A Fortune 50 company tried traditional SQL databases, then Hadoop, to manage financial updates company-wide. They finally found a successful solution by augmenting Hadoop with SingleStore.
Many companies today are straining to meet the needs for faster ad hoc analytics, dashboards, reporting, and support for modern applications that depend on fast access to the latest data – in particular, financial data.
Facing competitive and customer pressures, IT organizations must respond to a rapid increase in the volume of incoming data and the needs of the business to use this data for rapid decision-making, improving operations, and providing better customer experiences. These problems are especially severe in larger traditional companies that need to innovate.
Traditional relational databases, lacking scalability, have run out of gas for solving these problems. Many companies have turned to Hadoop, a NoSQL solution, to rapidly ingest data and move it to a data lake. However, the lack of SQL support and performance issues for queries – which affect ad hoc queries, reporting, dashboards, and apps – have made this approach unproductive for many.
A diversified Fortune 50 company approached SingleStore to help solve exactly this problem. The company first attempted to meet its analytics needs with an existing, legacy relational database. They then introduced a NoSQL solution based on Hadoop. The company found each of these solutions to be inadequate.
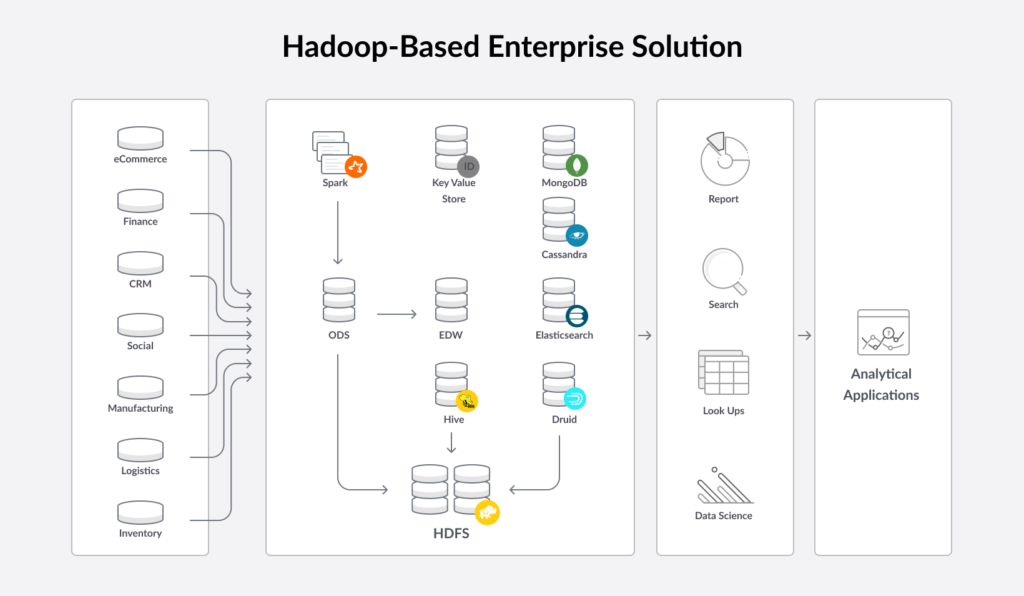
Ultimately, this company augmented Hadoop with SingleStore. They now use SingleStore to support an operational data store for company-wide data analytics, including access by executives. Hadoop still powers a data lake, which is used largely to support data scientists.
Detailed below is our customer’s journey and the benefits they saw from moving their core analytics processing to SingleStore. Included is a reference architecture for a combined implementation of SingleStore alongside Hadoop.
Displacing Hadoop for Analytics and Business Intelligence
The SingleStore customer in this case study needed fast analytics at the divisional level, as well as the ability to continually roll up data across the company for quarter-end reporting and communications to investors.
Originally, the company used a legacy relational database to drive analytics. Business analysts used business intelligence (BI) tools such as Business Objects and Tableau to derive insights. Analysts, knowledgeable in the needs of the business, were able to deliver real value to the company.
