;
The combination of Kafka data pipelines and SingleStore’s Pipelines for data ingest make the architecture supporting the dashboard display very simple. (Even though the overall architecture of the system may be complex, with different data sources, each of which requires more or less processing.)
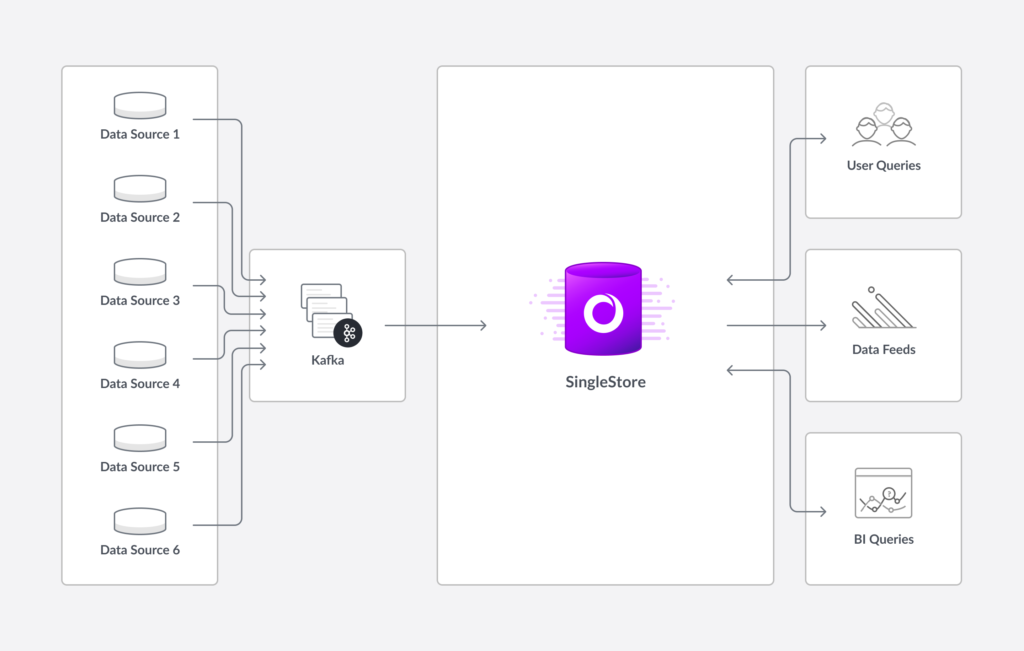
SingleStore, The Secret Ingredient for Reliably Fast Wealth Management Dashboards
SingleStore, along with Kafka pipelines, has been selected and implemented to power wealth management dashboards at a Top 10 US financial institution – one of the five such institutions that have already adopted SingleStore.
As in other implementations, SingleStore is paired with Kafka as a kind of messaging bus. Because SingleStore can handle all the inputs, process them as needed, and support a very wide range of user demands – with high concurrency – the SingleStore customer is able to cost-effectively provide an outstanding level of service.
Requirements are strict – stricter in the private wealth management area that supports wealth management dashboards than in the general banking part of the business. In the private wealth management area only, the customer is willing to overprovision systems in order to give SingleStore all the resources it needs for optimal performance.
In this environment, SingleStore must reliably meet query service level agreements (SLAs) of less than a quarter of a second, and these must be met while simultaneously ingesting batch loads of new data while under heavy and variable load. The customer also demands low variance – no single query can take much longer than the SLA, even if the average query time stays low.
SingleStore has not only met these strict requirements for several years running, the company is expanding its footprint within this Top 10 institution. At the same time, SingleStore adoption is growing right across the financial services industry.
If you are providing wealth management dashboards, similar financial services, or implementing other kinds of dashboards, this case study may demonstrate that SingleStore can serve as an important part of your solution.





![Building Real-Time Data Pipelines through In-Memory Architectures [Webcast]](https://images.contentstack.io/v3/assets/bltac01ee6daa3a1e14/blt8c64544168c8b0c1/63ea4b699c6cb020b6883ac4/featured_real-time-data-pipelines-webcast.jpg?auto=webp&width=320&disable=upscale)