However, data volumes continued to increase, while more users wanted analytics access. Analytics users, from business analysts to top management, demanded greater responsiveness. And the analytics system needed to be ready to handle demands from machine learning and artificial intelligence software on both operational and legacy data.
The system that drove analytics was unable to keep up with the transaction speeds, query responsiveness, and concurrency levels required by the business. As a first attempt to solve the problem, the company augmented the legacy system with a Hadoop solution, with the final goal being to fully replace the legacy system with a Hadoop/Big Data solution.
Unfortunately, the move to Hadoop was unable to deliver for this customer – as it has for many others. Many data lake projects fail to make it into production, and others experience serious problems after implementation.
Hadoop is designed for unstructured data, and this causes many serious problems:
- Batch processing. With Hadoop, input data is processed in batches, which is time-consuming. The data available to analytics users is not current.
- Large appetite for hardware. Both batch processing and analytics responses take a lot of processing power, so companies spend a great deal to power Hadoop solutions.
- Governance and security challenges. Because Hadoop data is less organized than data in a relational database, it’s hard to identify and protect the most sensitive items.
- Complex system. Big Data solutions involve an entire ecosystem with many specialized components, which make for a difficult system to manage.
- Complex queries. Queries have to be written against complex data, with careful study of each data source needed.
- Slow queries. Queries run slowly, and users must either spend time up front optimizing them, or spend extra time waiting for results.
- No SQL. NoSQL eliminates the ease, speed, and business intelligence (BI) tool support found with SQL, preventing companies from getting maximum value from their data.
Queries, Sorted: Augmenting Hadoop with SingleStore
The company had two competing sets of needs. Data scientists wanted access to raw data, and were willing to do the work to transform, catalog, and analyze data as needed. Business analytics users (including the executive team), BI tools, and existing applications and dashboards needed structured data and SQL support.
By augmenting Hadoop with SingleStore, the company can meet all these needs at once. SingleStore is a massively-scalable, high-performance relational database. SingleStore is a leader in a new category of databases, commonly described as NewSQL.
As a leading NewSQL database, SingleStore offers a cloud-native, distributed architecture (details here). It combines the ability to handle streaming ingest, transactions, and analytics, including SQL support.
With SingleStore holding the operational data store, the company is once again able to unleash its business analysts on its most important data. The same operational data store is available for executive queries and financial reporting.
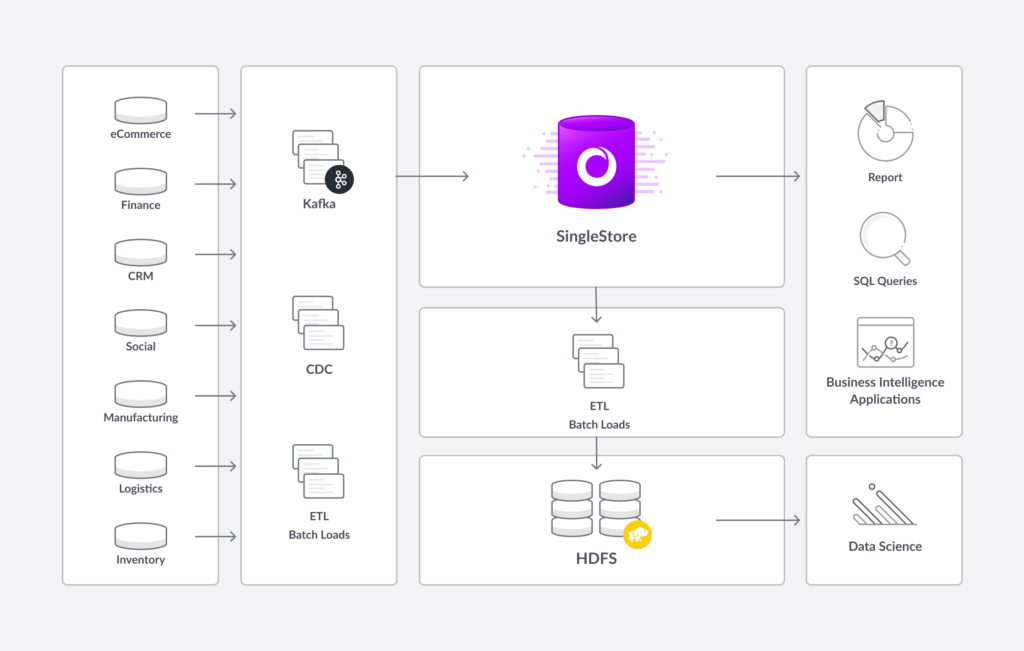
Hadoop and HDFS are still used, but as a data archive, to support audits, and as a data lake for use by data scientists. (Who, of course, use the operational data store as well.) Work in the data lake yields valuable results, while the operational data store supports the ease of access, efficiency, and rapid response needed by the rest of the business.
Choosing an Ingest Strategy
With SingleStore used as an operational data store for real-time analytics, and Hadoop as a data lake, the customer had three choices as to how to ingest data:
- SingleStore-first ingest. The customer could replicate the data, using change data capture (CDC) from some sources and SingleStore Pipelines from others. Some or all of the data could then be extracted and loaded to Hadoop/Hive.
- Simultaneous ingest. The customer could replicate the data to both the targets in parallel. In either case, some data could be discarded on ingest, but the default choice for any incoming data would be to go to both databases at once.
- Hadoop-first ingest. The customer could bring all data into Hadoop in a batch operation, then transfer all of the data, or a subset, to SingleStore as needed.
Each approach has either advantages or disadvantages.
| Advantages | Disadvantages | Use Case | |
|---|---|---|---|
| SingleStore-first | ETL, CDC and SingleStore Pipelines stream data; analytics run against live data | Fast analytics critical; SingleStore needs most or all of the data | |
| Simultaneous | Added complexity, as both streams need to be managed as primary | Fast analytics critical; both SingleStore and Hadoop need most or all of the data | |
| Hadoop-first | Major delay for SingleStore ingest & analytics, happening after Hadoop batch ingest | Many users try this, only to realize they need an operational data store w/SQL |
The SingleStore-first approach gets you analytics against live data,
while other approaches add complexity and delays
The customer chose direct ingest to SingleStore. Data is also sent to an operational data store, then batched to Hadoop Their whole reason for using SingleStore was to speed up analytics, so putting Hadoop first – leading to delays in data getting into SingleStore – was a poor option. Because both SingleStore and Hadoop would be getting most of the data, and to simplify troubleshooting if a problem occurred, the customer decided to keep SingleStore and Hadoop ingest separate.
With SingleStore, the customer has the same advantages that customers have long sought from a traditional data warehouse: direct access to data for faster analytics performance. A traditional data warehouse requires pre-aggregation of data, where this is needed less, or not at all for SingleStore. And SingleStore adds advantages of its own: better performance than traditional data warehousing products and the ability to query live data.
SingleStore compares even more positively to the customer’s former Hadoop-based data warehouse-type implementation. Hadoop is not designed to support ad hoc queries and dashboards. It lacks SQL support, meaning that it can’t be used easily with most business intelligence (BI) tools, and it can’t be queried conveniently by business analysts and others who want to use SQL for ad hoc queries, not write a computer program.
| Hadoop | SingleStore | |
|---|---|---|
| Performance | Poor | Excellent |
| Concurrency | Poor | Excellent |
| Queries | Custom | SQL ad hoc queries & BI tools |
| Accessible by | Data scientists | Business analysts, executives, data scientists |
| Governance support | Poor | Excellent |
Hadoop lacks key analytics features supported
by SingleStore, especially SQL support
Analytics with No Limits
The company’s use of data is now on much firmer footing. Thousands of BI tool users and more than five hundred direct users, spread across roughly a dozen divisions, use SingleStore, BI tools, and SQL queries for all their analytics needs. Many terabytes of data are accessible to users across the globe. Analysts and other users work with up-to-date data, at high concurrency, with fast query performance.
Analytics work has dramatically improved:
- From batch mode to near-real-time: Analytics now run against near-real-time data. Information that used to take days to arrive now takes minutes.
- From spreadsheets to BI: This Fortune 50 company (like many) was doing much of its core analytics work by exporting data from Hadoop into Excel spreadsheets. With SingleStore, the full range of BI tools is now available as needed.
- Instant access for live queries: Using SQL, any analyst can make any query, anytime, and get results quickly. In combination with BI tools, this supports the kind of interactive probing that leads to real, timely, actionable insights.
- Executive accessibility: There’s now a single source of truth for investor reporting. The CEO and senior executives have direct access to insight into operations.
| Hadoop + Hive | SingleStore | |
|---|---|---|
| Processing mode | Batch | Real-time |
| Analytics tools used | Excel spreadsheets | Wide range of BI tools |
| Access mode | Custom queries | SQL queries |
| Executive accessibility | Inaccessible | Direct |
SingleStore has improved analytics
performance and accessibility
In addition to the outcomes, the deployment process and operations for SingleStore are also considered a success for the IT team:
- Time to go live was less than three quarters.
- Deployment across the company was managed by a single team of just two people.
SingleStore runs faster on a six-node cluster than Hadoop + Hive did on fifty nodes.
SingleStore offered superior total cost of ownership, with operational savings more than offsetting licensing costs for SingleStore. - As impressive as it is, this use case only shows part of what SingleStore can do. The same company is now implementing SingleStore in a different use case that takes advantage of a wider range of SingleStore’s capabilities.
Spotlight on Pipelines
SingleStore’s Pipelines capability makes it uniquely easy to ingest data. With Pipelines, SingleStore streams data in from any source and transforms it “in flight”, then loads it rapidly into SingleStore. The traditional extract, transform, and load (ETL) process is performed on streaming data in minutes, rather than on batched data in a period of hours.
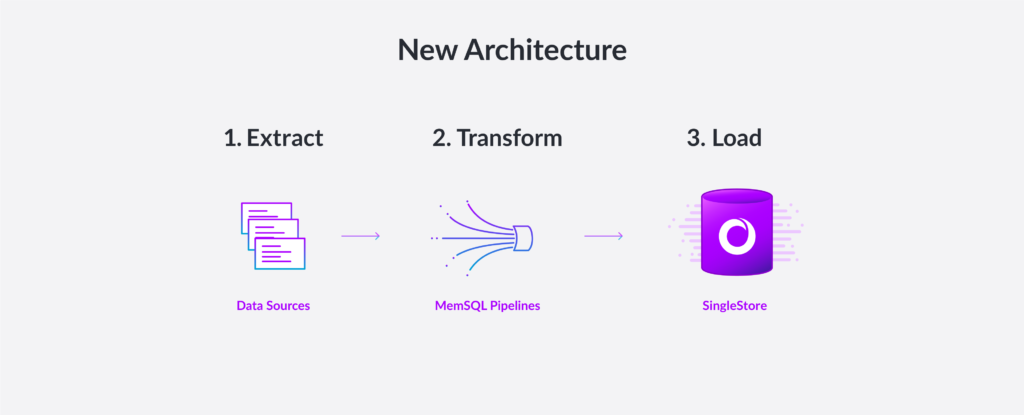
To extend the Pipelines capability, SingleStore has introduced Pipelines to stored procedures. Stored procedures add flexibility and transactional guarantees to the streaming capabilities of Pipelines. Hadoop and HDFS, by contrast, ingest data in a slow batch process, with little transformation capability, and no access to stored procedures.
Conclusion
The Fortune 50 company described here is facing the same challenges with its use of data as most other enterprises worldwide. SingleStore has allowed them to provide better access to data, to more people across their company, at a lower cost than other solutions. The results that they have achieved are encouraging them to increase their use of SingleStore for analytical, and also for transactional use cases. The same may be true for your organization.
For more discussion about the use of SingleStore with Hadoop, view our recent webinar and access the slides. And consider trying SingleStore for free today.